
April 15, 2026
RIP Commercial OCR. An Open-Source Model Just Topped Every Benchmark.
A 4B parameter model from a Brooklyn startup is beating GPT-4o and Gemini across 90 languages. Although OCR is not my domain, this one…

By Sumit Pandey
6 min read
A 4B parameter model from a Brooklyn startup is beating GPT-4o and Gemini across 90 languages. Although OCR is not my domain, this one fascinated me.
OCR is not my field. I spend most of my time in machine learning and healthcare AI. But every now and then something crosses my feed that makes me stop and pay attention.
If you cant read the article becuase of paywall then please click here
A few months ago, a developer ran one of Srinivasa Ramanujan's handwritten letters from 1913 through an open-source OCR model. A letter with faded ink, cramped mathematical notation, and 111-year-old handwriting that most modern tools would completely choke on.
The model read it clearly. It preserved the layout, the math notation, and even the faint ink details.
The model was Chandra, built by a small Brooklyn startup called Datalab. Most OCR tools would have given up on that letter. Chandra treated it like any other page.
That got my attention. Then Datalab released Chandra OCR 2. And the benchmarks got absurd.
What Chandra OCR 2 Actually Is
Datalab just open-sourced Chandra OCR 2: a 4 billion parameter model that converts images and PDFs into structured Markdown, HTML, or JSON while preserving the original layout.
The creator is Vik Paruchuri. You might know him from Marker and Surya, two open-source document processing tools with about 50,000 combined GitHub stars. Chandra is what happens when someone who has been quietly solving document intelligence for years decides to go all-in on a single end-to-end model.
And the benchmarks are not subtle.
The Numbers That Made Me Stop Scrolling
On the independent olmOCR benchmark (maintained by AllenAI, not Datalab), Chandra OCR 2 scored 85.9%. That is state of the art. It beat every model tested, including the ones backed by billions of dollars in compute.For context: GPT-4o scored 69.9%. That is a 16-point gap.
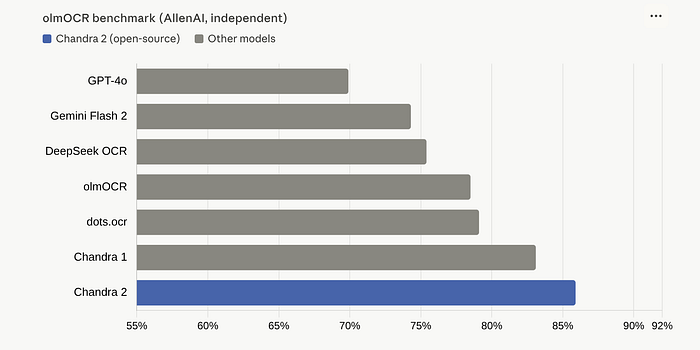
But here is where it gets really interesting. Datalab also built their own multilingual benchmark covering 90 languages. The results:
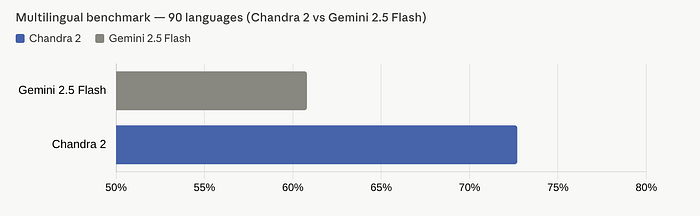
Chandra OCR 2 scored 72.7%. Gemini 2.5 Flash scored 60.8%. That is not a marginal improvement. That is a 12-point lead across 90 languages.
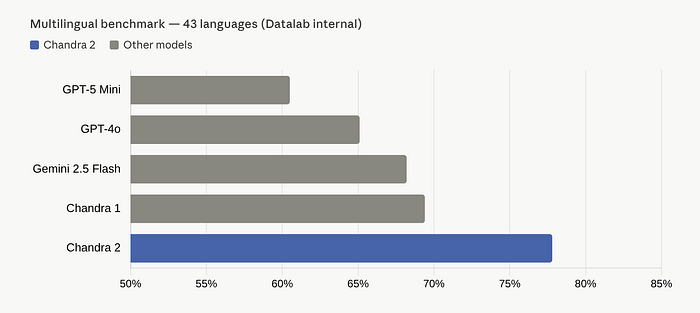
On the 43 most common languages, the gap widens further: Chandra hit 77.8%, while GPT-5 Mini landed at 60.5%. Some individual language improvements are staggering: Kannada jumped 42.6 points, Malayalam gained 46.2 points, Telugu improved by 39.1 points compared to Chandra 1.
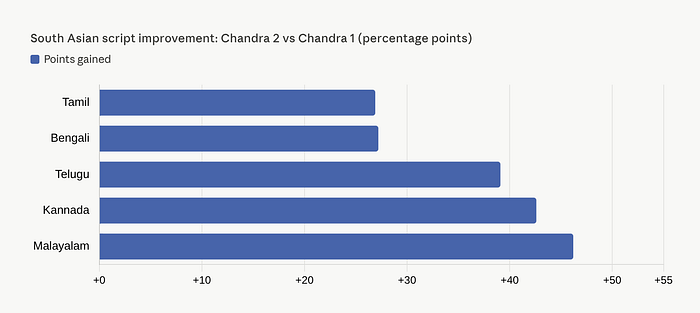
If you work with South Asian scripts, those numbers are not just impressive. They are transformational.
What It Actually Handles
Most OCR tools can read clean printed English text reasonably well. That was never the hard problem. The hard problem is everything else.
Chandra OCR 2 handles what most tools cannot: tables with complex layouts and nested headers, mathematical notation (including handwritten math on old scans), forms with checkboxes preserved in the output, multi-column documents with correct reading order, images and figures extracted with auto-generated captions, and even flowcharts converted to Mermaid diagram format.
That last one caught me off guard. You feed it a document with a process diagram, and it outputs a Mermaid flowchart. For a model that is supposed to just "read text," that is a different kind of ambition.
Smaller, Faster, Better
Here is the part that surprised me most. Chandra OCR 2 is a 4B parameter model. Chandra 1 was 9B.
They cut the model size by more than half and still improved accuracy across every single category. The olmOCR score went from 83.1% to 85.9%. The multilingual average jumped from 69.4% to 77.8%. Throughput doubled.
On a single NVIDIA H100 GPU, it processes about 2 pages per second in real-world usage. You can run it locally via HuggingFace with a simple pip install chandra-ocr[hf]. Or deploy remotely through a vLLM server with Docker for production workloads.
pip install chandra-ocr
# With vLLM (recommended)
chandra_vllm
chandra input.pdf ./output
# With HuggingFace
pip install chandra-ocr[hf]
chandra input.pdf ./output --method hfpip install chandra-ocr
# With vLLM (recommended)
chandra_vllm
chandra input.pdf ./output
# With HuggingFace
pip install chandra-ocr[hf]
chandra input.pdf ./output --method hfFive lines. That is it. No API keys. No cloud dependency. No per-page pricing.
The Bigger Picture
Let me zoom out for a second.
OCR has always been one of those problems that sounds solved but is not. Tesseract has been around for decades. Google Document AI exists. Azure has its own thing. Every major cloud provider offers some version of document extraction.
And yet, anyone who has actually tried to build a production pipeline on top of these tools knows the pain. The edge cases are endless. The failures are silent. A table that renders fine in one scan breaks completely in another. Handwriting recognition works on English cursive but falls apart on Devanagari.
What Datalab did with Chandra is take a fundamentally different approach. Instead of a pipeline that segments pages into blocks, processes each block separately, and stitches them back together, Chandra uses full-page decoding. It sees the entire page at once. That is what gives it layout awareness, and it is why the output quality is so much higher.
This matters beyond just OCR. If you are building RAG pipelines, the quality of your document parsing is the ceiling for everything downstream. Bad OCR means bad chunks, which means bad retrieval, which means your chatbot confidently gives wrong answers. Chandra does not fix your retrieval logic. But it removes one of the biggest failure points before retrieval even begins.
The Honest Caveats
I would not be writing this in good conscience without the caveats. First, the licensing. The code is Apache 2.0, fully open. But the model weights use a modified OpenRAIL-M license: free for research, personal use, and startups under $2 million in funding or revenue. If you are a larger company or want to use it competitively with Datalab's own API, you need a commercial license. That is not "open-source" in the purest sense. It is open-weights with restrictions.
Second, the benchmark. Datalab created their own multilingual benchmark because no good public one existed. That is reasonable, but it also means they are grading their own homework on the multilingual front. The olmOCR benchmark is independent, and Chandra dominates there. But I would love to see more third-party evaluations on the multilingual side.
Third, the GPT-4o comparison deserves a footnote. The olmOCR benchmark uses fixed prompts, meaning GPT-4o's score reflects its performance without optimized prompting. With custom prompts, GPT-4o likely performs better than 69.9%. The gap is real, but it may not be as dramatic in every real-world scenario.
Fourth, handwriting recognition. Chandra scores well on handwritten notes (around 90.8%) but drops significantly on complex handwritten forms (around 50.4%). If structured form extraction from handwriting is your primary use case, test carefully before committing.
Why This Matters
Datalab is a Brooklyn-based startup founded in 2024. They raised $3.5 million in seed funding from Pebblebed, a fund started by former founding members of OpenAI and FAIR. Anthropic is listed as a customer on their website.
They are not a trillion-dollar lab. They are a small team that trained a 4B parameter model and beat every frontier model on the most widely accepted OCR benchmark.
That is the part I keep coming back to. Not because it is a David-and-Goliath story (though it is). But because it shows that in specialized domains, smaller focused models can still outperform general-purpose giants. The frontier labs are building models that do everything. Datalab built one that does one thing exceptionally well.
For anyone building document processing pipelines, RAG systems, or any workflow that needs to reliably extract structured information from messy real-world documents: Chandra OCR 2 is the new baseline.
All model weights are open. The code is on GitHub. There is a free playground if you want to try it without installing anything.
Go test it on your worst PDF. The one that breaks everything else. That is where Chandra earns its benchmark scores.
If you found this useful, follow me here on Medium for more honest breakdowns of tools that actually work. I write about machine learning, AI tools, and the messy reality of building data products.