

"Can you check my SQL?"
"Which table has the livestream data?"
"How do I calculate GMV again?"
At Whatnot, our data scientists were drowning in these sorts of questions. At the same time, leaders asking them might wait hours for answers that should take seconds. In 2025, we shipped an LLM-powered Slack bot to break this tension.
The results were immediate: the help channel converted from "ask a data scientist" to "ask the bot" overnight. Since launch, employees have had over ten thousand data questions answered by AI systems, with most answered in tens of seconds and all deflected from the data team's queue. Widespread adoption (and proliferation outside of Slack) has revealed limitations that have forced us to rethink how we architect data access for AI systems.
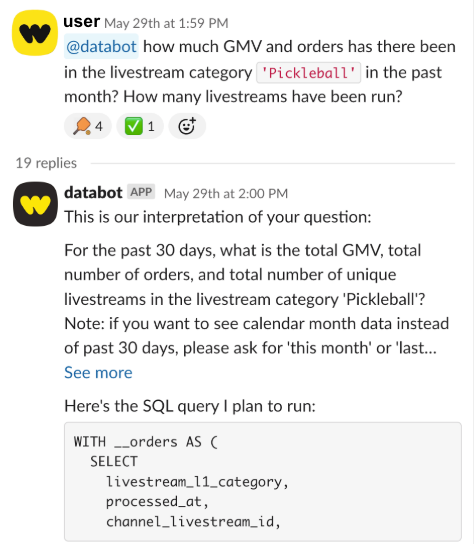
Below, we share a few of the key lessons learned and how we plan to make our team even faster in the coming year.
Lesson 1: Flexibility vs. trustworthiness is the key design tradeoff
Data experts are valued because they are both trustworthy and flexible: ask them a question, and you can get back not just an answer but their confidence in it as well. LLMs, on the other hand, are famous for being confidently clueless. The first question facing a team employing them for data science work is, "How risky is a wrong answer?"
It's not a new question: every data product provides consumers a degree of flexibility, whether that's almost none (public metrics) or a significant amount (raw or unstructured datasets). What's new is that, with AI interfaces, teams can control the consumer's full aperture.

Many teams default to maximum flexibility by giving the LLM access to everything and letting it figure it out. If the goal is to replace experts, this is backwards. We went the opposite direction: locked down access to pre-vetted datasets, accepting that we'd miss around 30% of questions. No data is often better than wrong data, since inaccuracies erode trust faster than unknowns.
To do this, we:
- Reduced scope to solving SQL support questions, like "How do I find out how many vinyl records were sold last month?"
- Limited the LLM agent to only data scientist-endorsed metrics, codified through Snowflake semantic views
- Directed users to ask questions in public forums until we had confidence to expand
This is a conservative approach, but it had two significant benefits: data experts could easily review questions and answers being asked, and address issues or inaccuracies as they arose. It also created a feedback loop: a user asked a question, it either delivered an answer or didn't, and if it didn't, a data expert could identify the gap and update the agent's access. In other words, it shifted support from primarily supporting users to primarily supporting context definition.
Lesson 2: Context engineering is more than data documentation.
When an employee asks, "How many Labubus were sold last month?" the system needs to do a couple of things:
- Decide on the right table(s) with the data
- Select the correct columns for "sold items" and "last month."
- Create the correct set of filters to match "Labubu" items
Agents are terrible at guessing and get worse as the scope increases. They need explicit context to be fast and consistent.
There are multiple ways to inject this information into an LLM's context window, but semantic views have emerged as among the best for SQL generation. Semantic views reduce the acceptable space required for joins, calculations, and outputs. In other words, they force users to make explicit facts that were previously implicit about table relationships and metric definitions, and defer the aggregation steps to runtime.
In our implementation, users tagged our @databot user in Slack, and it conveyed the query to Snowflake's Cortex Analyst service. This service then selected from a set of semantic views mapped to trusted data assets managed in dbt, generated a SQL query to answer the question, then ran and returned the result set to the user.
A semantic view definition in our implementation might look like this:
{{ config(materialized='semantic_view') }}
TABLES (
orders AS {{ ref('fact__orders') }} PRIMARY KEY (order_id)
, livestreams as {{ ref('dim__livestream') }} PRIMARY KEY (livestream_id)
)
RELATIONSHIPS (
orders_to_livestreams as orders (livestream_id) REFERENCES livestreams (livestream_id)
)
DIMENSIONS (
orders.processed_at as processed_at
comment = 'Date and time the order was processed in UTC. Use this for date filters.'
, orders.status as status
comment = 'The status of the order, such as completed, processing, cancelling, cancelled, ask_pending, or failed.'
, livestreams.livestream_title as livestreams.livestream_title
comment = 'Title of the livestream the order was made on'
)
METRICS (
orders.total_gross_merchandise_value as SUM(gmv)
with synonyms = ('gmv')
COMMENT = 'The total GMV generated from all orders in USD.'
)Semantic views can do heavy lifting in mapping business concepts like "gross merchandise value" to specific SQL expressions. Still, other categories of context have a significant impact on results, such as domain context, reporting conventions, and example values.
This last one was a killer. Without record-level context, the system may look for "labubu", "Labubu items", "labubus", or "pop_mart", or write custom matching criteria against listing descriptions. If the result set is empty, it has to decide whether that's a real no result or a failure of the requirements. Frequently, this is the difference between an answer being right or wrong, and it adds to the time and money required for processing.
Each AI system will have its own ways of addressing this. In our case, we set up Cortex search services to index the actual values for specific fields, which can be added to the semantic view to accelerate and improve the query results. But the bottom line is that simply adding column documentation is not enough. Context engineering is an active process that has a direct impact on measurable results. The type of context you need to provide is going to depend on the AI systems, the interfaces that you're using, and the breadth of questions you want to support.
Lesson 3: Data modeling is still the hard part.
When you funnel hundreds of questions through a single interface, something clarifying happens: you see what's modeled well and what isn't. In our semantic view approach, unmodeled data simply couldn't be accessed: users simply got no answer. But as we expanded coverage, new failure modes emerged: queries that hung indefinitely, inconsistent table selection where the agent couldn't decide between two plausible sources, and colliding metric definitions that produced different numbers for the same question.
Every failure traced back to data modeling fundamentals. What's the source of truth for revenue metrics? How do we make those queries performant? How do we handle changes to definitions as the business evolves? These are familiar problems for data teams, since business intelligence tools have wrestled with them for decades.

AI interfaces don't solve these problems directly; they expose them. In practice, we found that instead of responding to queries, the data team had to create and maintain source of truth views and monitor incoming questions to update the bot's effectiveness. Making this scalable meant developing a production-grade life cycle development process.
One improvement we made was to integrate semantic view management into our existing dbt lifecycle through custom materializations. This allowed semantic views and search services to be created and versioned alongside their underlying tables. Snowflake now supports its own custom dbt materialization, but the lesson stands: semantic views need the same development discipline as any production code, including version control, testing, monitoring, and clear ownership.
Data science is evolving, not evaporating
The biggest lesson is that LLMs don't replace data scientists. Instead, they expose how critical they are and give them more bandwidth to do the highest-leverage work. To get there, though, data teams will need to shift their views on "good documentation" from a cherry-on-top feature to a production requirement with measurable impact. The work looks different from building reports and dashboards, but it's an evolution rather than a wholesale change.
The field is changing fast, too, and we're seeing different use cases require different tradeoffs. Seller-facing analytics tools, internal developer tools, and operational troubleshooting tools all require data access — but radically different levels of trustworthiness and range. We're exploring tiered architectures in which curated semantic layers handle critical or common queries, while broader table access serves exploratory use. Agentic architectures that query, validate, and report promise to further simplify context management.
We expect the core lessons shared above will persist as the tools evolve, though, and organizations that find ways to tackle them in a scalable manner are positioned to make their data teams vastly more impactful.