
In May 2023, I asked ChatGPT to build me a small application — a "toil tracker" to log the repetitive operational work that defines an SRE's day. The result was 360 lines of Python, a basic desktop window with a few buttons, and a workflow that involved copy-pasting code snippets between a browser and a text editor for the better part of an afternoon.
Almost exactly three years later, I gave the same brief to Claude Code. I sat back and watched an AI agent scaffold a full web application with a real database, interactive charts, and an automation-scoring system — in a single session, with no copy-pasting and no manual debugging. It even fixed its own bugs in real time, by reading the error logs the dev server produced. That code can be seen here: https://github.com/administrativetrick/SRE_Toil_Tracker/tree/main
If you work in cybersecurity, automation, or AI — or you've been wondering whether "vibe coding" is a serious productivity shift or just a marketing term — this is a useful natural experiment. Same prompt, same goal, three years apart. The diff is staggering.
What "toil" is, and why it's not just an SRE problem
The term comes from Google's SRE handbook. Toil is operational work that's manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly with service growth. Rotating a TLS certificate by hand. Restarting a hung worker for the fifth time this week. Manually adjusting a Kubernetes worker pool when traffic spikes. Granting one-off access. Generating a weekly status report.
If you're in security, this should sound familiar. SOC analysts triage the same false-positive alert categories every shift. Threat hunters re-run the same enrichment queries against new IOCs. Compliance teams chase the same evidence trails every quarter. The label is different — alert fatigue, ticket churn, audit prep — but the substance is identical: time you'll never get back, doing things a machine should be doing.
The whole point of tracking toil is to find out which pieces of it are most worth automating. A weekly task that takes 90 minutes and could be scripted in an afternoon is a much better automation target than a 30-minute task you do once a quarter. But almost nobody actually measures this, because the meta-work of measuring toil is, itself, toil.
That's the app I asked both AIs to build.
The 2023 version
When ChatGPT 3.5 took a swing at this in May 2023, what came out the other end was:
- A Python script using Tkinter for a desktop GUI.
- About 360 lines of code, accumulated by asking for one feature at a time.
- An in-memory list of tasks, pickled to a file when the app closed.
- A user experience that looked like a CS-101 project.
The workflow was the real story. I'd describe a feature in chat. ChatGPT would respond with a code block. I'd copy that block into a .py file, hit save, run the script in a terminal, paste any errors back into the chat, and wait for a corrected snippet. Repeat until something resembled the request. The model had no idea where its code was actually living. It couldn't run anything. It couldn't see error messages unless I retyped them.
It worked, eventually. It was also brittle, ugly, and — critically — single-user, single-machine, and only mine. The 2023 article ended on cautious optimism: "AI can build small useful things, and that's interesting." Three years on, "small useful things" no longer covers it.
The 2026 version
Same prompt, fresh tools. I described the goal — a toil tracker — to Claude Code, an agentic coding environment, and answered two clarifying multiple-choice questions about tech stack and scope. Twenty-five minutes later, I had:
- A full Next.js 16 web application running on my machine on port 3000.
- A real SQLite database with foreign keys, indexes, migrations on boot, and a transactional seed script.
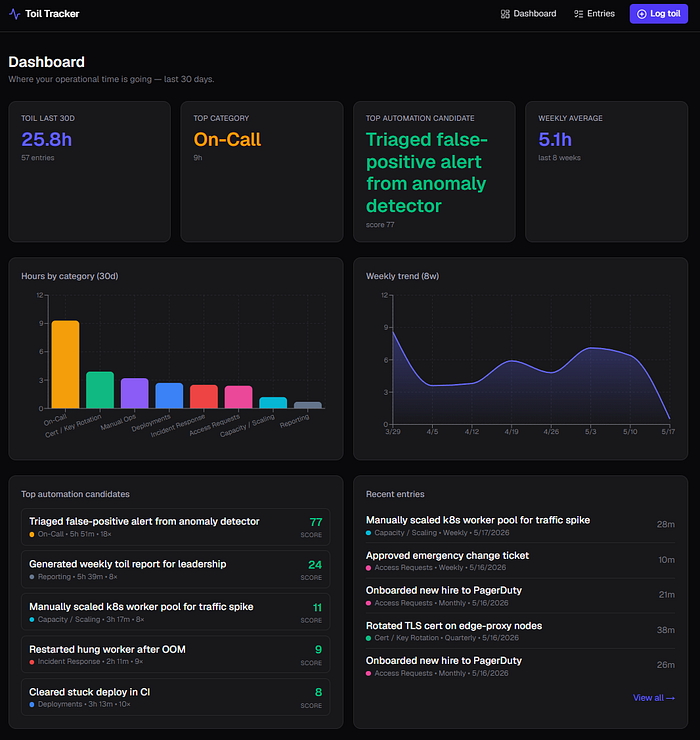
- A dashboard with four KPI cards, a bar chart of hours by category, an eight-week trend area chart, a ranked list of top automation candidates, and a recent-activity feed.
- A filterable entries table, a category-tagged log form with an automation-potential slider, and full create/read/update/delete operations behind server actions.
- 105 realistic SRE toil entries seeded across two months — cert rotations, manual scaling, on-call pages, DLQ replays, ad-hoc Cribl reloads — so the dashboards have real data the moment you open them.
The most interesting feature is one I never explicitly asked for. The model proposed an automation-candidate score that ranks each recurring task by how much it's costing you and how feasible the automation looks:
score = (total minutes × frequency multiplier × automation_potential / 5) / 60A weekly 25-minute manual scaling task with an automation-potential rating of 4 out of 5 scores higher than a quarterly 90-minute task that's rated only 3. The math is trivial. Surfacing it as the headline number on the dashboard is the kind of design move I'd expect from a senior product engineer, not from a tool that compiles JSX.
The workflow diff
This is where the real change shows up. Seven concrete differences between 2023 and 2026, same project both times:
Where the code lives.
- 2023: I copy-pasted code blocks from a browser into files by hand.
- 2026: The agent writes the files directly. I never opened a file manually.
Running the application.
- 2023: I ran the script, watched it crash, and pasted the traceback back into the chat.
- 2026: The agent started the dev server itself, polled localhost, and read its own logs.
Fixing a render bug.
- 2023: I screenshotted the error and described what I was seeing.
- 2026: The agent probed routes with curl, read the dev-server output, identified the broken file, and patched the source — without being asked.
Stack decisions.
- 2023: Whatever ChatGPT defaulted to. I got Tkinter because that's what came out.
- 2026: The agent asked first, with multiple-choice options and trade-offs for each: Next.js + SQLite, FastAPI + HTMX, or a faithful Tkinter rebuild. I made the call.
Database schema.
- 2023: "Save the list to a file" — a pickled Python object, no schema.
- 2026: Real SQL DDL with indexes, foreign keys, a migrations-on-boot helper, and a transactional seed script.
Project layout.
- 2023: One Python file, 360 lines, everything in one place.
- 2026: Conventional Next.js structure —
app/,lib/,components/,scripts/— opinionated and consistent.
Time to a working app.
- 2023: An afternoon of back-and-forth.
- 2026: About 25 minutes of wall-clock time, most of it
npm installand the seed script.
The shift is not that the model writes more code or writes it faster. The shift is that the model now operates the development environment. It runs commands. It reads outputs. It iterates. The human is in the role of architect, reviewer, and decision-maker — not typist.
Three moments that captured the difference
The validator misfire. While building, a Next.js linter flagged the entries page as missing an await on its params. The agent opened the file, saw the await was already there at line 21, classified it as a false-positive, hit the route with curl, got a 200 response, and moved on. In 2023 I would have re-asked for the file twice and rewritten the page out of paranoia.
The seed bug. First run of the database seed script crashed because a file imported server-only, a Next.js-specific package that doesn't resolve outside the framework's bundler. The agent diagnosed the missing module, removed the import in two files, re-ran the seed, got "Seeded 105 entries." No prompting from me.
The Recharts dimension warning. Dev server logs showed a non-fatal warning that the chart container had width and height of -1 — a known recharts issue with flex children. The agent patched both chart wrappers with the right CSS and props before I asked it to. It saw the warning while reading its own logs and decided to fix it.
In 2023 I had to be the model's eyes, ears, and hands. In 2026 the model has its own.
What it still can't do
This is not a "the singularity is here" post. The model is staggeringly capable, and there are still firm limits.
It can't pick the stack. The agent asked me to choose between a Next.js web app, a Python FastAPI build, and a faithful Tkinter rebuild — and explained trade-offs for each. I made the call. The same is true of nearly every consequential decision: data model, deployment target, where to stop adding features.
It can't decide what to build. The schema fields — automation_potential, frequency, notes — came from me thinking about what would actually drive automation decisions on a real ops team. The model is a brilliant builder of whatever you point it at. Pointing matters more, not less.
It doesn't know when to stop. Without a clear deliverable, the agent will happily keep extending the project: add authentication, multi-tenant teams, a deployment pipeline, an AI coach, a re-implementation of the dashboard in three other frameworks. "Ship this, write later" is still a human judgment call. Almost everyone I know who has used these tools heavily has the same observation: the discipline of not building things is now the bottleneck.
Why this matters for security, automation, and AI work
If you're in any of those three fields, here's the part that should make you stop scrolling.
For automation people: the agent-built toil tracker is, itself, a tool for finding what to automate next. That recursion is the real story. You can spin up bespoke internal tools — runbook generators, ticket-cluster dashboards, on-call summary apps — in an hour. The marginal cost of internal software has collapsed.
For security people: the same workflow that built this application can build an alert-triage dashboard from your SIEM exports, a threat-intel pivot tool from your enrichment APIs, or a quick analyst-feedback loop for tuning detections. The friction that historically pushed SOC teams to live inside ticketing systems and spreadsheets is gone. Build the tool. It will take an afternoon.
For AI practitioners: the most useful thing here isn't the speed. It's the closed feedback loop. The model writes code, runs it, reads the output, and corrects itself — without the human being a manual transport layer between those steps. That's the architectural shift that separates 2023-style chat coding from 2026-style agentic coding, and it's the pattern that's going to define the next generation of LLM applications. Anything you build that doesn't close that loop is going to feel old very fast.
The bigger point
The 2023 article ended with the line "AI can build small useful things, and that's interesting." Three years on, that sentence is dated in a way that surprised me when I re-read it.
The 2026 version of the same exercise produced an application I would happily put in front of my team. The agent didn't just write more code — it operated a development environment, made architectural choices I'd defend, fixed its own mistakes, and produced features I hadn't asked for and didn't know I wanted. The bottleneck has decisively moved from typing code to deciding what to build, and the gap between people who internalize that shift and people who don't is going to widen fast.
If you read the 2023 article when it came out, this is the upgrade post you didn't know you were waiting for. The original toil tracker was a curiosity. The rebuild is a tool I'll keep using. The difference between those two things is what three years of AI tooling has done — and it's the strongest argument I can give you for trying these tools on something real this week, not next quarter.
What I'm going to do next, over the rest of this month, is push on the obvious follow-ups: add authentication, ship it to the public web, plug an AI coach into individual entries, and eventually — the real test — build an agent loop that closes toil tickets, not just measures them. If that works, we'll have something interesting to talk about.
If it doesn't, well, I'll have a fresh stack of trace logs to feed back into the model.