June 3, 2026
AI / LLM Software Security: Part 2
This is the second post in my “AI / LLM Software Security Series”.

Robert Broeckelmann
8 min read
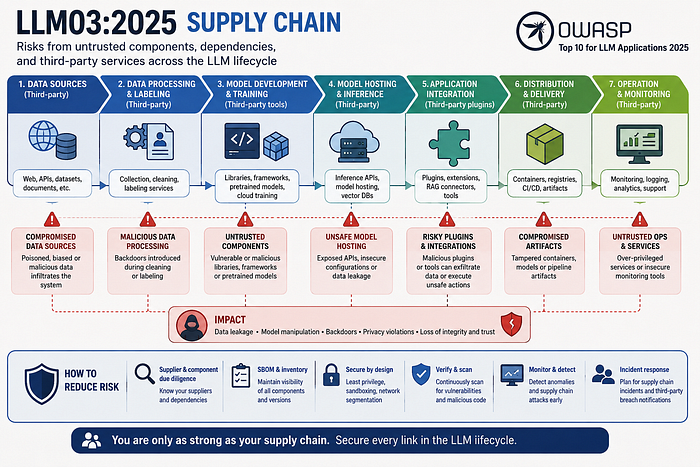
LLM03:2025 Supply Chain
LLM03:2025 "Supply Chain" in the OWASP Top 10 for LLM Applications 2025 focuses on the security risks introduced by the enormous ecosystem of third-party components used to build and operate modern AI systems.
Traditional software already had supply-chain risks through:
- Open-source libraries
- Package managers
- Build systems
- CI/CD pipelines
LLMs dramatically expand this problem because AI systems now depend on:
- Pretrained models
- Fine-tuning datasets
- LoRA adapters (defined below)
- Embedding models
- Plugins and tools
- Agent frameworks
- Vector databases
- Cloud inference APIs
- Model repositories like Hugging Face
- Serialization formats and model loaders
OWASP's concern is that a compromise anywhere in that chain can compromise the entire AI system. Modern LLM applications are rarely built from scratch; instead, they are assembled from layers of:
- External models
- External datasets
- External plugins
- External infrastructure
- External APIs
That creates a massive trust problem.
Unlike traditional source code, many AI components are:
- Opaque binary artifacts
- Difficult to inspect
- Rapidly shared online
- Fine-tuned by unknown parties
- Distributed through community repositories
So organizations may unknowingly deploy:
- Backdoored models
- Poisoned adapters
- Malicious dependencies
- Vulnerable inference servers
- Compromised plugins
Common Supply Chain Risks
There are several common LLM application software supply chain risks.
Compromised Pretrained Models
A downloaded model may contain:
- Hidden behaviors
- Trigger-based backdoors
- Malicious weights
- Poisoned responses
As an example, consider a model that behaves normally until it encounters a specific phrase or token sequence. Then, it turns into a problem.
Poisoned Fine-Tuning Components
LoRA (Low-Rank Adaptation) is one of the most important techniques used to customize large language models without retraining the entire model. This retraining phase is part of the fine-tuning that is done to LLM models to make it specialized. Instead of modifying billions of existing parameters, LoRA freezes the base model and trains a very small set of additional parameters called adapters.
Suppose you have a 70-billion-parameter model and want it to become:
- A cybersecurity assistant
- A legal document analyzer
- A medical coding assistant
- A customer support bot
Traditional fine-tuning would require updating and storing all 70 billion parameters for each specialization. LoRA instead keeps the original model unchanged and stores only the learned differences. This dramatically reduces training cost, memory requirements, and storage. In the original LoRA research, trainable parameters were reduced by up to 10,000× and GPU memory requirements by roughly 3× compared to full fine-tuning
Parameter-Efficient Fine-Tuning (PEFT) is a collection of techniques for adapting large language models by training only a small subset of parameters instead of updating the entire model.
A PEFT adapter is the small set of learned weights that contains the task-specific modifications to a base model.
Think of it this way:
- Base Model: the foundation model (e.g., Llama, Mistral, Qwen)
- PEFT Method: the technique used to adapt it (LoRA, IA³, Prefix Tuning, Prompt Tuning, etc.)
- PEFT Adapter: the resulting lightweight artifact containing the learned changes
LoRA is the most popular PEFT technique, so in practice many people use the terms "LoRA adapter" and "PEFT adapter" almost interchangeably; although, technically LoRA is just one type of PEFT.
LoRA and PEFT adapters are especially risky because:
- they are small
- easy to distribute
- frequently shared online
- often trusted without review
An attacker can subtly alter model behavior through a malicious adapter.
Dataset Poisoning
Training or retrieval datasets may be manipulated to:
- Bias outputs
- Inject malicious instructions
- Create hidden triggers
- Spread misinformation
This overlaps with LLM04:2025 Data and Model Poisoning, but LLM03 focuses on the supply-chain origin of the compromise.
Malicious Plugins and Agent Tools
Agentic AI systems increasingly rely on:
- Plugins
- MCP servers
- External APIs
- Tool integrations
A malicious tool can:
- Exfiltrate secrets
- Manipulate outputs
- Execute unauthorized actions
- Poison future agent decisions
OWASP views agent ecosystems as rapidly expanding attack surfaces.
Unsafe Model Serialization
Some model formats (especially Python pickle-based formats) can execute arbitrary code when loaded.
This means: Downloading a model can effectively become remote code execution.
Compromised Infrastructure
The supply chain also includes:
- CI/CD pipelines
- Artifact registries
- Build systems
- Inference infrastructure
- Container images
- Developer workstations
A breach anywhere in the pipeline can taint deployed AI systems.
Why LLM Supply Chains Are Harder Than Traditional Software
AI supply chains are uniquely difficult because:
- Models are huge binary objects
- Internal behavior is hard to audit (I miss my SQL execution plans)
- Fine-tuning changes are difficult to detect
- Dependencies are deeply layered
- Open-source sharing is extremely fast-moving
- Agent ecosystems dynamically load tools and models
Researchers studying real-world LLM ecosystems found:
- Deeply nested dependencies
- Thousands of interconnected components
- Widespread vulnerabilities across models, datasets, and libraries
Some Real-World Examples
OWASP and researchers have referenced incidents involving:
- Malicious npm/PyPI packages
- Poisoned AI model repositories
- Compromised AI gateways
- Supply-chain attacks against developer tooling
- Model backdoors
- Vulnerable MCP ecosystems
The broader software world already demonstrated the severity of supply-chain attacks through incidents like:
- SolarWinds
- Log4Shell
- Malicious npm package campaigns
OWASP argues that AI ecosystems inherit all those risks plus entirely new model-specific ones.
Recommended Mitigations
OWASP recommends treating AI supply chains with a "zero trust" mindset.
Verify model provenance
Model provenance is the documented history and origin of a large language model — how it was created, what data it was trained on, what modifications were made to it, and how it evolved over time.
If data provenance is the chain of custody for data, then model provenance is the chain of custody for the model itself.
Model provenance answers:
- Where did the model come from?
- Who created it?
- Which base model was used?
- What training data was used?
- What fine-tuning was performed?
- Which LoRA/PEFT adapters were applied?
- What modifications have been made over time?
- Who made those modifications?
- When were the modifications made?
- Which version is currently deployed?
- How was the model evaluated and tested?
- Can the model be reproduced?
- Can the model be trusted?
- Has the model been tampered with?
- What components make up the final deployed model?
More succinctly, model provenance answers "What is this model, where did it come from, what happened to it, and can we trust it?"
Only use trusted sources and signed artifacts.
Maintain SBOMs
Software Bill of Materials (SBOMs) is a listing of all the dependent components of a system. It's analogous to a Bill of Materials for a physical world product. The SBOM tracks:
- Models
- Datasets
- Adapters
- Plugins
- Dependencies
- Tools
Cryptographic Signing and Integrity Checks
Integrity can be validated through a digital signature. It is common to have SHA256 signatures published along side binary releases of LLM dependencies (release binaries, model files, etc). These signatures should be validated to establish integrity (meaning, it hasn't been tampered with) and, thus, trust of that component. Of course, this trust only extends as far as you trust the author.
Through cryptographic signing (ie, digital signatures), ensure artifacts have not been tampered with.
Sandbox Model Execution
Treat downloaded models as potentially hostile code.
I discussed LLM sandboxing in Part 1 of this series.
Restrict Plugin Permissions
Use least privilege for:
- Tools
- Agents
- APIs
- Connectors
Audit and Scan Dependencies
Continuously monitor:
- Packages
- Registries
- Model repositories
- CI/CD systems
We discussed monitoring in Part 1.
Secure The Development Pipeline
For a thorough discussion of this topic see this post.
In the meantime, make sure you protect:
- Code repositories
- Build servers
- Artifact registries
- Developer workstations
- Deployment pipelines
Why LLM03 is Important
The key realization behind LLM03 is that modern AI systems are not just "models." They are ecosystems. Thus, every one of these becomes part of the attack surface:
- Model
- Plugin
- dataset
- Adapter
- Framework
- Tool
- API
- Pipeline
In many cases, the greatest risk is no longer the model itself; it is the chain of trust surrounding it.
LLM04: Data and Model Poisoning
LLM04:2025 "Data and Model Poisoning" in the OWASP Top 10 for LLM Applications 2025 focuses on attacks where malicious actors manipulate the data, models, embeddings, or fine-tuning processes used by AI systems in order to secretly alter model behavior.
At its core, this is an integrity attack against AI systems: Instead of attacking the application directly, the attacker corrupts what the model learns from. LLMs are shaped by:
- Training data
- Fine-tuning datasets
- Embeddings
- Feedback loops
- Retrieval corpora
- Model weights
If an attacker can influence those inputs, they may be able to:
- Bias outputs
- Implant hidden triggers
- Introduce misinformation
- Create backdoors
- Reduce model accuracy
- Bypass safeguards
- Manipulate downstream decisions
Unlike prompt injection, poisoning often happens before deployment and may remain hidden for long periods.
Where Poisoning Happens
OWASP identifies several vulnerable stages in the LLM lifecycle.
Pre-Training Poisoning
Poisoning in this stage sees attackers manipulate massive internet-scale datasets used to train foundation models. For example:
- Injecting false information into public websites.
- Coordinated misinformation campaigns.
- Embedding hidden trigger phrases in public content.
The impact of this is the model absorbs poisoned knowledge globally.
Fine-Tuning Poisoning
Poisoning in this stage sees attackers corrupt domain-specific training datasets. Examples include:
- Altering healthcare fine-tuning data
- Poisoning financial sentiment datasets
- Manipulating customer support corpora
The impact of this is that the model behaves incorrectly in targeted contexts.
Embedding and Retrieval Poisoning
Poisoning in this stage sees attackers poison:
- Vector databases
- RAG document stores
- Knowledge bases
- Search indexes
This is especially dangerous because the poisoned content may never modify the model weights at all. Instead, the malicious data gets injected dynamically during inference.
Common Attack Types
There are several common attack types.
Backdoor Injection
In this attack type, a hidden trigger causes malicious behavior only when specific phrases or tokens appear. For example:
- A harmless-looking phrase activates:
- Policy bypasses
- Data leakage
- Malicious code generation
These are often called:
- Sleeper agents
- Latent triggers
- Hidden behaviors
The enemy within, if you will.
Bias and Manipulation Attacks
In this attack type, a poisoned data may subtly steer outputs toward:
- Political agendas
- Misinformation
- Propaganda
- Harmful stereotypes
- Commercial manipulation
The dangerous part is that outputs may still appear "normal" most of the time.
Accuracy Degradation
In this attack type, attackers intentionally reduce model quality by injecting:
- Noisy data
- Contradictory facts
- Adversarial examples
- Malformed training samples
The goal of doing this is to:
- Reduce trustworthiness
- Destabilize outputs
- Create hallucinations
- Impair reliability
Why LLM Poisoning Is Dangerous
Poisoning attacks are difficult because they are often:
- Subtle
- Distributed
- statistically hidden
- Difficult to audit
- Hard to reverse
A poisoned model may:
- Pass benchmarks
- Behave normally in testing
- Only activate under rare conditions
This makes detection of such problems extremely challenging.
Real-World Concerns
Researchers and OWASP warn about:
- Poisoned open datasets
- Malicious model repositories
- Adversarial fine-tuning
- Corrupted embeddings
- Manipulated public web content
- Coordinated influence campaigns
As AI increasingly trains on internet-scale data, attackers may attempt to "shape reality" for future models by poisoning the information ecosystem itself.
Recommended Mitigations
OWASP recommends defense-in-depth protections.
Verify Data Provenance
Data provenance is the documented history of a piece of data: where it came from, how it was created, how it has been modified, who accessed it, and how it moved through systems over time.
Think of it as a chain of custody for data.
Just as forensic investigators track who handled a piece of evidence, data provenance tracks every significant event in the life of a dataset.
As an example, suppose a sales report shows an organization's revenue for Q2 at $12.3 million
Data provenance answers questions such as:
- Which database did that number come from?
- Which tables were used?
- What SQL queries were executed?
- Were any transformations applied?
- Who generated the report?
- When was it generated?
- Has the underlying data changed since then?
Without provenance, you have the number. With provenance, you have the story behind the number.
This matters because it allows for trust and verification.
If someone challenges a result, provenance allows you to prove how it was produced. For example, "This financial statement was generated from these transactions, using this calculation, on this date." Data provenance tracks:
- Where data came from
- How it was modified
- Who contributed it
To accommplish data provenance use signed datasets and Machine Learning Bill of Materials (ML-BOM) / Software Bill of Materials (SBOM) approaches.
Vet External Data Sources
Treat data sets you didn't create yourself as potential bullshit. Treat the following as potentially hostile:
- Public web data
- Community uploads
- Third-party datasets
- External embeddings
Monitor for Anomalies
Continiously monitor systems. Look for:
- Unexpected behaviors
- Trigger activations
- Sudden output drift
- Abnormal embeddings
- Unusual training loss patterns
We discussed monitoring in Part 1.
Red Team Testing
Continuously test models for:
- Hidden triggers
- Jailbreaks
- Poisoned outputs
- Adversarial prompts
- Retrieval poisoning
We discussed red team testing in Part 1.
Isolate and Validate Updates
Never blindly deploy the following without testing and sandboxing:
- new fine-tunes
- LoRA adapters
- embeddings
- datasets
- third-party models
We discussed isolation and validation in Part 1.
Why LLM04 Matters
LLM04 represents a major shift in cybersecurity thinking:
Traditional security protects:
- Applications
- Networks
- Databases
LLM04 highlights that now attackers may target the model's understanding of reality itself.
Instead of exploiting code execution directly, poisoning attacks attempt to:
- Corrupt knowledge
- Alter reasoning
- Manipulate outputs
- Implant hidden behaviors
In LLM applications, the training data becomes part of the attack surface.
Notes
- AI / GenAI / ChatGPT / etc were not used to generate the text of this article.
- ChatGPT was used to generate the images.
- I used em dashes in my writing before the current GenAI wave was a thing. Not planning on changing now.
- Names have been changed to protect the guilty.
- None of the hostnames or users used in examples actually exist.
- Feel free to post any comments or suggestions below.