

Table of Contents
- Introduction
- Part 1: CTI Foundations
- Part 2: Analytic Discipline
- Part 3: Frameworks
- Part 4: Attribution
- Part 5: Infrastructure Pivoting
- Part 6: Actor Research
- Part 7: Sector CTI
- Part 8: CTI to Detection
- Part 9: AI-Assisted CTI
- Part 10: Templates
- Worked Example: Full MuddyWater Case
- References
Introduction
Purpose
This manual provides a structured operating model for cyber threat intelligence work: from collection requirements to evidence handling, analytic judgment, infrastructure pivoting, actor profiling, hunting hypotheses, detection engineering, SOC handoff, and executive communication.
If you are reviewing the manual professionally, start with Role-Based Reading Paths, Publication-Grade Review Backlog, and Authoritative Bibliography.
CTI Ecosystem
This manual is one part of a three-book CTI ecosystem. Use CTI Project Ecosystem and Cross-Project Fact Correlation to move between general analyst tradecraft, customer delivery methodology, and the Israel-focused actor knowledge base.
- Customer-Driven AI CTI Project turns tradecraft into gated delivery.
- Israel Government Threat Actors CTI provides sector-specific actor, tool, TTP, hunt, and detection examples.
What This Manual Is

This is a practitioner field manual. It is designed to help an analyst produce repeatable, reviewable CTI outputs rather than disconnected research notes.
The manual uses public, defensive, TLP:CLEAR material and transforms Medium article themes into a coherent tradecraft reference. It does not copy blog posts into documentation pages. It reorganizes the ideas into workflows, templates, checklists, and review gates.
What This Manual Is Not
This is not a beginner glossary, an exploit guide, a malware analysis lab, an IOC dump, or a production detection pack. It does not provide malware source code, unauthorized access instructions, leaked data, credentials, or victim-sensitive information.
Operating Principles

- State the intelligence question before collecting sources.
- Separate facts from assessments, inferences, assumptions, and gaps.
- Rate source reliability and information credibility.
- Explain confidence instead of decorating prose with confidence words.
- Do not use ATT&CK as attribution evidence.
- Treat infrastructure pivots as hypotheses until bounded by corroboration.
- Convert CTI into decisions, hunts, detections, SOC actions, or documented gaps.
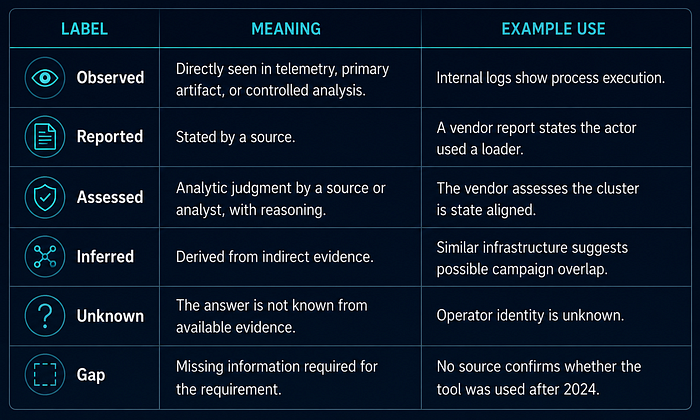
Evidence Labels
The manual uses these labels:
- Observed: directly seen in telemetry, primary artifact, or controlled analysis.
- Reported: stated by a source.
- Assessed: analytic judgment by a source or by the analyst, with reasoning.
- Inferred: derived from indirect evidence; weaker than observed or reported.
- Unknown: not known from available evidence.
- Gap: required information is missing and should be collected or documented.
Confidence
Confidence reflects evidence quality, source access, corroboration, and analytic consistency. It does not equal probability. A high-confidence judgment can still be wrong if new evidence emerges; a low-confidence judgment may still be operationally important if impact is high.
How To Navigate
Start with CTI Foundations, then move into analytic discipline, frameworks, attribution, infrastructure pivoting, actor research, sector CTI, CTI-to-detection, AI-assisted CTI, and reusable templates.
Known Limitations

Purpose
This page defines the boundaries of the field manual so readers do not overinterpret tradecraft guidance as validated operational coverage.
Limitations
- The manual is based on public, TLP:CLEAR material and author-owned public writing.
- It is not a production SOC detection pack.
- Templates require local adaptation before use in a customer or enterprise environment.
- ATT&CK mappings in examples are teaching aids unless tied to explicit evidence.
- Attribution examples are analytic exercises, not legal or government determinations.
- Infrastructure pivoting guidance must be bounded by false-positive controls and corroboration.
- AI-assisted workflows require human review, source checking, and evidence validation.
No detection may be represented as production coverage unless it reaches DRL-9. AI-assisted outputs must follow the AI CTI Control Matrix, and doctrine-heavy claims should cite the Authoritative Bibliography instead of relying only on author articles.
Defensive Boundary
Do not add malware samples, exploit instructions, leaked data, credentials, victim-sensitive information, or operational instructions for unauthorized access.
Part 1: CTI Foundations
What Is CTI?

Purpose
Define cyber threat intelligence as an analytic discipline that supports decisions, not as a synonym for IOCs, threat feeds, or long reports.
Practitioner-Level Explanation
Cyber threat intelligence is evidence-based analysis of adversary intent, capability, opportunity, behavior, infrastructure, targeting, and likely operational relevance to a defended environment. CTI becomes useful when it answers a decision-maker's question and can be traced to evidence, limitations, confidence, and a recommended action.
A CTI product can be strategic, operational, tactical, or technical. The category is less important than whether the product is fit for its consumer. A board-level risk note, a SOC hunt hypothesis, a detection backlog item, an actor profile, and an infrastructure pivot log are all CTI outputs if they connect evidence to decisions.
CTI is not merely collecting indicators. Indicators can support CTI, but without context, confidence, expiration, source rating, and actionability, they are raw data. CTI requires interpretation and explicit uncertainty.
CTI Relevance
Good CTI helps teams prioritize limited defensive resources. It answers questions such as:
- Which threats matter to this organization now?
- Which assets, identities, suppliers, or telemetry gaps create exposure?
- Which actor behaviors are defensible to hunt for?
- Which claims are strong enough to drive a detection, response plan, or executive decision?
- Which claims remain gaps?
Common Mistakes
- Treating IOC lists as finished intelligence.
- Writing actor profiles that do not explain relevance to a specific environment.
- Using ATT&CK coverage charts as proof of detection coverage.
- Making attribution claims from shared tooling alone.
- Reporting every source claim with equal weight.
- Hiding uncertainty to make the report sound stronger.
Practical Workflow
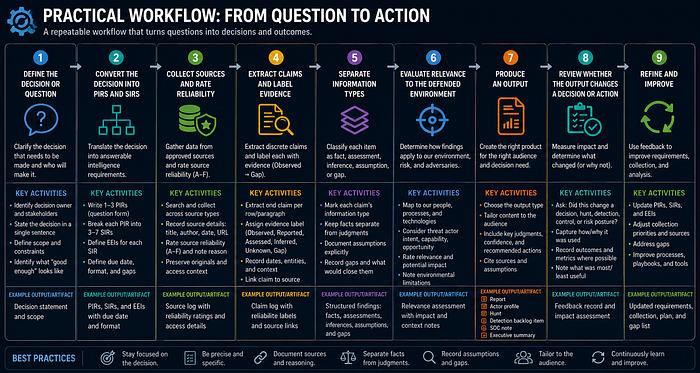
- Define the decision or question.
- Convert the decision into PIRs and SIRs.
- Collect sources and rate reliability.
- Extract claims and label evidence.
- Separate facts, assessments, inferences, assumptions, and gaps.
- Evaluate relevance to the defended environment.
- Produce an output: report, actor profile, hunt, detection backlog item, SOC note, or executive summary.
- Review whether the output changes a decision or action.
Example / Mini Case
A vendor reports that an actor abuses remote monitoring and management tools after phishing. The weak output is: "Actor X uses RMM tools; block RMM." The CTI output is stronger:
- Reported: Vendor observed RMM installation after phishing in a campaign.
- Assessment: This is relevant because the organization allows several RMM products for IT support.
- Gap: It is unknown whether current EDR logs capture RMM child processes and network connections consistently.
- Action: Create a hunt for newly installed RMM tools on non-IT endpoints, then decide whether to move to detection after baseline review.
Analyst Checklist
- Is the intelligence question explicit?
- Is the customer or consumer defined?
- Are sources rated?
- Are claims separated from assessments?
- Are assumptions and gaps visible?
- Is confidence explained?
- Is there a recommended action or documented reason for no action?
Intelligence Cycle
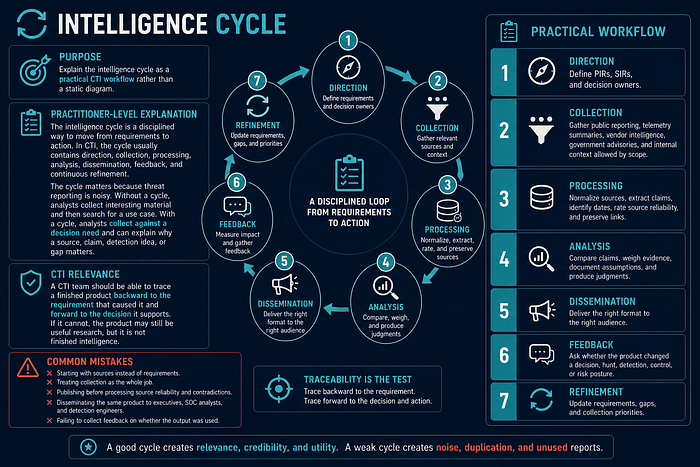
Purpose
Explain the intelligence cycle as a practical CTI workflow rather than a static diagram.
Practitioner-Level Explanation
The intelligence cycle is a disciplined way to move from requirements to action. In CTI, the cycle usually contains direction, collection, processing, analysis, dissemination, feedback, and continuous refinement.
The cycle matters because threat reporting is noisy. Without a cycle, analysts collect interesting material and then search for a use case. With a cycle, analysts collect against a decision need and can explain why a source, claim, detection idea, or gap matters.
CTI Relevance
A CTI team should be able to trace a finished product backward to the requirement that caused it and forward to the decision it supports. If it cannot, the product may still be useful research, but it is not finished intelligence.
Common Mistakes
- Starting with sources instead of requirements.
- Treating collection as the whole job.
- Publishing before processing source reliability and contradictions.
- Disseminating the same product to executives, SOC analysts, and detection engineers.
- Failing to collect feedback on whether the output was used.
Practical Workflow
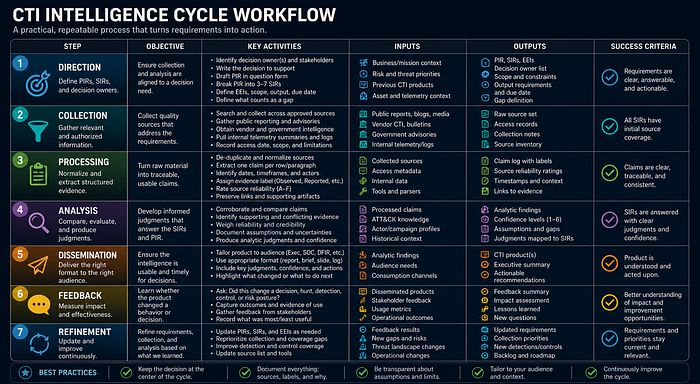
- Direction: Define PIRs, SIRs, and decision owners.
- Collection: Gather public reporting, telemetry summaries, vendor intelligence, government advisories, and internal context allowed by scope.
- Processing: Normalize sources, extract claims, identify dates, rate source reliability, and preserve links.
- Analysis: Compare claims, weigh evidence, document assumptions, and produce judgments.
- Dissemination: Deliver the right format to the right audience.
- Feedback: Ask whether the product changed a decision, hunt, detection, control, or risk posture.
- Refinement: Update requirements, gaps, and collection priorities.
Example / Mini Case
A SOC lead asks whether recent reporting on an actor should change monitoring. The cycle prevents a vague answer.
- Direction: Determine whether the actor's reported behaviors intersect with the organization's telemetry.
- Collection: Pull public vendor reports and existing internal telemetry inventory.
- Processing: Extract behaviors, not only IOCs.
- Analysis: Identify which behaviors can be hunted with current logs.
- Dissemination: Provide a detection backlog item and a telemetry gap note.
- Feedback: SOC confirms whether the hunt produced results or only baselining needs.
Analyst Checklist
- Is there a named requirement?
- Is collection scoped to the requirement?
- Are sources processed before analysis?
- Are judgments separated from raw reporting?
- Is the output tailored to the consumer?
- Is feedback captured?
PIR, SIR, and EEI

Purpose
Define Priority Intelligence Requirements, Specific Intelligence Requirements, and Essential Elements of Information in a CTI workflow.
Practitioner-Level Explanation
PIRs, SIRs, and EEIs convert broad curiosity into answerable intelligence work.
A PIR is the high-level intelligence question tied to a decision. A SIR breaks that question into specific sub-questions. An EEI defines the concrete information needed to answer a SIR.
The distinction matters because analysts often mistake a topic for a requirement. "MuddyWater" is a topic. "Which MuddyWater behaviors reported since 2024 are observable with our endpoint and identity telemetry?" is closer to a PIR.
CTI Relevance
Well-written requirements prevent unfocused collection and make it easier to decide when an output is complete enough. They also help analysts avoid collecting every available article when the actual decision only requires a bounded answer.
Common Mistakes
- Writing PIRs that are too broad to answer.
- Writing SIRs that simply restate the PIR.
- Skipping EEIs and then arguing about evidence after collection.
- Mixing strategic, operational, and technical requirements in one question.
- Forgetting the decision owner.
Practical Workflow
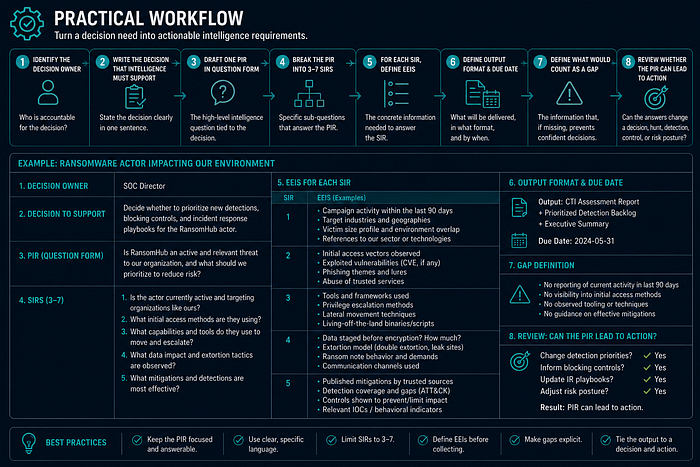
- Identify the decision owner.
- Write the decision that intelligence must support.
- Draft one PIR in question form.
- Break the PIR into three to seven SIRs.
- For each SIR, define EEIs.
- Define required output format and due date.
- Define what would count as a gap.
- Review whether the PIR can lead to action.
Example / Mini Case
Decision:
Should the SOC prioritize a 30-day hunt for remote management tool abuse?
PIR:
Which public CTI reporting since 2024 describes adversary abuse of RMM tools that is relevant to our endpoint estate?
SIR-1:
Which actors or clusters are reported to use RMM tools after phishing or edge compromise?
EEIs:
- Tool names
- Initial access method
- Observed process behavior
- Required telemetry
- Reported sectors or victimology
- Confidence and source reliability
SIR-2:
Can our telemetry observe the behavior?
EEIs:
- Endpoint process logs
- Software inventory
- Network connections
- Identity logs for remote access sessions
- Known administrative RMM baselinesAnalyst Checklist
- Does the PIR support a real decision?
- Is the PIR answerable with available or collectable evidence?
- Do SIRs decompose the PIR rather than repeat it?
- Are EEIs concrete enough to drive collection?
- Is the expected output defined?
- Are gaps acceptable and documented?
Evidence Labels
Purpose
Define a consistent evidence-labeling model so CTI claims can be reviewed, challenged, and converted into action without losing uncertainty.
Practitioner-Level Explanation
Evidence labels make analytic status explicit. They prevent analysts from writing every sentence as if it has the same evidentiary weight.
This manual uses six labels:
Labels do not replace prose. The analyst still needs to explain source quality, confidence, contradictions, and limitations.
CTI Relevance
Evidence labels are useful across the whole CTI workflow:
- Source registers use them to classify extracted claims.
- Actor profiles use them to avoid overclaiming attribution.
- ATT&CK mappings use them to show whether behavior is observed or only actor-level reporting.
- Detection backlogs use them to decide whether a hypothesis is strong enough to test.
- Executive summaries use them to avoid false certainty.
Common Mistakes
- Treating reported claims as observed facts.
- Treating vendor assessments as universal truth.
- Using inferred links as attribution.
- Leaving gaps implicit.
- Failing to update labels when new evidence arrives.
Practical Workflow
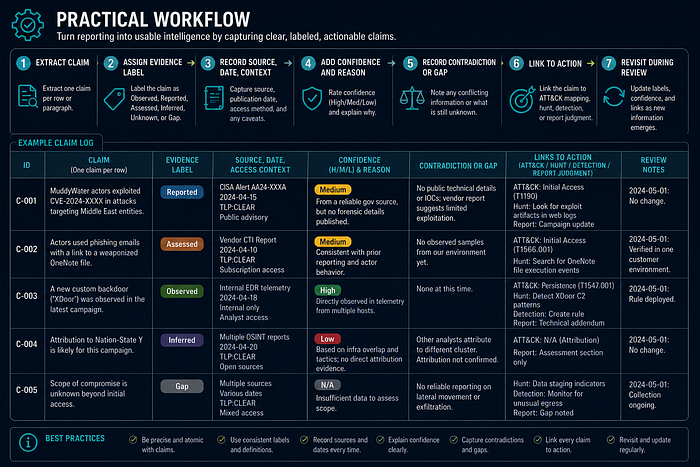
- Extract one claim per row or paragraph.
- Assign an evidence label.
- Record source, date, and access context.
- Add confidence and confidence reason.
- Record contradiction or gap.
- Link the claim to any ATT&CK mapping, hunt, detection, or report judgment.
- Revisit labels during review.
Example / Mini Case
Claim:
A public report states that a cluster used cloud storage to stage payloads.
Evidence Label:
Reported
Confidence:
Medium confidence, because the source is reliable but the report does not include telemetry excerpts or multiple corroborating sources.
Detection Use:
Do not alert on all cloud storage use. Build a hunt for cloud storage download followed by script execution on endpoints where that pattern is unusual.
Gap:
No internal telemetry has confirmed this behavior in the defended environment.Analyst Checklist
- Is each major claim labeled?
- Are reported claims separated from observed facts?
- Are assessments attributed to the source or clearly marked as analyst assessment?
- Are inferred links prevented from becoming hard claims?
- Are gaps visible enough to drive follow-up collection?
- Are labels linked to downstream actions?
Source Reliability
Purpose
Provide a practical model for rating source reliability and information credibility without pretending the rating is absolute truth.
Practitioner-Level Explanation
Source reliability describes the historic trustworthiness, access, and discipline of the source. Information credibility describes how believable a specific claim is after considering corroboration, detail, consistency, and proximity to evidence. A strong CTI product tracks both.
The model in use is the Admiralty Code (NATO-style source evaluation), sometimes called the Admiralty System or the STANAG 2511 model. It is also codified in the MISP admiral taxonomy and widely used in law enforcement, military intelligence, and commercial CTI.
The notation is not mathematical. It is a review prompt that forces the analyst to explain why a claim deserves the weight assigned to it.
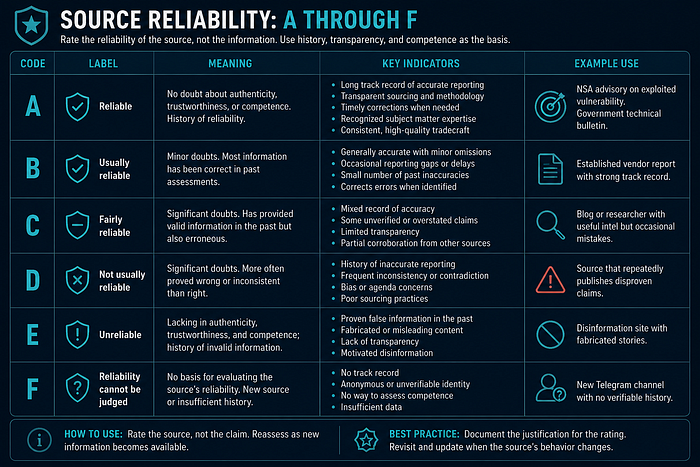
Source Reliability: A through F
Guidance:
- Government advisories with attributed, publicly accountable authors typically qualify for A or B.
- Established commercial CTI vendors with consistent methodology typically qualify for B or C.
- Anonymous social media accounts, unverified personas, and first-use sources typically qualify for F until track record exists.
- Source reliability changes over time. Reassess when new evidence about the source appears.
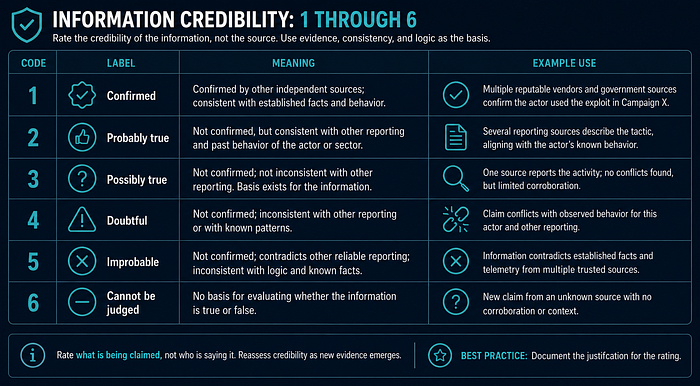
Information Credibility: 1 through 6
Guidance:
- Corroboration from independent primary sources is required for a rating of 1. Shared sourcing from the same secondary summary does not count as independent corroboration.
- A claim rated 2 or 3 may still be operationally important. Low credibility rating does not mean ignore; it means collect more evidence before acting.
- A claim rated 4 or 5 should not drive defensive action without explicit risk acceptance.
Combined Notation and Examples
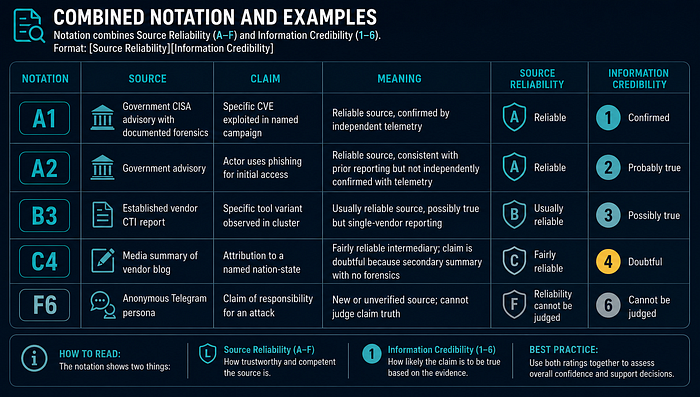
Common Mistakes
- Rating a source once and never revisiting it.
- Confusing source reputation with claim correctness. An A-rated source can report a 5-credibility claim.
- Treating a vendor blog, government advisory, news article, and persona claim as equal.
- Using A-F/1–6 notation without a written confidence reason.
- Treating a secondary summary as independent corroboration.
Warning: Ratings Are Review Prompts, Not Mathematical Truth
An A-rated source can make a weak claim. A weak source can report something that later proves true. The Admiralty rating system is a structured way to force the analyst to explain the basis for the claim weight. It does not remove the analyst's judgment responsibility. Do not use ratings to automate trust decisions.
Practical Workflow
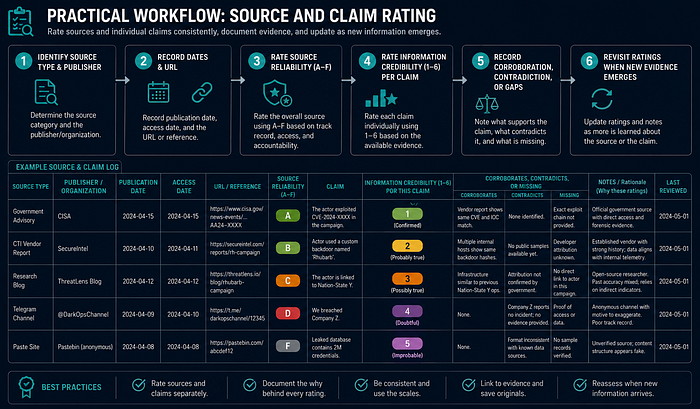
- Identify the source type and publisher.
- Record publication date, access date, and URL.
- Rate source reliability (A-F) based on track record, access, and accountability.
- Rate information credibility (1–6) for each claim, not only for the source overall.
- Record what corroborates, contradicts, or is missing.
- Revisit ratings when new evidence about the source or the claim appears.
Example / Mini Case
A government advisory states that an actor exploited a specific appliance vulnerability. The source rates A because it is a primary government source with documented accountability and consistent past accuracy. The specific claim rates 2 rather than 1 because the advisory describes the technique but does not provide raw telemetry or forensic artifact details for independent verification. A commercial vendor blog summarizing that advisory may rate C or B depending on track record, and the claim rates no higher than 3 in the vendor summary because the advisory is now the primary source, not the blog. The blog should cite the advisory; if it does not, rate the claim 4.
Analyst Checklist
- Is source reliability rated separately from information credibility?
- Is the rating claim-specific, not only source-level?
- Are publication and access dates recorded?
- Are contradictions and corroboration visible?
- Would a reviewer understand why the rating was assigned without asking the analyst?
- Has the source been reassessed if new evidence about it appeared?
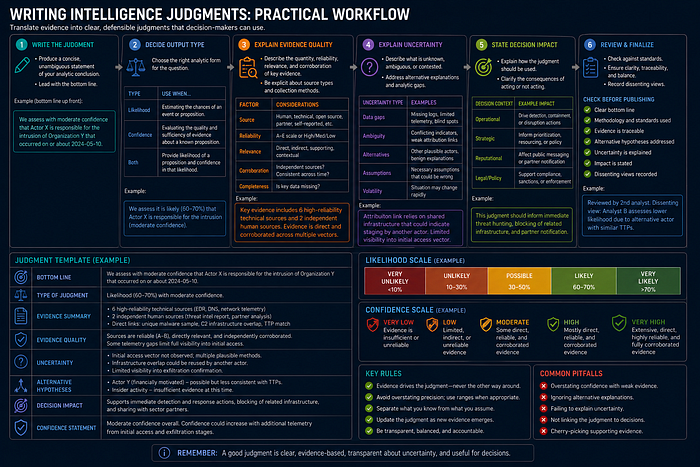
Confidence Language
Purpose
Explain how to use confidence language in CTI without confusing confidence with probability.
Practitioner-Level Explanation
Confidence communicates the analyst's trust in a judgment based on evidence quality, source access, corroboration, analytic consistency, and known gaps. It does not mean probability. A high-confidence judgment can still be wrong if new evidence appears. A low-confidence judgment can still matter if the potential impact is severe.
This manual uses High, Medium, and Low confidence. Each confidence statement must include the reason. Confidence without a reason is decoration.
CTI Relevance
Confidence language allows CTI teams to be useful without overclaiming. It gives SOC, IR, detection, and executive consumers enough context to decide how much weight to place on a judgment.
Common Mistakes
- Using confidence words as tone rather than analytic method.
- Equating high confidence with certainty.
- Writing probability numbers without calibration.
- Changing confidence to satisfy a stakeholder preference.
Practical Workflow
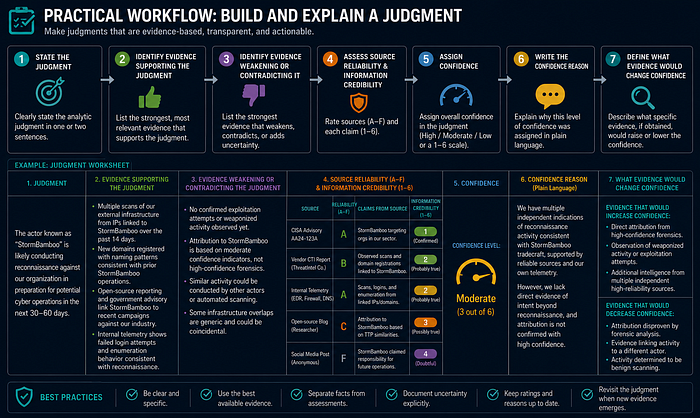
- State the judgment.
- Identify evidence supporting the judgment.
- Identify evidence weakening or contradicting it.
- Assess source reliability and information credibility.
- Assign confidence.
- Write the confidence reason in plain language.
- Define what evidence would change the confidence level.
Example / Mini Case
Weak: "We assess with high confidence that Actor X is responsible."
Better: "We assess with medium confidence that the activity aligns with Actor X reporting because tooling, targeting, and timing match two reliable vendor reports. Confidence is limited because no unique infrastructure overlap or internal forensic artifact is available."
Analyst Checklist
- Is confidence attached to a specific judgment?
- Is the reason explicit?
- Are gaps and contradictions included?
- Could another analyst challenge the judgment from the evidence record?
- Is confidence separated from probability?
Finished Intelligence vs Research Notes
Purpose
Separate raw research activity from finished intelligence that can support decisions.
Practitioner-Level Explanation
Research notes capture what an analyst found. Finished intelligence explains what the findings mean, why they matter, how confident the analyst is, what remains unknown, and what action should follow.
Research notes are necessary. They preserve source material, quotes, timestamps, pivots, and abandoned leads. But they are not usually suitable for a SOC lead, executive, or detection engineer without synthesis.
Finished intelligence requires judgment. It must include evidence, uncertainty, relevance, and a practical output.
CTI Relevance
This distinction is critical in CTI-to-detection work. A detection engineer does not need ten pages of article excerpts. They need a behavior, a confidence statement, telemetry requirements, expected false positives, and validation guidance.
Common Mistakes
- Delivering source summaries without judgment.
- Treating long reports as more mature than concise assessments.
- Hiding contradictions in appendices.
- Omitting confidence because the analyst does not want to be challenged.
- Publishing raw IOCs without expiration, context, or source rating.
Practical Workflow
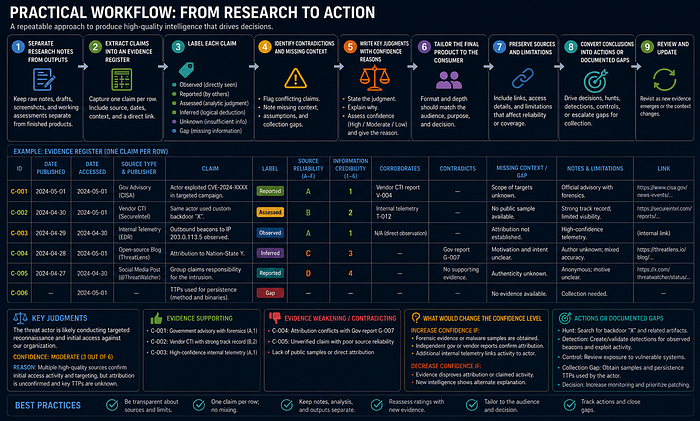
- Keep research notes separate from finished outputs.
- Extract claims into an evidence register.
- Label each claim: Observed, Reported, Assessed, Inferred, Unknown, or Gap.
- Identify contradictions and missing context.
- Write key judgments with confidence reasons.
- Tailor the final product to the consumer.
- Preserve source links and limitations.
- Convert conclusions into actions or documented gaps.
Example / Mini Case
Research note:
Vendor A says the actor used phishing and a cloud storage link. Vendor B says a similar campaign used archives and script execution. Several IOCs are listed.Finished intelligence:
Assessment:
Reported campaign behavior supports a medium-confidence hunt for archive-based phishing leading to script execution and external staging. The public sources do not prove the same actor operated both campaigns. The SOC should hunt behavior rather than actor label.
Action:
Run a 30-day hunt for archive extraction followed by script interpreter execution and outbound connection to newly observed domains. Record false positives from IT automation and software installers.Analyst Checklist
- Are raw notes separated from judgments?
- Are claims traceable to sources?
- Are contradictions documented?
- Is confidence justified?
- Is the consumer clear?
- Does the output support a decision, action, or gap?
Part 2: Analytic Discipline
Sherman Kent for CTI
Purpose
Translate Sherman Kent-style analytic discipline into practical CTI writing and review habits.
Practitioner-Level Explanation
Sherman Kent's core value for CTI is disciplined judgment: say what is known, how it is known, what is assessed, how confident the analyst is, and what remains uncertain. CTI often fails when it sounds certain but is built on unexamined assumptions.
Kent-style discipline helps analysts avoid vague estimative language, overclaiming, source laundering, and attribution shortcuts. The goal is not academic writing. The goal is a judgment that can survive review by a skeptical peer.
The two pillars are:
- Separation: facts from reporting from assessment from inference from assumption from gap.
- Calibration: confidence terms used consistently and tied to evidence strength, source access, and corroboration.
Calibrated Probability Wording Table
The following table adapts the Sherman Kent Words of Estimative Probability (WEP) tradition to CTI usage. The approximate probability ranges are guideposts, not mathematical bounds. The decisive factor is evidence quality, not word choice.

Critical rule: The term used must be tied to a reason. "Likely" with no reason is not calibrated language. "Likely because three independent government advisories describe the same behavior" is.
Confidence Is Not Probability
Confidence (High/Medium/Low) and probability wording (likely/possibly/remote) serve different purposes:
- Probability wording describes where the analyst places the judgment on a likelihood scale.
- Confidence describes how well the evidence, source access, and analytic process support that placement.
A judgment can be "likely" with only low confidence, meaning the analyst leans toward the claim but the evidence base is thin. A judgment can be "possibly" with high confidence, meaning the evidence clearly supports a claim being plausible but not dominant.
Do not conflate these. "High confidence" does not mean "almost certainly."
Common Mistakes
Bad Example 1 — "Likely" without explanation
The actor will likely target financial institutions next quarter.Problem: "Likely" is presented without evidence, source, corroboration, or alternative hypothesis. A reader cannot evaluate the claim or decide how to act on it.
Corrected:
Key Judgment: The actor may prioritize financial institutions in the next quarter.
Estimative Term: Possibly (25-50%)
Evidence: Reported - Two vendor reports describe the actor targeting financial sector victims in adjacent campaigns over the past 90 days (SRC-003, SRC-007).
Assumptions: The actor's target selection is driven by sector overlap with past campaigns rather than bespoke customer selection.
Gaps: No primary government advisory confirms targeting intent. No telemetry from this environment to confirm exposure.
Alternative: The actor may shift to telecom if financial-sector hardening reduces return.
Confidence: Low confidence — evidence is vendor reporting, no primary source, no local telemetry confirmation.
What Would Change It: Primary advisory or observed targeting of financial institutions by this cluster.Bad Example 2 — "High confidence" from one weak source
We assess with high confidence that the malware is operated by a nation-state sponsor.Problem: "High confidence" from a single secondary vendor report or from shared tooling alone is not defensible. High confidence requires primary sources, corroboration, and contradiction review.
Corrected:
Key Judgment: Sponsor attribution is unknown.
Evidence: Reported - Vendor A assesses nation-state sponsorship (SRC-011). No primary source confirms.
Alternative Hypotheses: Criminal operator for hire; independent hacktivist with state-adjacent motivation; false flag.
Confidence: Low confidence — single-vendor assessment, no corroboration, tool overlap is the primary cited evidence.
What Would Change It: Primary government attribution statement with supporting forensics; independent corroboration of exclusive infrastructure links.Bad Example 3 — "Almost certainly" with no contradiction review
This is almost certainly the same group responsible for the 2024 supply chain intrusion.Problem: "Almost certainly" implies contradictions and alternatives have been reviewed and found non-credible. Asserting it without showing the work breaks Kent discipline.
Corrected:
Key Judgment: Operational overlap with the 2024 cluster is possible but not confirmed.
Estimative Term: Possibly (25-50%)
Evidence: Reported - overlapping infrastructure (PIV-008), similar lure themes (EV-022). Assessed - behavioral consistency with prior cluster by vendor B.
Assumptions: The infrastructure overlap is not due to shared hosting, tool resale, or deliberate false flag.
Alternatives: Separate actor reusing purchased tools; copycat campaign; coincidental infrastructure reuse via shared hosting provider.
Contradiction: Vendor C keeps the 2024 cluster and current activity separate with no published rationale.
Confidence: Low confidence — infrastructure overlap exists but is not exclusive. Contradiction from vendor C unresolved.
What Would Change It: Exclusive infrastructure link, common malware config seed not publicly available, or primary source linking operators.Practical Workflow
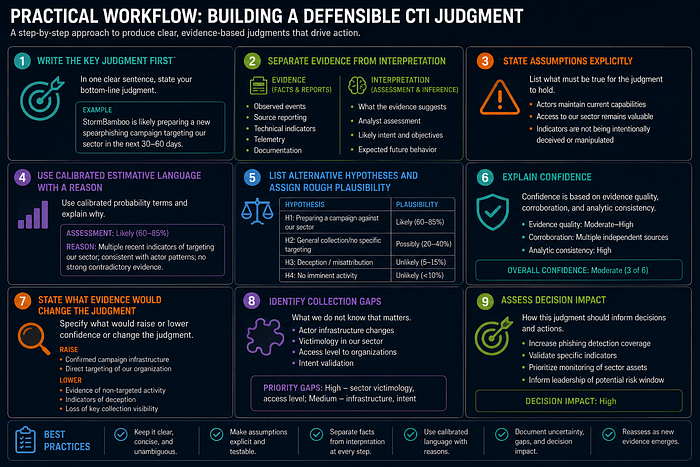
- Write the key judgment first in one sentence.
- Separate evidence (facts, reports) from interpretation (assessment, inference).
- State assumptions explicitly — what must be true for the judgment to hold.
- Use calibrated estimative language with a reason.
- List alternative hypotheses and assign rough plausibility.
- Explain confidence with evidence quality, corroboration, and analytic consistency.
- State what evidence would change the judgment.
- Identify collection gaps and decision impact.
Analyst Checklist
- Is the key judgment written as a single, testable sentence?
- Are facts, reporting, assessment, inference, assumptions, and gaps separated?
- Is the estimative term tied to a stated reason?
- Is confidence justified by evidence quality and corroboration?
- Are alternatives reviewed and their plausibility assessed?
- Is there at least one gap and collection task?
- Can a reader turn the output into a decision, hunt, detection, or collection task?
Estimative Language
Purpose
Provide practical wording for CTI judgments where evidence is incomplete, and enforce consistency so readers can interpret confidence correctly.
Practitioner-Level Explanation
Estimative language gives readers a controlled way to understand analytic judgment under uncertainty. Terms such as likely, possibly, consistent with, and insufficient evidence must be used consistently and with explicit reasons. Without discipline, these words become decoration rather than communication.
Avoid dramatic or vague words. "The actor is dangerous" is not an estimate. "The actor is likely to prioritize credential access and edge-device exploitation against exposed remote access services, based on two government advisories and consistent vendor reporting" is an estimate with traceable support.
Three rules:
- Every estimative term must be followed by a reason or it is decorative language, not analysis.
- Source reporting and local analyst assessment must be explicitly separated.
- The weakest defensible term is the correct term. Do not upgrade language to sound authoritative.
Calibrated Wording Reference
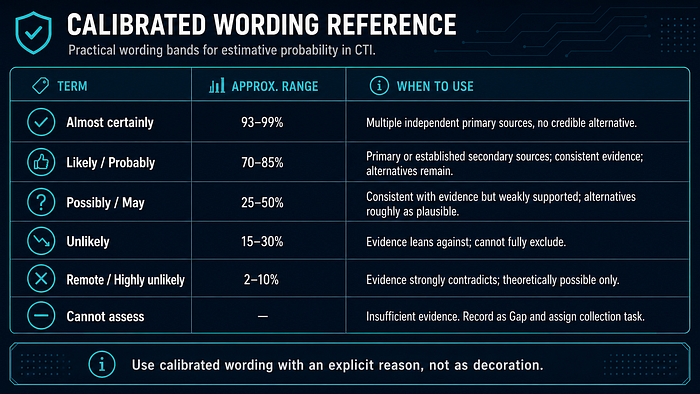
See Sherman Kent for CTI for the full calibration table and worked examples.
Bad Examples and Corrections
Bad Example 1 — "Likely" without explanation
The campaign likely targets critical infrastructure.Problem: The estimative term is asserted with no evidence, no source, no alternative.
Corrected:
Judgment: The campaign possibly targets critical infrastructure.
Evidence Label: Reported
Source: SRC-009 — vendor report citing two energy-sector victims.
Confidence: Low confidence — single-vendor reporting, no primary advisory, no local telemetry.
What Would Change It: Primary government advisory naming critical infrastructure victims, or observed targeting of this environment.Bad Example 2 — Passive language hiding the assessment owner
It is assessed that the malware is designed for long-term persistence.Problem: "It is assessed" hides who assessed it. Reader cannot evaluate whether this is source-reported or analyst-derived.
Corrected:
Reported: Vendor A assesses the malware is designed for long-term persistence (SRC-006).
Assessed-here: Consistent with observed behavior in public sandbox reports. The persistence mechanism is a scheduled task, which is detectable.Bad Example 3 — Mixing source assessment with local assessment
The actor probably has access to zero-day capabilities.Problem: It is unclear whether "probably" comes from a source or from the local analyst. If it is source language, it must be labeled Reported. If it is local assessment, the evidence must be stated.
Corrected:
Reported: Vendor B assesses the actor probably has access to zero-day capabilities, based on observed exploitation of a then-unpatched vulnerability (SRC-012). Evidence label: Reported.
Assessed-here: Local assessment deferred pending identification of a specific unpatched vulnerability in this environment. Gap: Unknown whether this actor has used zero-day techniques against our sector.Bad Example 4 — Using estimative language to avoid evidence
The actor may conduct future operations. The situation remains uncertain.Problem: This says nothing. "May" and "uncertain" require a reason and a scope. Without those, the statement is not intelligence.
Corrected:
No actionable intelligence judgment is possible on future targeting. The gap is recorded and assigned for collection. The next collection priority is: any primary source identifying the actor's 2026 infrastructure or target set.Practical Workflow

- Define the judgment in one sentence.
- Choose the weakest accurate estimative term.
- Attach the evidence label (Observed, Reported, Assessed, Inferred).
- State whether the assessment is source-reported or analyst-assessed.
- Record what evidence would strengthen or weaken it.
- Record the gap if evidence is insufficient for any useful estimate.
Analyst Checklist
- Is the estimative term necessary, or can the claim be stated as fact or gap?
- Can the reader distinguish source assessment from local assessment?
- Does the term match evidence strength?
- Is the reason for the term stated explicitly?
- Is the judgment actionable — does it support a decision, hunt, detection, or collection task?
Alternative Hypotheses
Purpose
Show how to document competing explanations before making CTI judgments.
Practitioner-Level Explanation
Alternative hypotheses protect analysts from premature closure. In CTI, the first plausible answer is often the wrong one or only one of several possible explanations.
A good alternative hypothesis is not a random possibility. It must explain the same evidence and be testable by additional collection.
CTI Relevance
Alternative hypotheses are essential for attribution, infrastructure clustering, persona claims, and interpreting campaign overlap.
Common Mistakes
- Writing only one hypothesis.
- Inventing alternatives that cannot be tested.
- Treating the best-known actor as the default answer.
- Failing to say what evidence would discriminate between hypotheses.
Practical Workflow

- State the main hypothesis.
- Write at least two alternatives.
- List evidence supporting and weakening each one.
- Identify discriminating evidence.
- Assign confidence and collection tasks.
- Update when new evidence arrives.
Example / Mini Case
Evidence shows a phishing lure, a cloud storage link, and PowerShell execution. Hypothesis 1: a tracked APT campaign. Hypothesis 2: commodity intrusion using similar tradecraft. Hypothesis 3: internal red-team or admin activity. Discriminating evidence includes infrastructure ownership, payload lineage, user targeting, and approved testing records.
Analyst Checklist
- Can each hypothesis explain the evidence?
- Is each hypothesis testable?
- Are discriminating indicators defined?
- Does the final judgment explain why alternatives were rejected or retained?
Assumptions and Gaps
Purpose
Define how to document assumptions and intelligence gaps so they improve analysis instead of weakening it invisibly.
Practitioner-Level Explanation
An assumption is something the analyst accepts temporarily to reason forward. A gap is information needed to answer the requirement but not currently available. Both must be visible.
A mature CTI product does not hide gaps. It explains whether the gap blocks the judgment, limits confidence, or creates a collection task.
CTI Relevance
Assumption and gap handling is essential for attribution, threat prioritization, infrastructure clustering, and detection engineering. It tells downstream teams what can be trusted and what still needs validation.
Common Mistakes
- Treating assumptions as facts.
- Using gaps as excuses to avoid judgment.
- Failing to distinguish blocking gaps from nice-to-have gaps.
- Not assigning owners or collection paths to gaps.
Practical Workflow

- List assumptions before writing the judgment.
- Identify gaps during source extraction.
- Classify gaps as blocking, confidence-limiting, or contextual.
- Assign collection options.
- Update the judgment if a key assumption fails.
Example / Mini Case
A report describes an actor targeting telecom providers. The analyst assumes similar exposure may exist in a local telecom environment. That assumption is acceptable only if labeled. The gap is whether the local environment has the same exposed service, telemetry, or supplier relationship.
Analyst Checklist
- Are assumptions explicitly named?
- Are gaps classified by impact?
- Is there a collection path?
- Does the confidence statement reflect the gaps?
- Are stale assumptions reviewed?
Contradiction Handling
Purpose
Provide a workflow for handling conflicting source claims without ignoring inconvenient evidence.
Practitioner-Level Explanation
Contradictions are normal in CTI. Vendors use different telemetry, naming, visibility, and confidence thresholds. A contradiction does not automatically invalidate both claims, but it does require structured handling.
The analyst should identify whether the contradiction is factual, taxonomic, temporal, or interpretive.
CTI Relevance
Contradiction handling prevents weak actor merges, stale claims, and detection work based on outdated assumptions.
Common Mistakes
- Choosing the source that matches the preferred narrative.
- Treating vendor naming differences as proof of different actors.
- Failing to account for time: both claims may have been true at different dates.
- Not recording contradiction status.
Practical Workflow
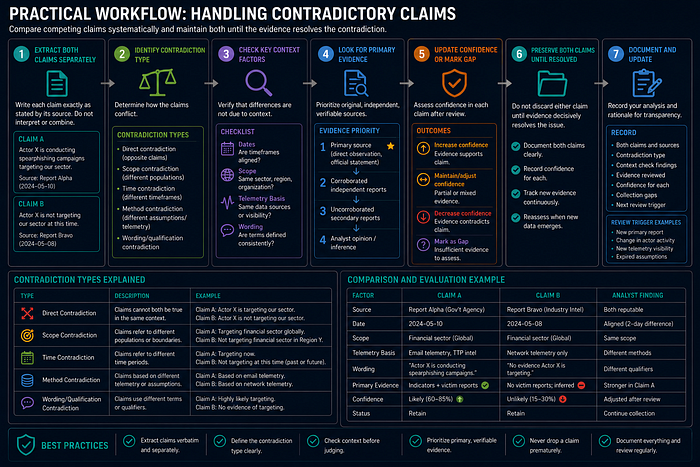
- Extract both claims separately.
- Identify contradiction type.
- Check dates, scope, telemetry basis, and wording.
- Look for primary evidence.
- Update confidence or mark Gap.
- Preserve both claims until resolved.
Example / Mini Case
Source A says a cluster is linked to one sponsor; Source B uses more cautious language. The correct output is not to average the claims. Record both, prefer the more precise primary evidence, and state whether the sponsor link is source-reported, assessed-by-source, or a local assessment.
Analyst Checklist
- Is the contradiction explicit?
- Are source dates compared?
- Is the stronger source identified with reasoning?
- Does the contradiction affect a downstream detection or report?
Analyst Checklist
Purpose
Provide a reusable pre-publication checklist for CTI outputs.
Practitioner-Level Explanation
The checklist is a quality-control tool. It should be used before publishing a report, updating an actor page, creating a hunt hypothesis, or briefing a decision-maker.
The point is not bureaucracy. The point is to catch unsupported claims, missing confidence reasons, unbounded pivots, and broken links before the output becomes operational guidance.
CTI Relevance
Consistent review improves trust between CTI, SOC, detection engineering, IR, and executive consumers.
Common Mistakes
- Reviewing only grammar and not evidence.
- Failing to check links and dates.
- Not testing whether the output answers the PIR.
- Treating the checklist as optional for urgent work.
Practical Workflow
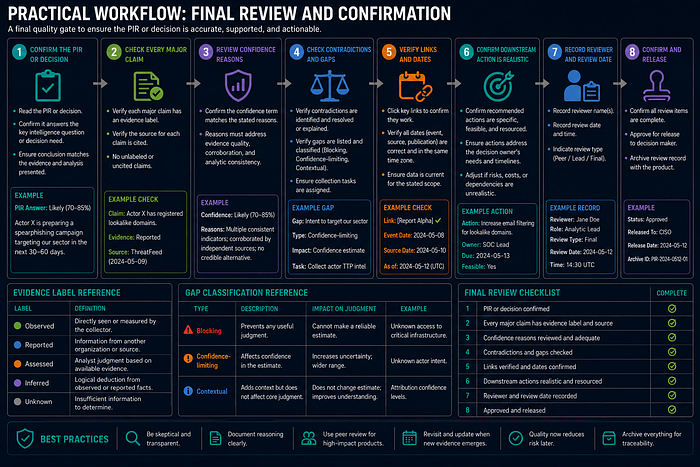
- Confirm the PIR or decision.
- Check every major claim for evidence label and source.
- Review confidence reasons.
- Check contradictions and gaps.
- Verify links and dates.
- Confirm downstream action is realistic.
- Record reviewer and review date.
Example / Mini Case
Before sending an executive note about a campaign, the analyst verifies that actor attribution is not based only on ATT&CK overlap, that the source is primary or clearly labeled as secondary, and that the recommendation is feasible for the SOC.
Analyst Checklist
- Does the output answer the requirement?
- Are major claims source-backed?
- Are gaps visible?
- Are cross-links working?
- Is the recommendation within scope and defensive?
Part 3: Frameworks
MITRE ATT&CK as a Working Tool
Purpose
Use ATT&CK to organize observed behavior and detection ideas without turning it into attribution evidence.
Practitioner-Level Explanation
ATT&CK is a behavior taxonomy. It helps analysts describe what happened, compare procedures, identify telemetry requirements, and communicate with detection engineers. It does not prove who performed the activity.
A useful mapping includes technique ID, technique name, tactic, procedure, evidence, source, confidence, mapping quality, detection idea, and limitations. Use the Israel CTI TTP To Detection Matrix for concrete examples. Actor-level mappings are weaker than procedure-level mappings tied to telemetry.
CTI Relevance
ATT&CK turns CTI into operational language for hunts, detections, and coverage discussions. It also reveals where reporting is too vague to support engineering.
Common Mistakes
- Mapping every sentence to a technique.
- Using ATT&CK overlap as attribution evidence.
- Ignoring sub-techniques and tactics.
- Claiming detection coverage because a technique appears in a profile.
Practical Workflow

- Extract a behavior, not an actor label.
- Identify the tactic and technique.
- Record the source and evidence label.
- Write the specific procedure.
- Define required telemetry.
- Add detection or hunt idea.
- Assign mapping quality and limitations.
Example / Mini Case
Weak: "Actor uses PowerShell: T1059.001."
Better: "Reported: actor used PowerShell launched from a shortcut to download a payload. Mapping: T1059.001, medium confidence. Detection idea: shortcut execution spawning powershell.exe with network activity. Limitation: source did not provide command-line examples."
Analyst Checklist
- Is the mapping behavior-based?
- Is the source and evidence label recorded?
- Does the mapping include a detection idea?
- Is mapping quality honest?
- Is attribution kept separate?
ATT&CK Mapping Mistakes
Purpose
List common ATT&CK errors that reduce CTI and detection-engineering quality.
Practitioner-Level Explanation
ATT&CK can improve precision, but bad mappings create false confidence. The most common failure is mapping broad actor reporting to a technique and presenting it as local detection coverage.
Good mapping is narrow, evidence-backed, and operationally testable.
CTI Relevance
This page helps reviewers challenge weak mappings before they become dashboards, coverage claims, or detection backlogs.
Common Mistakes
- Mapping actor names instead of behavior.
- Mapping malware capability instead of observed use.
- Ignoring data sources and telemetry requirements.
- Overusing high-level techniques when sub-techniques exist.
- Treating ATT&CK as an attribution engine.
Practical Workflow

- Start with a source claim.
- Extract a behavior.
- Choose the narrowest defensible technique.
- Record tactic, procedure, evidence, and confidence.
- Add telemetry requirements.
- Assign mapping maturity.
- Reject mappings that cannot be supported.
Example / Mini Case
A report says a tool can capture credentials. Do not map credential dumping unless the source reports observed credential dumping or analysis confirms capability and the page is explicit that the mapping is capability-based, not observed procedure.
Analyst Checklist
- Is this observed behavior or tool capability?
- Is the technique narrow enough?
- Is the mapping useful to a detection engineer?
- Is confidence justified?
- Would the mapping survive review?
Cyber Kill Chain
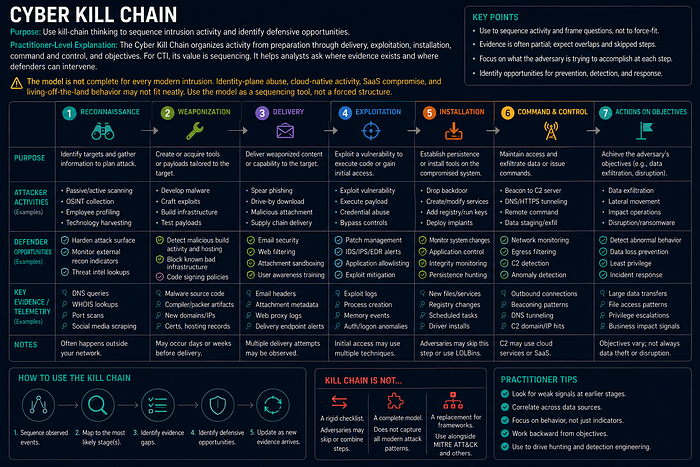
Purpose
Use kill-chain thinking to sequence intrusion activity and identify defensive opportunities.
Practitioner-Level Explanation
The Cyber Kill Chain organizes activity from preparation through delivery, exploitation, installation, command and control, and objectives. For CTI, its value is sequencing. It helps analysts ask where evidence exists and where defenders can intervene.
The model is not complete for every modern intrusion. Identity-plane abuse, cloud-native activity, SaaS compromise, and living-off-the-land behavior may not fit neatly. Use the model as a sequencing tool, not a forced structure.
CTI Relevance
Kill-chain analysis helps convert a long report into phases, observables, telemetry, and response opportunities.
Common Mistakes
- Forcing every campaign into every phase.
- Ignoring cloud and identity activity because it does not fit old phases.
- Using kill-chain phase names without observables.
- Failing to connect phases to controls.
Practical Workflow

- List observed or reported behaviors.
- Order them by likely sequence.
- Map each behavior to evidence and telemetry.
- Identify prevention, detection, and response opportunities.
- Record missing phases as gaps, not assumptions.
Example / Mini Case
A phishing campaign may have delivery evidence from email logs, execution evidence from endpoint telemetry, and C2 evidence from DNS logs. If no exploitation evidence exists, mark it as Gap rather than inventing a phase.
Analyst Checklist
- Does every phase have evidence or a gap label?
- Are identity and cloud actions represented?
- Are defensive controls mapped to phases?
- Is sequence confidence stated?
Diamond Model

Purpose
Use the Diamond Model to relate adversary, capability, infrastructure, and victim without overclaiming attribution.
Practitioner-Level Explanation
The Diamond Model helps structure CTI around four core features: adversary, capability, infrastructure, and victim. The strongest use is not drawing diagrams. The strongest use is testing whether links between features are supported.
An analyst can often know capability and infrastructure while adversary remains unknown. That is still useful CTI if the uncertainty is explicit.
CTI Relevance
The model is especially useful for infrastructure pivoting, actor clustering, and alternative hypotheses.
Common Mistakes
- Filling the adversary vertex because the diagram feels incomplete.
- Treating victimology as proof.
- Ignoring relationship strength between vertices.
- Failing to date infrastructure observations.
Practical Workflow

- Define the event or activity cluster.
- Populate known vertices only.
- Label unknown vertices as Unknown or Gap.
- Record evidence for each relationship.
- Assess relationship strength.
- Use the model to generate collection tasks.
Example / Mini Case
A domain, certificate, lure theme, and payload family may define a campaign cluster. The adversary remains Unknown. The next collection tasks are passive DNS, malware config review, lure recipient analysis, and overlap checks with known clusters.
Analyst Checklist
- Are all vertices evidence-labeled?
- Are relationship strengths documented?
- Are unknowns left unknown?
- Does the model generate collection tasks?
Pyramid of Pain

Purpose
Use the Pyramid of Pain to prioritize durable defensive intelligence over brittle indicators.
Practitioner-Level Explanation
The Pyramid of Pain ranks indicators by how disruptive they are for an adversary to change. Hashes and IPs are easy to rotate. Tools, network behaviors, and procedures are harder to change.
This does not mean low-level indicators are useless. They can support triage, scoping, and historical search. But durable detection engineering should move toward behavior and procedure whenever telemetry allows.
CTI Relevance
This framework helps CTI teams avoid over-investing in stale IOC feeds and under-investing in behavior-based hunts.
Common Mistakes
- Treating hashes as long-term detection strategy.
- Ignoring IOCs entirely.
- Failing to attach expiration and context to indicators.
- Calling behavior-based logic production-ready without testing.
Practical Workflow
- Classify indicators by level.
- Attach context, source, and expiration.
- Use hashes/IPs for triage and scoping.
- Derive behaviors and telemetry requirements.
- Convert durable behaviors into hunts or detections.
- Validate false positives.
Example / Mini Case
A malicious hash from a report is useful for immediate lookback. The stronger long-term detection may be the behavior: archive extraction followed by shortcut execution, script interpreter launch, and outbound connection to a new domain.
Analyst Checklist
- Are indicators contextualized?
- Is there an expiration date?
- Can a behavior be derived?
- Is telemetry available?
- Has the behavior been validated?
Part 4: Attribution
Attribution Methodology
Purpose
Provide a strict, evidence-weighted approach to CTI attribution.
Practitioner-Level Explanation
Attribution is a probabilistic analytic judgment. It is not a label copied from a report and not a result of one IOC match. A defensible attribution weighs timing, targeting, language, infrastructure, tooling, TTPs, operational tempo, malware lineage, and alternative hypotheses.
Shared tooling does not prove actor identity. Victimology is supporting evidence, not proof. Infrastructure overlap can be weak or strong depending on exclusivity, timing, and reuse.
CTI Relevance
Attribution affects response priority, legal/comms posture, executive reporting, and detection focus. Weak attribution can mislead all of those consumers.
Common Mistakes
- Attributing from a single IOC.
- Using ATT&CK overlap as proof.
- Ignoring false-flag and copycat possibilities.
- Failing to separate cluster, persona, sponsor, and public claim.
Practical Workflow

- Define what is being attributed: event, campaign, tool, infrastructure, persona, or sponsor.
- Collect evidence by category.
- Rate strength and reliability.
- Generate alternative hypotheses.
- Weigh contradictions.
- Assign confidence with reason.
- State limitations and what would change the judgment.
Example / Mini Case
A persona claims an attack on social media. Attribution to the persona is not the same as attribution to the operational cluster. The analyst records the public claim as Reported, seeks telemetry or third-party corroboration, and avoids sponsor attribution unless stronger evidence exists.
Analyst Checklist
- Is the attribution object clear?
- Are actor, persona, and sponsor separated?
- Is evidence multi-factor?
- Are alternatives documented?
- Is confidence justified?
Evidence Strength Ladder
Purpose
Rank attribution evidence by strength and limitations.
Practitioner-Level Explanation
Not all attribution evidence has equal weight. A reused IP address is weak by itself. A unique malware build, exclusive infrastructure, operator mistake, and corroborated victimology together are stronger.
The ladder helps analysts explain why a judgment is high, medium, or low confidence.
CTI Relevance
Evidence weighting prevents overclaiming and makes attribution review possible.
Common Mistakes
- Treating all overlaps as equal.
- Ignoring time windows.
- Not checking whether infrastructure is shared.
- Overweighting victimology.
Practical Workflow

- List evidence items.
- Classify each item by type.
- Assess exclusivity and timing.
- Identify benign or alternative explanations.
- Combine evidence only when relationships are valid.
- Document confidence impact.
Example / Mini Case
Weak evidence: same cloud provider, common tool, generic phishing theme. Stronger evidence: unique C2 path pattern, malware configuration overlap, repeated operator schedule, and corroborated targeting pattern.
Analyst Checklist
- Is the evidence exclusive?
- Is timing aligned?
- Could infrastructure be shared or resold?
- Does the evidence identify actor, tool, or only activity cluster?
Confidence vs Probability
Purpose
Explain why confidence and probability are different analytic concepts.
Practitioner-Level Explanation
Probability estimates likelihood. Confidence describes the strength and reliability of the analytic basis. A judgment may be assessed likely but low confidence if the evidence is thin. Another judgment may be unlikely but high confidence if strong evidence rules it out.
Most CTI products should use confidence language rather than precise percentages unless the organization has a calibrated probability model.
CTI Relevance
This distinction prevents decision-makers from misunderstanding how much trust to place in a CTI assessment.
Common Mistakes
- Using high confidence to mean high likelihood.
- Adding percentages without calibration.
- Failing to explain confidence reasons.
- Using low confidence as a reason to avoid action when impact is high.
Practical Workflow
- Write the judgment.
- Decide whether the output needs likelihood, confidence, or both.
- Explain evidence quality.
- Explain uncertainty.
- State decision impact.
Example / Mini Case
"We assess it is possible that this activity is related to Actor X, but confidence is low because the only overlap is commodity tooling and broad victimology."
Analyst Checklist
- Does the product confuse confidence and likelihood?
- Is a probability number necessary?
- Is confidence explained?
- Does the recommendation match risk and evidence?
False Flag Analysis
Purpose
Provide a practical method for evaluating deception, imitation, and persona manipulation.
Practitioner-Level Explanation
False flags range from deliberate deception to casual copying. CTI analysts should not assume every misleading signal is sophisticated deception. Many overlaps come from shared tools, public reporting, infrastructure reuse, affiliate models, or poor source visibility.
The analyst should ask what the signal is, who benefits if it is believed, and whether stronger evidence supports or contradicts it.
CTI Relevance
False-flag analysis is especially important for hack-and-leak personas, politically motivated claims, and public attribution debates.
Common Mistakes
- Assuming every inconsistency is deception.
- Ignoring mundane explanations like shared tooling.
- Amplifying persona claims without corroboration.
- Treating language artifacts as decisive.
Practical Workflow

- Identify the suspicious signal.
- List benign explanations.
- List deception hypotheses.
- Check evidence strength.
- Look for independent corroboration.
- State whether the signal affects attribution confidence.
Example / Mini Case
A claimed persona posts data allegedly from a victim. The correct response is to preserve the claim, avoid reposting sensitive content, check internal telemetry or trusted reporting, and record the claim separately from verified compromise.
Analyst Checklist
- Is the signal actually inconsistent?
- Are non-deceptive explanations considered?
- Is the claim separated from verified telemetry?
- Is public amplification avoided?
Attribution Worked Example
Purpose
Show a safe, defensive attribution workflow using public-style evidence categories.
Practitioner-Level Explanation
This worked example demonstrates method, not a definitive claim about a real incident. The scenario uses common CTI evidence categories: lure, tooling, infrastructure, targeting, timing, and public reporting.
The key lesson is that attribution should be built as a chain of evidence and alternatives, not as a label attached at the start.
CTI Relevance
Worked examples help analysts practice defensible reasoning before working on real incidents.
Common Mistakes
- Starting with the actor label.
- Ignoring alternatives.
- Treating similarity as identity.
- Skipping confidence explanation.
Practical Workflow

- Define the event.
- Record observed facts.
- Add source-reported context.
- Build candidate hypotheses.
- Weigh evidence.
- Write confidence-limited judgment.
- Define collection needed to improve confidence.
Example / Mini Case
Scenario: A phishing email delivers a script that downloads a payload from cloud storage. Public reporting says several actors use similar delivery. The analyst avoids attribution and instead assesses the activity as consistent with known tradecraft while recommending behavior-based hunting. Attribution remains Gap until infrastructure, malware configuration, or victimology is corroborated.
Analyst Checklist
- Are observations separated from public reporting?
- Are candidates compared fairly?
- Is the final assessment bounded?
- Are collection tasks specific?
Part 5: Infrastructure Pivoting
Single IOC to Network
Purpose
Explain how to pivot from one indicator to a bounded infrastructure hypothesis.
Practitioner-Level Explanation
A single IOC is a starting point, not a campaign; document it in an Infrastructure Pivot Log before expanding. Pivoting expands from a seed indicator to related domains, IPs, certificates, URLs, hosting, malware configs, and telemetry observations.
The analyst must define cluster boundaries and false-positive risk. Without boundaries, pivoting becomes uncontrolled graph expansion.
CTI Relevance
Infrastructure pivoting supports scoping, attribution hypotheses, detection ideas, and collection planning.
Common Mistakes
- Treating every shared IP neighbor as malicious.
- Ignoring time windows.
- Failing to separate infrastructure owner, hosting provider, and operator.
- Not recording why a pivot was accepted or rejected.
Practical Workflow
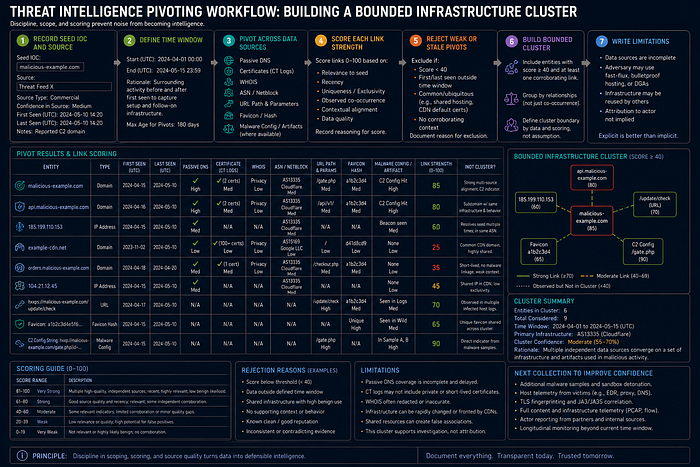
- Record the seed IOC and source.
- Define time window.
- Pivot through passive DNS, certificate, WHOIS, ASN, URL path, favicon, and malware config data where available.
- Score each link strength.
- Reject weak or stale pivots.
- Build a bounded cluster.
- Write limitations.
Example / Mini Case
A domain resolves to a shared hosting IP. Pivoting to every domain on that IP would create noise. A stronger pivot would require shared certificate attributes, unique URL paths, matching malware configuration, or close temporal overlap.
Analyst Checklist
- Is the seed source reliable?
- Is each pivot time-bounded?
- Are shared-hosting risks documented?
- Can the cluster be defended to a reviewer?
Passive DNS
Purpose
Use passive DNS safely to understand domain and IP relationships over time.
Practitioner-Level Explanation
Passive DNS shows observed relationships between domains and IP addresses. It is useful for timeline building and infrastructure clustering, but it is not proof of malicious control.
The most important controls are time window, source coverage, shared hosting awareness, and corroboration with other features.
CTI Relevance
Passive DNS helps identify campaign infrastructure, historical exposure, and possible related indicators for hunt scoping.
Common Mistakes
- Ignoring first-seen and last-seen dates.
- Pivoting across shared infrastructure without corroboration.
- Assuming passive DNS coverage is complete.
- Using stale resolutions as current indicators.
Practical Workflow

- Start with domain or IP.
- Record first-seen and last-seen dates.
- Identify co-resolutions and hosting context.
- Check for shared hosting or CDN.
- Corroborate with certificates, paths, configs, or telemetry.
- Expire stale indicators.
Example / Mini Case
A domain resolved to an IP used by many unrelated sites. Passive DNS alone is weak. If the same domain also shares a certificate subject pattern and malware config value with another domain, the cluster becomes stronger.
Analyst Checklist
- Are dates recorded?
- Is hosting context known?
- Are pivots corroborated?
- Are indicators expired when stale?
Certificates
Purpose
Use TLS certificate data as one feature in infrastructure clustering.
Practitioner-Level Explanation
Certificates can reveal domain relationships through subjects, issuers, SANs, serials, validity windows, and reuse patterns. Certificate pivots are stronger when the certificate is unusual, reused across a small set, and temporally aligned with activity.
They are weaker when using automated certificates, common issuers, or shared hosting platforms.
CTI Relevance
Certificate pivots support infrastructure clustering, detection enrichment, and timeline reconstruction.
Common Mistakes
- Pivoting on common certificate issuers.
- Ignoring automated certificate churn.
- Treating certificate reuse as actor identity.
- Not checking validity dates.
Practical Workflow

- Collect certificate fields.
- Check SANs and validity windows.
- Identify unusual reuse patterns.
- Compare with passive DNS and URL paths.
- Assess link strength.
- Document limitations.
Example / Mini Case
Two domains share a rare certificate subject and appeared within the same week. That is a moderate pivot if supported by similar URL paths or payload behavior. It is weak if both use common managed hosting and no other overlap exists.
Analyst Checklist
- Are certificate fields specific enough?
- Are validity dates aligned?
- Is reuse rare or common?
- Is there corroboration beyond the certificate?
ASN and Hosting Pivots
Purpose
Use hosting and ASN context without overclaiming malicious ownership.
Practitioner-Level Explanation
Hosting context tells the analyst where infrastructure lives and how easy it may be to rotate. ASN patterns can support clustering when paired with timing, provider selection, account artifacts, or repeated operational behavior.
An ASN is rarely a strong indicator by itself. Many actors and benign users share providers.
CTI Relevance
Hosting pivots support enrichment, blocking decisions, provider abuse reporting, and campaign infrastructure analysis.
Common Mistakes
- Blocking whole ASNs without business impact review.
- Treating provider preference as attribution.
- Ignoring VPS resale and compromised infrastructure.
- Not separating ingress, C2, staging, and redirector roles.
Practical Workflow

- Identify ASN and provider.
- Classify infrastructure role.
- Check historical actor/provider patterns.
- Look for account-level or configuration overlap.
- Assess collateral risk.
- Document whether the pivot is tactical or analytic.
Example / Mini Case
A campaign uses low-cost VPS providers across several countries. That supports an operational pattern but not actor identity. It may still guide firewall enrichment and short-term hunting.
Analyst Checklist
- Is the infrastructure role clear?
- Is provider overlap meaningful?
- Is collateral risk understood?
- Is the pivot corroborated?
Pivoting Limitations
Purpose
Document false-positive risks and analytic limits in infrastructure research.
Practitioner-Level Explanation
Infrastructure pivoting can create impressive graphs and weak intelligence. Shared hosting, CDNs, sinkholes, scanners, compromised sites, bulletproof hosting, reused kits, and affiliate ecosystems all complicate interpretation.
Every pivot should answer: what does this relationship prove, what does it not prove, and what additional evidence would strengthen it?
CTI Relevance
Limitations protect downstream teams from treating weak pivots as blocklists, attribution, or production detections.
Common Mistakes
- Graph expansion without stopping rules.
- Failing to document rejected pivots.
- Assuming infrastructure equals actor.
- Forgetting indicator expiration.
Practical Workflow
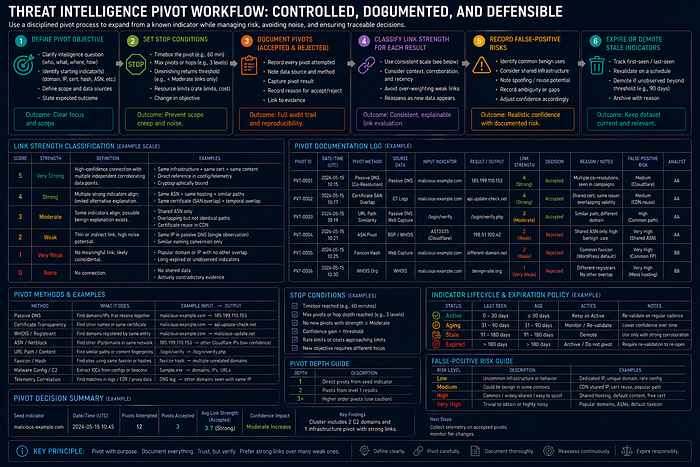
- Define pivot objective.
- Set stop conditions.
- Document accepted and rejected pivots.
- Classify link strength.
- Record false-positive risks.
- Expire or demote stale indicators.
Example / Mini Case
If a domain shares an IP with hundreds of unrelated domains, the pivot should usually stop unless another feature links a smaller subset. The output should say shared hosting prevents high-confidence clustering.
Analyst Checklist
- Are stop conditions defined?
- Are weak pivots rejected?
- Are false-positive risks named?
- Are indicators expired?
Infrastructure Pivoting Worked Case
Purpose
Provide a safe example of moving from one seed indicator to a bounded infrastructure cluster.
Practitioner-Level Explanation
This worked case uses generic, non-operational example values. It demonstrates documentation structure, not live tracking.
The method starts with one seed domain, checks passive DNS, certificates, URL paths, hosting, and telemetry, then accepts only corroborated relationships.
CTI Relevance
Worked cases help analysts learn when to stop pivoting and how to explain cluster boundaries.
Common Mistakes
- Using live malicious infrastructure in a training page.
- Failing to defang or sanitize examples.
- Accepting all graph neighbors.
- Not documenting rejected pivots.
Practical Workflow
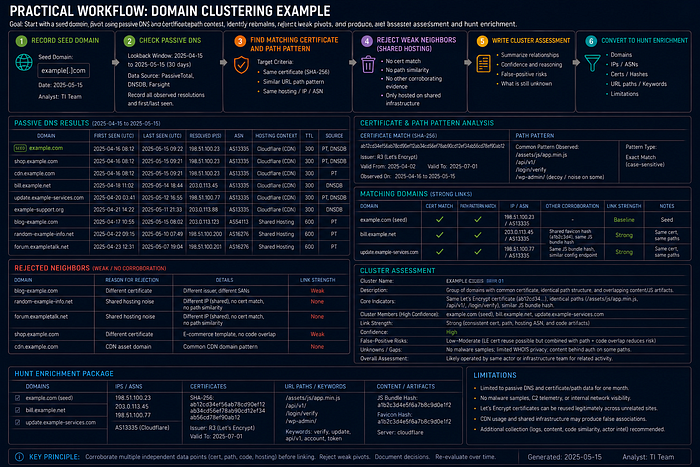
- Record seed domain example[.]com.
- Check passive DNS within the relevant month.
- Find two domains with matching certificate and path pattern.
- Reject shared-hosting neighbors with no corroboration.
- Write a cluster assessment.
- Convert to hunt enrichment with limitations.
Example / Mini Case
Seed: example[.]com. Passive DNS shows one IP with many unrelated domains. Certificate data identifies two domains with a matching SAN pattern and same validity window. Web path data shows both used /update/check during the same week. Assessment: bounded three-domain infrastructure cluster, medium confidence. Attribution remains Unknown.
Analyst Checklist
- Is the example sanitized?
- Are accepted pivots justified?
- Are rejected pivots listed?
- Is attribution avoided unless supported?
Part 6: Actor Research
Actor Profile Template
Purpose
Define the required sections for a professional actor profile.
Practitioner-Level Explanation
An actor profile is a decision-support artifact. It should not be a static encyclopedia page. It must explain what is known, who reported it, what is assessed, why it matters, what is detectable, and what remains unknown.
A good profile includes aliases, sponsor assessments, targeting, TTPs, tooling, infrastructure notes, evidence quality, relevance, hunting ideas, detection candidates, and freshness status.
CTI Relevance
Consistent actor profiles help CTI teams compare actors, prioritize research, and hand off useful content to detection and SOC teams.
Common Mistakes
- Writing actor pages as biographies instead of decision support.
- Merging vendor aliases without source confirmation.
- Using tool overlap as attribution proof.
- Omitting relevance to the defended environment.
- Failing to separate actor, persona, sponsor, and public claim.
Practical Workflow
- Create alias and source table.
- Add sponsor/attribution section with confidence.
- Write targeting and relevance.
- Add TTPs with evidence labels.
- Add tools with source and behavior.
- Add detections and hunts.
- Add gaps and review date.
Example / Mini Case
A profile for a destructive persona should include a persona-claims section rather than mixing all public claims into confirmed incidents.
Analyst Checklist
- Are aliases source-confirmed?
- Are sponsor and attribution claims evidence-labeled?
- Are behaviors mapped to TTPs only when supported?
- Are detection and hunting implications included?
- Are gaps explicit?
Actor Update Workflow
Purpose
Provide a repeatable process for refreshing actor profiles without source drift or overclaiming.
Practitioner-Level Explanation
Actor profiles decay. Aliases change, sponsor language evolves, tools are reclassified, and old IOCs become stale. Updates need a workflow, not ad hoc edits.
Every update should identify what changed, what source supports it, what confidence changed, and which downstream hunts, detections, or reports are affected.
CTI Relevance
Actor update discipline keeps CTI repositories accurate and prevents stale actor pages from driving bad detection priorities.
Common Mistakes
- Adding new reports without updating old contradictions.
- Changing sponsor language without source support.
- Leaving detections linked to deprecated claims.
- Failing to mark old IOCs as stale.
Practical Workflow
- Check latest primary sources.
- Compare against existing profile.
- Add new claims to evidence register.
- Update aliases and sponsor language only with sources.
- Review TTP and tool mappings.
- Check affected detections and hunts.
- Record changelog and review date.
Example / Mini Case
A new source reports a tool previously associated with one actor under a different cluster. The analyst records the contradiction, updates confidence, and marks affected detections as behavior-based rather than actor-specific.
Analyst Checklist
- Is the update source-backed?
- Are contradictions recorded?
- Are downstream links reviewed?
- Is the review date updated?
MuddyWater / Seedworm
Purpose
Show how to structure an actor research page for a mature Iran-nexus intrusion cluster without overclaiming every reported activity.
Practitioner-Level Explanation
A MuddyWater / Seedworm profile should be built around behavior, source chronology, targeting, tooling, and operational relevance. The analyst should separate long-term public reporting from current campaign evidence and avoid treating every PowerShell or remote-management-tool event as MuddyWater.
The practical value of the profile is not the name. It is a set of behaviors that can become collection requirements, hunts, detection candidates, and customer-facing risk judgments.
CTI Relevance
MuddyWater is a useful training case because public reporting frequently connects it to phishing, living-off-the-land tradecraft, remote management tooling, credential access, and Middle East targeting. It demonstrates how actor knowledge becomes defensive action.
Common Mistakes
- Writing actor pages as biographies instead of decision support.
- Merging vendor aliases without source confirmation.
- Using tool overlap as attribution proof.
- Omitting relevance to the defended environment.
- Failing to separate actor, persona, sponsor, and public claim.
Practical Workflow
- Create an alias table with source for each alias.
- Build a source chronology.
- Extract behaviors into evidence rows.
- Separate tooling capability from observed use.
- Map only supported ATT&CK techniques.
- Write hunt hypotheses tied to telemetry.
- Document gaps and freshness date.
Example / Mini Case
A source reports phishing that leads to remote management tool installation. The actor page should not say "detect MuddyWater." It should say: hunt for newly installed RMM tooling on non-IT endpoints after suspicious email activity, with local baselining and false-positive review.
Analyst Checklist
- Are aliases source-confirmed?
- Are sponsor and attribution claims evidence-labeled?
- Are behaviors mapped to TTPs only when supported?
- Are detection and hunting implications included?
- Are gaps explicit?
APT41 / Operation DragonRx
Purpose
Show how to transform a public actor case study into a defensible CTI-to-detection workflow.
Practitioner-Level Explanation
APT41 / DragonRx is useful as a worked teaching theme because it can connect public reporting, exploitation chains, enterprise compromise, pharmaceutical-sector relevance, ATT&CK mapping, and detection engineering.
The page should focus on tradecraft method: how to extract behaviors, avoid over-attribution, map telemetry, and produce hunt/detection outputs from a public case.
CTI Relevance
This case demonstrates how a sector-specific intrusion narrative becomes practical analyst outputs: timeline, TTP table, telemetry requirements, detections, SOC handoff, and executive risk statement.
Common Mistakes
- Writing actor pages as biographies instead of decision support.
- Merging vendor aliases without source confirmation.
- Using tool overlap as attribution proof.
- Omitting relevance to the defended environment.
- Failing to separate actor, persona, sponsor, and public claim.
Practical Workflow
- Summarize the public case without copying it.
- Extract behavior sequence.
- Rate sources and evidence.
- Map techniques cautiously.
- Identify telemetry needed.
- Draft detection and triage outputs.
- Write executive relevance.
Example / Mini Case
A public report describes exploitation leading to domain compromise. The field-manual output turns that into a sequence: exposed application, suspicious child processes, credential access indicators, lateral movement, staging, and response requirements. Attribution remains evidence-labeled and not dependent on ATT&CK overlap.
Analyst Checklist
- Are aliases source-confirmed?
- Are sponsor and attribution claims evidence-labeled?
- Are behaviors mapped to TTPs only when supported?
- Are detection and hunting implications included?
- Are gaps explicit?
Handala / Void Manticore Research Method
Purpose
Use Handala as a model for separating public persona claims from operational cluster assessment.
Practitioner-Level Explanation
Handala / Void Manticore reporting requires strict persona discipline. A public claim, a Telegram post, a defacement message, a leaked-data claim, and a verified intrusion are different evidence classes.
The analyst should treat Handala as a claim-heavy persona unless stronger sources connect a specific operation to a tracked cluster such as Void Manticore. Do not repost leaked material; use false-flag and persona-claim handling instead. Do not treat persona messaging as telemetry.
CTI Relevance
This case is valuable because modern CTI must handle psychological operations, hack-and-leak claims, and destructive narratives without becoming an amplifier.
Common Mistakes
- Writing actor pages as biographies instead of decision support.
- Merging vendor aliases without source confirmation.
- Using tool overlap as attribution proof.
- Omitting relevance to the defended environment.
- Failing to separate actor, persona, sponsor, and public claim.
- Amplifying claims that are intended to create fear.
- Treating claimed victim lists as verified compromise.
Practical Workflow
- Capture the public claim metadata without sensitive content.
- Check internal telemetry and trusted third-party corroboration.
- Separate persona, cluster, sponsor, and victim claims.
- Record confidence and gaps.
- Recommend comms/SOC/legal handling separately.
Example / Mini Case
A persona claims to have breached a public-sector organization. The CTI output records the claim, source channel, date, and claimed sector. Verification remains Gap until telemetry or trusted reporting confirms compromise. The SOC action is scoped triage, not public amplification.
Analyst Checklist
- Are aliases source-confirmed?
- Are sponsor and attribution claims evidence-labeled?
- Are behaviors mapped to TTPs only when supported?
- Are detection and hunting implications included?
- Are gaps explicit?
- Is leaked or sensitive content excluded?
- Is the public claim separated from verified compromise?
Part 7: Sector CTI
Cellular Provider Case Study
Purpose
Provide a structured defensive CTI workflow for a fictional cellular provider.
Practitioner-Level Explanation
The case study models a realistic CTI engagement without exposing a real victim. It starts with crown jewels, dependencies, PIRs, source collection, threat scenarios, telemetry readiness, hunts, detections, SOC handoff, and executive reporting.
The purpose is to show how CTI becomes operational decisions.
CTI Relevance
Case studies let analysts practice customer-specific relevance instead of generic actor summaries.
Common Mistakes
- Writing sector CTI as generic threat landscape prose.
- Not connecting threats to assets and dependencies.
- Ignoring telemetry and control realities.
- Overstating public evidence about successful compromise.
Practical Workflow
- Define business functions.
- Identify crown jewels and dependencies.
- Write PIRs and SIRs.
- Map relevant actors and behaviors.
- Score threat scenarios.
- Assess telemetry readiness.
- Create hunts and detection backlog.
- Write SOC and executive outputs.
Example / Mini Case
Scenario: supplier VPN credentials are abused to access telecom management systems. CTI output identifies identity logs, VPN logs, privileged session monitoring, supplier contact path, and escalation criteria.
Analyst Checklist
- Are assets and dependencies defined?
- Are threats tied to observable behavior?
- Are sector-specific false positives considered?
- Are source limits explicit?
Telecom 4G Threats
Purpose
Frame 4G telecom CTI around assets, dependencies, attack surfaces, and defensive outputs.
Practitioner-Level Explanation
4G telecom CTI requires understanding both enterprise IT and telecom-specific systems. Public CTI often mentions telecom targeting without proving compromise of core network elements. Analysts must separate corporate IT compromise, subscriber-data exposure, signaling-plane risk, lawful intercept risk, and supplier exposure.
The manual approach is to map assets and dependencies first, then connect public reporting to plausible observables.
CTI Relevance
Telecom networks are high-value targets for espionage, disruption, fraud, and strategic access. CTI must be precise enough for network, SOC, and executive teams.
Common Mistakes
- Writing sector CTI as generic threat landscape prose.
- Not connecting threats to assets and dependencies.
- Ignoring telemetry and control realities.
- Overstating public evidence about successful compromise.
Practical Workflow
- Define telecom assets and crown jewels.
- Separate IT, OSS/BSS, RAN, core, signaling, and supplier access.
- Map public reporting to asset exposure.
- Identify telemetry owners.
- Create sector-specific hunt hypotheses.
- Document gaps where public evidence is insufficient.
Example / Mini Case
A report says an actor targets telecoms. The analyst does not assume SS7 compromise. The output asks whether exposed VPNs, admin jump hosts, OSS/BSS portals, or supplier remote access create observable risk.
Analyst Checklist
- Are assets and dependencies defined?
- Are threats tied to observable behavior?
- Are sector-specific false positives considered?
- Are source limits explicit?
Telecom 5G Threats
Purpose
Explain how 5G changes CTI questions around cloud-native telecom, slicing, suppliers, and identity.
Practitioner-Level Explanation
5G introduces cloud-native infrastructure, virtualization, APIs, orchestration, slicing, and expanded supplier dependencies. CTI must consider identity, management planes, cloud platforms, container workloads, and telecom-specific control-plane functions.
The analyst should avoid generic "5G is critical" language and instead define concrete assets and telemetry.
CTI Relevance
5G CTI is useful when it connects threat reporting to management-plane abuse, supplier access, cloud posture, API exposure, and resilience planning.
Common Mistakes
- Writing sector CTI as generic threat landscape prose.
- Not connecting threats to assets and dependencies.
- Ignoring telemetry and control realities.
- Overstating public evidence about successful compromise.
Practical Workflow
- Inventory 5G management and orchestration layers.
- Identify supplier and remote-admin dependencies.
- Map threat reporting to identity, API, cloud, and network telemetry.
- Separate theoretical risk from observed exploitation.
- Build collection gaps.
Example / Mini Case
A supplier compromise scenario may be more practical than a radio-interface scenario. The hunt may focus on privileged access to orchestration consoles, unusual API calls, and changes to network function configurations.
Analyst Checklist
- Are assets and dependencies defined?
- Are threats tied to observable behavior?
- Are sector-specific false positives considered?
- Are source limits explicit?
Israel Public-Sector Notes
Purpose
Explain how to use Israel-focused CTI responsibly from a general analyst field manual.
Practitioner-Level Explanation
Israel public-sector CTI has a specific threat context, but the same tradecraft rules apply: evidence labels, source reliability, persona caution, attribution discipline, and detection validation.
This page points to the dedicated Israel Government Threat Actors CTI project for actor-specific details rather than duplicating that knowledge base.
CTI Relevance
Public-sector defenders need clear separation between strategic context, verified incidents, persona claims, and practical defensive actions.
Common Mistakes
- Writing sector CTI as generic threat landscape prose.
- Not connecting threats to assets and dependencies.
- Ignoring telemetry and control realities.
- Overstating public evidence about successful compromise.
- Duplicating the Israel actor knowledge base instead of linking to it.
- Treating politically charged claims as verified incidents.
Practical Workflow
- Start with the Israel CTI threat model.
- Use actor pages for specific clusters.
- Check evidence labels and source quality.
- Convert relevant behaviors into hunts or detection backlog items.
- Keep public claims separate from verified compromise.
Example / Mini Case
A hacktivist-style persona claims a municipal breach. The analyst uses the Israel CTI persona workflow, checks corroboration, and gives the SOC a scoped triage path rather than treating the claim as confirmed.
Analyst Checklist
- Are assets and dependencies defined?
- Are threats tied to observable behavior?
- Are sector-specific false positives considered?
- Are source limits explicit?
Part 8: CTI to Detection
Intelligence to Detection
Purpose
Convert CTI claims into telemetry requirements, hunts, detections, SOC actions, and validation plans.
Practitioner-Level Explanation
CTI-to-detection is a chain, not a single translation step; the Customer project turns that chain into delivery gates. A source reports behavior. The analyst labels evidence, assesses relevance, identifies telemetry, writes a hunt hypothesis, validates false positives, and only then promotes detection logic.
The actor name is usually less important than the behavior and observable; use the Israel CTI Actor Workbench only after evidence is labeled.
CTI Relevance
This workflow is the bridge between CTI and operational defense. It makes intelligence useful to detection engineering and SOC teams.
Common Mistakes
- Jumping from actor report to production alert.
- Skipping telemetry requirements.
- Ignoring false positives and tuning.
- Claiming coverage without validation.
Practical Workflow
- Extract behavior from source reporting.
- Label evidence and confidence.
- Assess environment relevance.
- Define required telemetry and fields.
- Write a testable hunt hypothesis.
- Baseline benign behavior.
- Draft detection logic.
- Validate positive and negative cases.
- Create SOC handoff.
- Assign detection readiness level.
Example / Mini Case
Reported behavior: archive attachment leads to script execution and external download. Detection chain: email attachment metadata, endpoint archive extraction, script process creation, network connection, false-positive baseline for admin scripts, SOC triage instructions.
Analyst Checklist
- Is there a source-backed behavior?
- Is telemetry available?
- Is the hypothesis testable?
- Are false positives named?
- Is readiness level honest?
Detection Readiness Levels
Purpose
Define a practical DRL model so CTI-derived detections are not marketed as production coverage before validation.
Core Rule
Only DRL-9 can be called production detection coverage. Anything below DRL-9 is research, candidate logic, hunt content, pilot content, or validation work.
DRL Scale
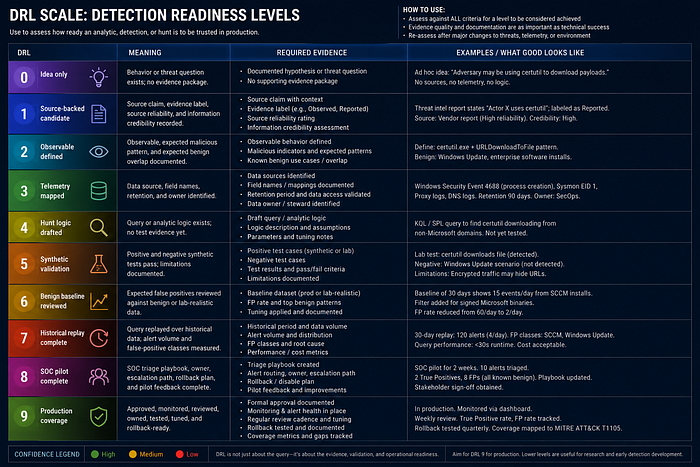
Required Validation Artifacts
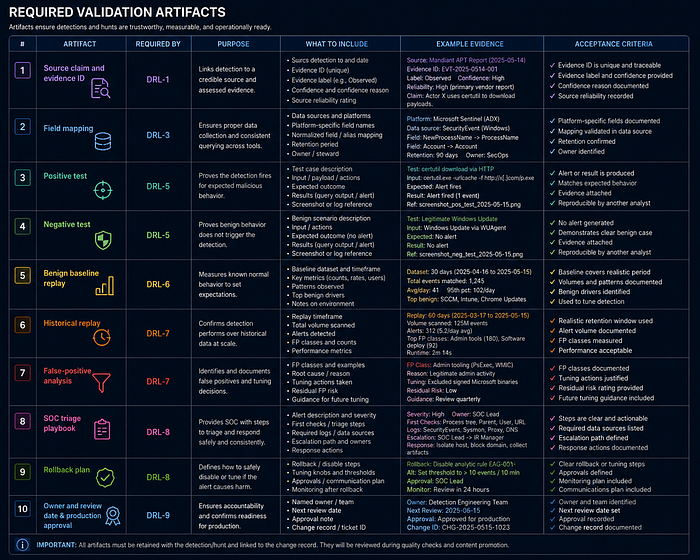
Examples
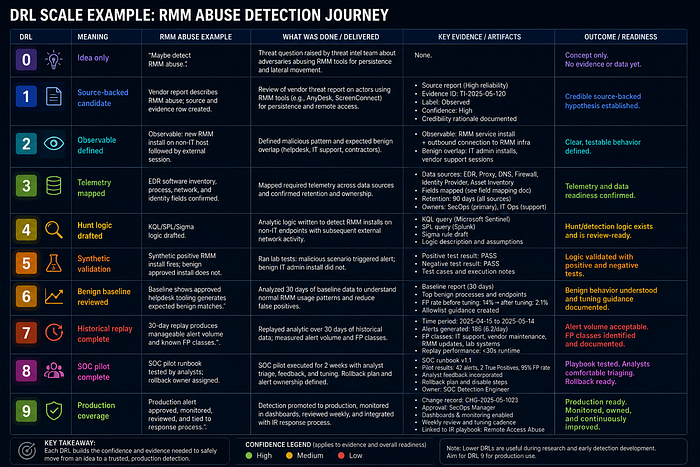
Bad Example / Corrected Example
Bad:
The rule is mapped to ATT&CK, so production coverage exists.Corrected:
The rule is DRL-4. It has behavior-backed ATT&CK mapping and draft logic, but no positive test, negative test, benign baseline, historical replay, SOC pilot, or production approval.Full SOC Handoff Example
Handoff ID: SOC-RMM-001
Detection: New RMM installation on non-IT host followed by external remote session
DRL: 8 during pilot
Why it matters: Source-backed adversary behavior overlaps with unauthorized remote control.
First checks:
- Confirm host owner and business role.
- Check software approval and change ticket.
- Review parent process and install source.
- Review identity session, source IP, MFA state, and remote session destination.
- Check email/web activity in the preceding 24 hours.
Required logs: EDR process, software inventory, network, identity, helpdesk ticketing.
False positives: Helpdesk deployment, vendor support, IT migration, approved remote work.
Escalation threshold: No ticket plus unknown source plus external remote session plus suspicious pre-install activity.
Response: Follow IR policy; do not isolate critical systems without incident commander approval.
Rollback: Disable alert or add approved deployment group if false-positive rate exceeds pilot threshold.
Owner: Detection Engineering
Review date: 2026-06-16Telemetry Requirements
Purpose
Define the logs, fields, retention, and quality needed before a hunt or detection can be trusted.
Practitioner-Level Explanation
Detection quality depends on telemetry quality. A good CTI-derived detection states exactly which data sources and fields are required, what retention is needed, and where visibility gaps exist. Write telemetry requirements before detection logic, not after. Logic written against fields that do not exist is not detection — it is a placeholder.
Field-Level Telemetry Reference
The tables below list the data sources most commonly required for endpoint, network, identity, and cloud hunts. Every field must be validated in your environment before it appears in production detection logic.
Windows Security Event Log
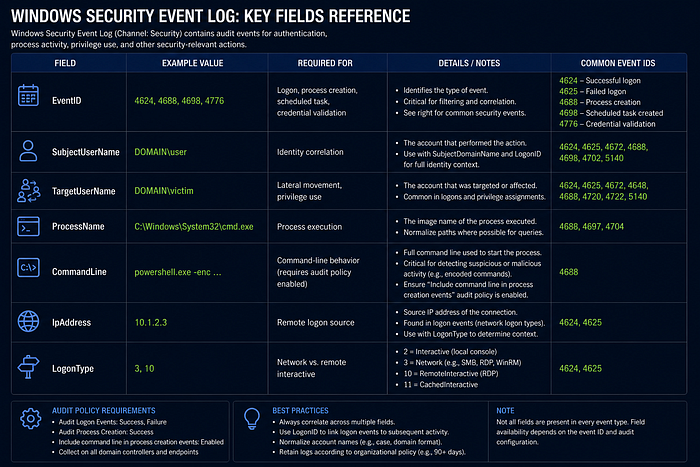
Common gap: CommandLine is not logged by default on most Windows versions. Requires Audit Process Creation with command-line inclusion via GPO or registry.
Sysmon (System Monitor)
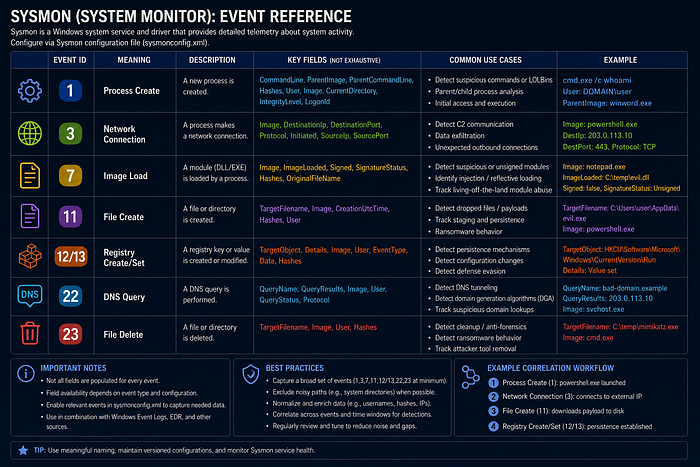
Common gap: Sysmon is not deployed by default. Configuration must enable the required event types and filters. Noisy rules without filters will generate excessive volume and cause tuning paralysis.
EDR Process Telemetry (platform-generic)
Common gap: Parent process chain may not be available in all EDR configurations. Verify whether your EDR records grandparent process context.
DNS Telemetry
Common gap: DNS logging is frequently incomplete. Recursive resolvers may not log internal resolution. Encrypted DNS (DoH, DoT) bypasses traditional DNS logging entirely.
Proxy / Web Gateway
Common gap: TLS inspection may not be enabled, making encrypted channel contents invisible. User-agent fields can be spoofed and should not be used as primary detection criteria.
Identity Provider (Entra ID / Okta / similar)

Common gap: Legacy authentication protocols may not log MFA result or conditional access enforcement.
Cloud Audit Logs (AWS CloudTrail / Azure Monitor / GCP Audit Logs)
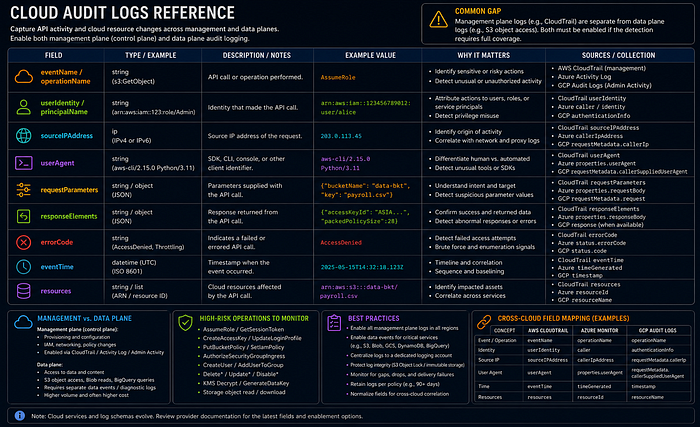
Common gap: Management plane logs (e.g., CloudTrail) are separate from data plane logs (e.g., S3 object access). Both must be enabled if the detection requires full coverage.
CTI Relevance
This prevents detection engineering from building fragile rules against unavailable, inconsistent, or low-quality data. Every detection candidate must identify which data source, which fields, and what retention window are required before the rule is drafted.
Common Mistakes
- Assuming fields are available because the data source exists.
- Using generic field names without platform-specific validation.
- Skipping retention and latency checks.
- Building detection logic before confirming command-line or parent-process fields are populated.
- Treating DNS or proxy logs as complete when TLS or DoH is in use.
Practical Workflow
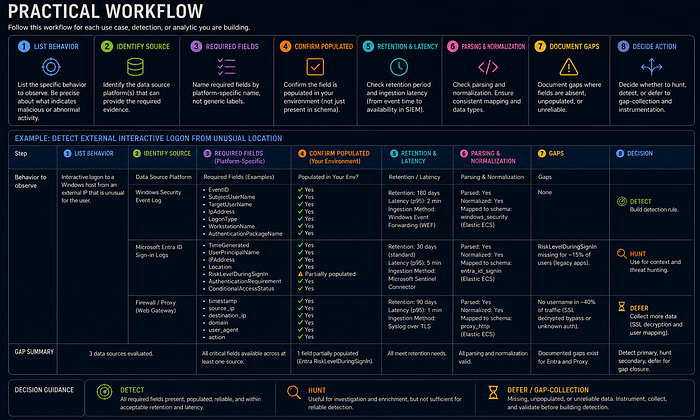
- List the specific behavior to observe.
- Identify the data source platform.
- Name required fields by platform-specific name, not generic label.
- Confirm field is populated in your environment (not just present in schema).
- Check retention period and latency.
- Check parsing and normalization.
- Document gaps where fields are absent, unpopulated, or unreliable.
- Decide whether to hunt, detect, or defer to gap-collection.
Example: Telemetry Map for RMM Abuse Behavior
Behavior: New RMM tool installed on non-IT endpoint followed by external remote session.
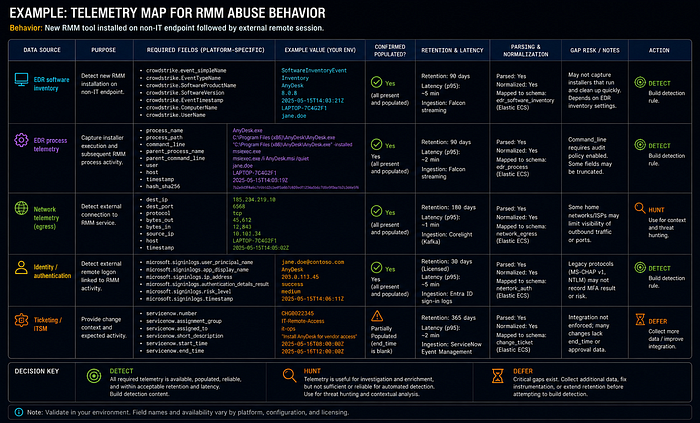
Analyst Checklist
- Is each required field validated as populated in the target environment?
- Is retention sufficient for the lookback window?
- Are command-line and parent-process fields confirmed?
- Are encrypted channel or DoH gaps documented?
- Is a gap registered for any required field that is missing?
- Is readiness level honest?
Hunting Hypothesis Template
Purpose
Define a falsifiable hunt hypothesis format for CTI-driven threat hunting.
Practitioner-Level Explanation
A hunt hypothesis is a testable statement about adversary behavior in an environment. It should include behavior, telemetry, lookback window, expected malicious pattern, expected benign pattern, false positives, stop condition, and escalation path.
A hunt is not a keyword search. It is an investigation plan.
CTI Relevance
Hypotheses make CTI actionable without prematurely creating noisy alerts.
Common Mistakes
- Jumping from actor report to production alert.
- Skipping telemetry requirements.
- Ignoring false positives and tuning.
- Claiming coverage without validation.
Practical Workflow

- Start with a source-backed behavior.
- Define why the behavior matters locally.
- List required logs and fields.
- Set lookback window.
- Define malicious and benign patterns.
- Run and tune.
- Record findings and next action.
Example / Mini Case
Hypothesis: If an actor abuses RMM tooling after phishing, then non-IT endpoints may show new RMM installation followed by remote session activity within 24 hours of suspicious email receipt.
Analyst Checklist
- Is there a source-backed behavior?
- Is telemetry available?
- Is the hypothesis testable?
- Are false positives named?
- Is readiness level honest?
Detection Backlog
Purpose
Organize CTI-derived detection candidates by value, evidence, telemetry, readiness, and validation state.
Practitioner-Level Explanation
A detection backlog is not a wish list; compare maturity against the Israel CTI Detection Status Dashboard. Each item should record source behavior, evidence, expected value, telemetry dependency, false-positive risk, owner, readiness level, and promotion criteria. Backlog discipline prevents teams from losing good hypotheses or promoting immature logic too early.
CTI Relevance
Backlogs connect CTI priorities to engineering capacity and SOC readiness.
Common Mistakes
- Jumping from actor report to production alert.
- Skipping telemetry requirements.
- Ignoring false positives and tuning.
- Claiming coverage without validation.
Practical Workflow

- Create one row per detection idea.
- Link source and evidence.
- Record telemetry dependency.
- Score value and feasibility.
- Assign owner and readiness.
- Track testing and false positives.
- Promote, defer, or retire.
Example / Mini Case
A backup-deletion behavior may be high impact but blocked by missing process telemetry. The backlog item remains Hunt or Design until telemetry exists and tests are completed.
Analyst Checklist
- Is there a source-backed behavior?
- Is telemetry available?
- Is the hypothesis testable?
- Are false positives named?
- Is readiness level honest?
Sigma, KQL, and SPL Examples
Purpose
Show how to express detection logic across platforms while marking each example honestly with its DRL level and validation requirements.
Core Rule
Platform syntax is implementation detail. The analytic logic must exist first: behavior, telemetry, fields, false positives, and validation. Every example below is a DRL-4 candidate — draft logic only. None are production-ready without positive test, negative test, benign baseline, historical replay, SOC pilot, and production approval.
How to Read These Examples
Each example includes:
- Behavior: What the detection targets.
- Source behavior: CTI claim that justifies the detection.
- DRL: Current readiness level.
- False positives: Known benign matches.
- Validation required: What must happen before promotion.
Example 1: Script Interpreter Spawned from Archive Extraction
Behavior: A compressed archive is extracted and immediately spawns a scripting engine. This is a common pattern for phishing payload delivery.
Source behavior: Reported — multiple vendor reports describe archive-attached phishing leading to PowerShell, wscript, or cscript execution. No local telemetry confirmation.
DRL: 4 — draft logic, no test evidence.
False positives: Admin deployment packages, software installers with embedded scripts, developer tooling.
Validation required: Positive synthetic test (simulate archive + script spawning), negative test (confirm legitimate installer does not fire), benign baseline review, historical replay.
Sigma (DRL-4 candidate — not production)
title: Archive Extraction Followed by Script Interpreter — DRL-4 Candidate
status: experimental
description: >
Detects a scripting engine (PowerShell, wscript, cscript, mshta) spawned as a child
of a known archive extraction utility. DRL-4 draft only. Requires positive/negative
testing, benign baseline review, and SOC pilot before promotion.
references:
- https://attack.mitre.org/techniques/T1059/001/
author: CTI Analyst Field Manual
date: 2026-05-16
tags:
- attack.execution
- attack.t1059.001
- drl.4.candidate
logsource:
category: process_creation
product: windows
detection:
selection_parent:
ParentImage|endswith:
- '\7z.exe'
- '\WinRAR.exe'
- '\msiexec.exe'
- '\expand.exe'
selection_child:
Image|endswith:
- '\powershell.exe'
- '\pwsh.exe'
- '\wscript.exe'
- '\cscript.exe'
- '\mshta.exe'
condition: selection_parent and selection_child
falsepositives:
- Software installation packages that extract and execute setup scripts
- Admin automation tools using archive-based deployment
- Developer tooling
level: mediumKQL — Microsoft Defender for Endpoint (DRL-4 candidate — not production)
// DRL-4 candidate — not production
// Requires telemetry validation: confirm ParentProcessName is populated
// Validate positive/negative cases before enabling as alert
DeviceProcessEvents
| where Timestamp > ago(7d)
| where InitiatingProcessFileName in~ ("7z.exe", "WinRAR.exe", "msiexec.exe", "expand.exe")
| where FileName in~ ("powershell.exe", "pwsh.exe", "wscript.exe", "cscript.exe", "mshta.exe")
| project Timestamp, DeviceName, AccountName,
InitiatingProcessFileName, InitiatingProcessCommandLine,
FileName, ProcessCommandLine, FolderPath
| order by Timestamp descSPL — Splunk with Sysmon (DRL-4 candidate — not production)
`sysmon` EventCode=1
(ParentImage="*\\7z.exe" OR ParentImage="*\\WinRAR.exe" OR ParentImage="*\\msiexec.exe")
(Image="*\\powershell.exe" OR Image="*\\wscript.exe" OR Image="*\\cscript.exe" OR Image="*\\mshta.exe")
| table _time, host, User, ParentImage, ParentCommandLine, Image, CommandLine
| sort -_timeExample 2: Non-Browser Process Outbound on IMAPS / SMTPS
Behavior: A non-browser, non-mail-client process opens an outbound connection on TCP 993 (IMAPS) or TCP 465/587 (SMTPS). This is a C2 exfiltration pattern that abuses email protocols.
Source behavior: Reported — public CTI describes email-protocol C2 used by several threat clusters for data staging. Evidence label: Reported. Confidence: Medium (multi-vendor, no local telemetry confirmation).
DRL: 4 — draft logic, no test evidence.
False positives: Mail clients, backup tools, developer SMTP testing, monitoring agents.
Validation required: Positive test with netcat or mail client connecting on 993/465, negative test confirming Outlook or Thunderbird does not fire, baseline review of legitimate mail clients.
Sigma (DRL-4 candidate — not production)
title: Non-Browser Process Outbound IMAPS or SMTPS — DRL-4 Candidate
status: experimental
description: >
Detects a process connecting outbound on IMAPS (993) or SMTPS (465, 587) that is
not a known mail client or browser. C2 via email protocol. DRL-4 draft only.
references:
- https://attack.mitre.org/techniques/T1071/003/
author: CTI Analyst Field Manual
date: 2026-05-16
tags:
- attack.command_and_control
- attack.t1071.003
- drl.4.candidate
logsource:
category: network_connection
product: windows
service: sysmon
detection:
selection:
EventID: 3
DestinationPort:
- 993
- 465
- 587
filter_legit:
Image|endswith:
- '\OUTLOOK.EXE'
- '\thunderbird.exe'
- '\chrome.exe'
- '\firefox.exe'
- '\msedge.exe'
condition: selection and not filter_legit
falsepositives:
- Mail clients not in filter list
- Backup and archiving tools with SMTP reporting
- Developer SMTP testing utilities
level: mediumKQL — Microsoft Defender for Endpoint (DRL-4 candidate — not production)
// DRL-4 candidate — not production
// Add known-good mail clients to exclusion list after baseline review
let LegitMailClients = dynamic(["outlook.exe","thunderbird.exe","chrome.exe","firefox.exe","msedge.exe"]);
DeviceNetworkEvents
| where Timestamp > ago(7d)
| where RemotePort in (993, 465, 587)
| where tolower(InitiatingProcessFileName) !in (LegitMailClients)
| project Timestamp, DeviceName, AccountName,
InitiatingProcessFileName, InitiatingProcessCommandLine,
RemoteIP, RemotePort
| order by Timestamp descSPL — Splunk with Sysmon (DRL-4 candidate — not production)
`sysmon` EventCode=3
(DestinationPort=993 OR DestinationPort=465 OR DestinationPort=587)
NOT (Image="*\\OUTLOOK.EXE" OR Image="*\\thunderbird.exe" OR Image="*\\chrome.exe"
OR Image="*\\firefox.exe" OR Image="*\\msedge.exe")
| table _time, host, User, Image, CommandLine, DestinationIp, DestinationPort
| sort -_timeDRL Promotion Checklist for Any Example Above
Before any example can move from DRL-4 to DRL-5 or higher, the following must be documented:

No example on this page has passed DRL-5. None may be deployed as a production alert.
Common Mistakes
- Jumping from actor report to production alert by skipping telemetry validation.
- Using these examples as production rules because they have correct syntax.
- Failing to add environment-specific exclusions to the filter lists.
- Omitting false-positive review before enabling alerts.
- Claiming detection coverage because a technique is mapped.
Analyst Checklist
- Is there a source-backed behavior?
- Is telemetry confirmed available in the target environment?
- Is the hypothesis falsifiable?
- Are false positives named from real operational context?
- Is readiness level honestly stated as DRL-4?
SOC Handoff
Purpose
Package CTI-derived detections and hunts so SOC analysts can triage them consistently.
Practitioner-Level Explanation
SOC handoff is where CTI and detection engineering become operational; align it with the Customer project SOC workflow phase. A handoff note should explain why the alert matters, what to check first, what false positives are expected, when to escalate, and what response actions are authorized. Without SOC handoff, even good detection logic may fail in practice.
CTI Relevance
SOC handoff reduces alert fatigue, improves triage quality, and captures feedback for CTI updates.
Common Mistakes
- Jumping from actor report to production alert.
- Skipping telemetry requirements.
- Ignoring false positives and tuning.
- Claiming coverage without validation.
Practical Workflow
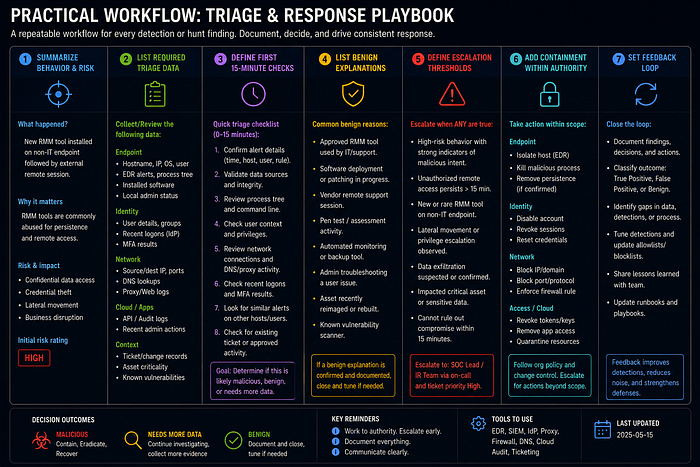
- Summarize behavior and risk.
- List required triage data.
- Define first 15-minute checks.
- List benign explanations.
- Define escalation thresholds.
- Add containment guidance within authority.
- Set feedback loop.
Example / Mini Case
Alert: unusual MDM wipe command pattern. SOC checks admin identity, MFA/session context, device count, change ticket, source IP, and recent privilege changes before escalation.
Analyst Checklist
- Is there a source-backed behavior?
- Is telemetry available?
- Is the hypothesis testable?
- Are false positives named?
- Is readiness level honest?
Part 9: AI-Assisted CTI
Manual vs AI-Assisted CTI
Purpose
Explain where AI can accelerate CTI work and where human judgment remains mandatory.
Practitioner-Level Explanation
AI can accelerate source triage, summarization, schema drafting, prompt-based extraction, first-pass hypothesis generation, and editorial tightening. It cannot own attribution, source validation, confidence assignment, or customer-risk acceptance.
The useful model is analyst-led, AI-assisted CTI.
CTI Relevance
AI-assisted CTI can reduce mechanical effort while preserving evidence discipline if quality gates are enforced.
Common Mistakes
- Letting the model invent sources or facts.
- Using AI output without source verification.
- Putting sensitive or restricted data into public tools.
- Skipping human analytic judgment.
Practical Workflow
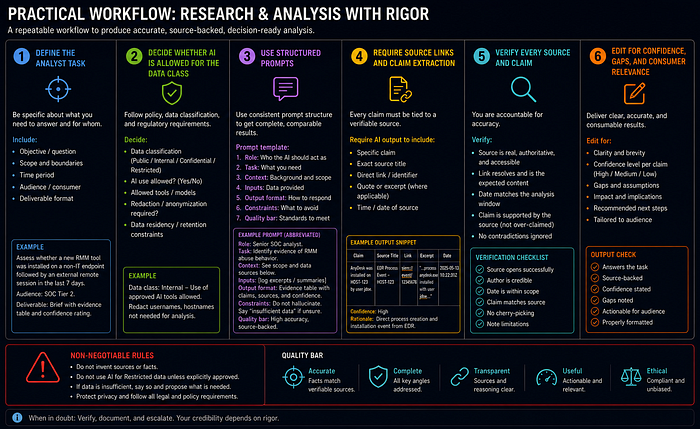
- Define the analyst task.
- Decide whether AI is allowed for the data class.
- Use structured prompts.
- Require source links and claim extraction.
- Verify every source and claim.
- Edit for confidence, gaps, and consumer relevance.
Example / Mini Case
Manual workflow may take hours to extract claims from reports. AI can create a draft extraction table quickly, but the analyst must verify URLs, evidence labels, and whether the text supports each claim.
Analyst Checklist
- Are sources real and checked?
- Are claims evidence-labeled?
- Is sensitive data excluded?
- Has a human reviewed the output?
- Are hallucination controls applied?
AI CTI Control Matrix
Purpose
Define where AI assistance is allowed, restricted, or prohibited in CTI work.
Core Rule
AI output cannot independently create attribution, confidence, or production-readiness decisions. The analyst owns the judgment. This is not a preference — it is a requirement. An AI-generated confidence level is not a confidence level; it is an unchecked assertion.
Data Classification Matrix
Before any AI use, classify the data:
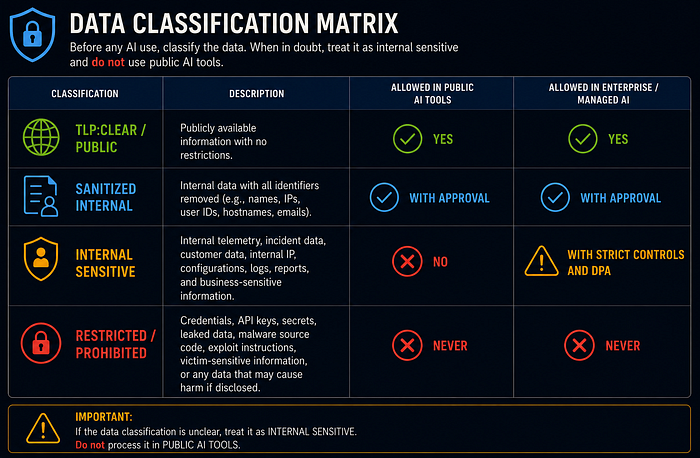
If data classification is unclear, treat it as internal sensitive and do not process it in public AI tools.
Task Control Matrix
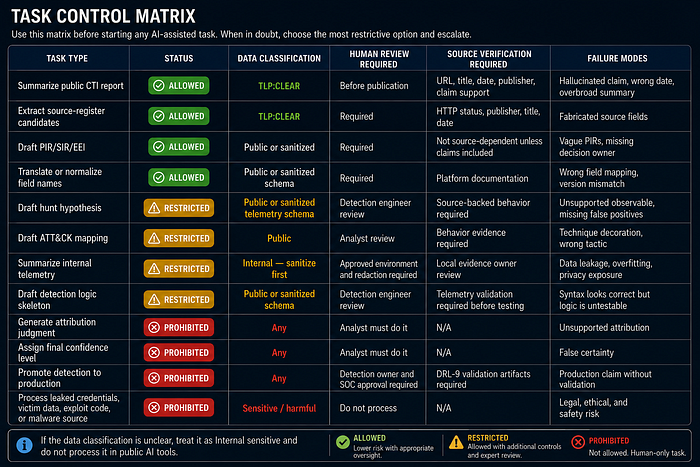
Prompt-Injection Controls
Source documents, webpages, and vendor reports are untrusted input. They may contain prompt-injection attempts.
Controls:
- Explicitly instruct the model to ignore instructions embedded in source documents.
- Do not allow the model to follow links or execute commands mentioned in sources.
- Ask the model to extract claims and cite source passages verbatim; do not let it interpret source-embedded directives.
- Keep evidence labels, confidence levels, attribution judgments, and DRL assignments outside model output — these must be set by the analyst.
- Never allow generated text to automatically modify evidence registers, attribution statements, or production alert status.
Prompt-injection test cases:
Test your workflow against these known injection patterns before trusting model output from untrusted documents:

Hallucination Failure Examples
These are documented failure modes in CTI-context AI use.
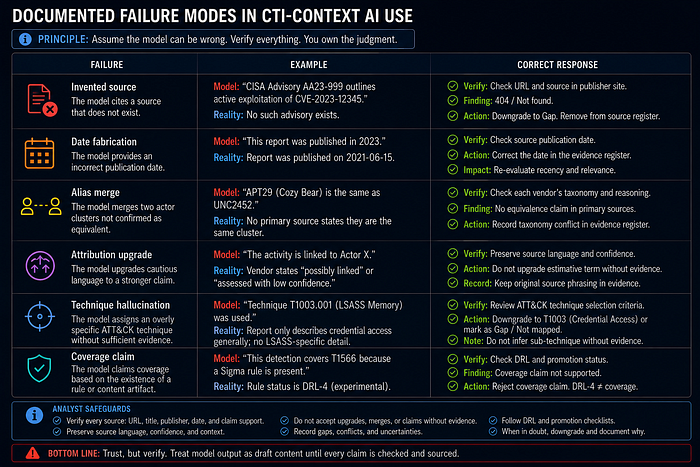
AI Review Log Template
Every AI-assisted CTI output must be logged before it enters any finished product, detection candidate, or evidence register.
AI Review Log ID:
Date:
Model Used:
Model Version / API Identifier:
Task Type: [Allowed / Restricted]
Data Classification: [TLP:CLEAR / Sanitized Internal / Other]
Source Inputs: [URLs or document identifiers — no sensitive content in log]
Prompt Version: [Prompt ID from prompt library or freeform description]
Output Summary: [What the model produced — claims extracted, fields drafted, etc.]
Source Verification:
- Source 1: URL [resolves / 404 / archive] — Content supports claim [Yes / Partial / No]
- Source 2: URL [resolves / 404 / archive] — Content supports claim [Yes / Partial / No]
Claim Review:
- Accepted claims: [list with evidence labels]
- Rejected claims: [list with reason for rejection]
- Downgraded claims: [list with corrected evidence label and reason]
Human Analyst: [name or role]
Attribution Assigned By: [Analyst name — AI did not assign attribution]
Confidence Assigned By: [Analyst name — AI did not assign confidence]
DRL Assigned By: [Analyst name — AI did not promote DRL]
Final Use: [source register / evidence register / hunt draft / report section / none]
Residual Risk: [Any unresolved concern or gap]Prohibited Use Summary
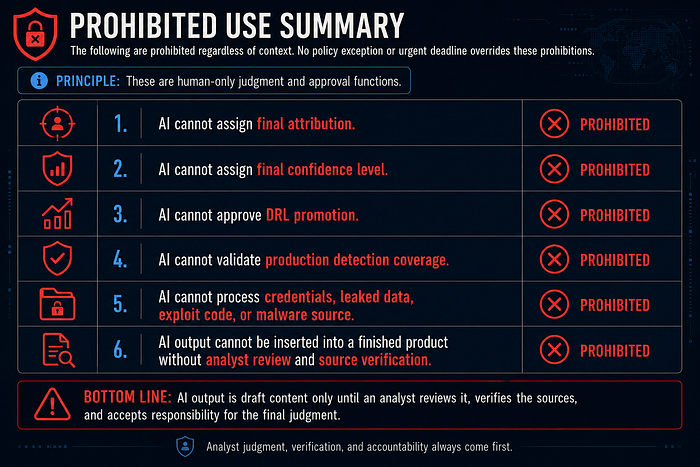
The following are prohibited regardless of context. No policy exception or urgent deadline overrides these prohibitions:
- AI cannot assign final attribution.
- AI cannot assign final confidence level.
- AI cannot approve DRL promotion.
- AI cannot validate production detection coverage.
- AI cannot process credentials, leaked data, exploit code, or malware source.
- AI output cannot be inserted into a finished product without analyst review and source verification.
Bad Example / Corrected Example
Bad:
The model says this cluster is Actor X with high confidence.Corrected:
The model extracted three source-reported similarities to Actor X (shared tooling,
overlapping targeting, similar lure themes). The analyst assigns low attribution
confidence because the evidence consists of shared tooling and victimology only,
with no exclusive infrastructure link or source-confirmed operator overlap.
Alternative hypothesis: separate actor reusing available tooling.
Analyst: [name]. AI Review Log: AIR-004.Hallucination Control
Purpose
Provide controls for preventing fabricated or unsupported AI-generated CTI claims.
Practitioner-Level Explanation
Hallucination control is a workflow problem. The model must not be allowed to convert plausible language into accepted intelligence. Require source URLs, direct support checks, evidence labels, and rejection of unsupported claims. Use AI to accelerate analysis, not to replace evidence.
CTI Relevance
CTI is especially vulnerable to hallucination because actor names, aliases, tools, and campaigns are easy to blend incorrectly.
Common Mistakes
- Letting the model invent sources or facts.
- Using AI output without source verification.
- Putting sensitive or restricted data into public tools.
- Skipping human analytic judgment.
Practical Workflow

- Require citations for every claim.
- Open each URL.
- Check content against claim.
- Downgrade unsupported claims.
- Preserve gaps.
- Avoid actor merges unless source-confirmed.
Example / Mini Case
The model claims two actor aliases are equivalent. The analyst checks primary sources and finds only one vendor uses the alias while another keeps clusters separate. The output records a taxonomy conflict rather than merging them.
Analyst Checklist
- Are sources real and checked?
- Are claims evidence-labeled?
- Is sensitive data excluded?
- Has a human reviewed the output?
- Are hallucination controls applied?
AI Quality Gates
Purpose
Define review gates that AI-assisted CTI outputs must pass before use.
Practitioner-Level Explanation
AI output should not be accepted because it reads well. It must pass gates: source existence, source support, evidence labeling, no unsupported attribution, no sensitive data exposure, no unsafe content, and human review. For customer delivery, AI use should be logged according to project policy.
CTI Relevance
Quality gates prevent hallucinations and weak claims from entering reports, detections, or executive decisions.
Common Mistakes
- Letting the model invent sources or facts.
- Using AI output without source verification.
- Putting sensitive or restricted data into public tools.
- Skipping human analytic judgment.
Practical Workflow

- Check data handling.
- Verify every URL.
- Confirm source content supports each claim.
- Check evidence labels.
- Check attribution and ATT&CK rules.
- Check safety boundaries.
- Record reviewer and decision.
Example / Mini Case
An AI summary says a source attributes an operation to a sponsor. The reviewer opens the source and finds the source used only cautious language. The claim is downgraded and confidence lowered.
Analyst Checklist
- Are sources real and checked?
- Are claims evidence-labeled?
- Is sensitive data excluded?
- Has a human reviewed the output?
- Are hallucination controls applied?
Safe LLM Research Workflow
Purpose
Define a safe workflow for using LLMs in public, defensive CTI research.
Practitioner-Level Explanation
Safe LLM use starts with scope and data handling; use Customer project AI governance for delivery work. Public TLP:CLEAR material may be appropriate for external tools. Internal telemetry, credentials, victim data, proprietary reporting, or sensitive incident data should not be pasted into public models.
The model should be asked to produce structured claims, source links, confidence caveats, and gaps. The analyst verifies everything.
CTI Relevance
This workflow lets teams gain speed without losing source integrity or data-handling discipline.
Common Mistakes
- Letting the model invent sources or facts.
- Using AI output without source verification.
- Putting sensitive or restricted data into public tools.
- Skipping human analytic judgment.
Practical Workflow
- Classify the data.
- Define task and allowed sources.
- Ask for structured output.
- Require evidence labels.
- Verify links and content.
- Downgrade unsupported claims.
- Record AI use if project policy requires it.
Example / Mini Case
Prompt the model to extract claims from public reporting into a table: claim, source URL, evidence label, confidence, detection implication, gap. Then manually check each URL and claim before using it.
Analyst Checklist
- Are sources real and checked?
- Are claims evidence-labeled?
- Is sensitive data excluded?
- Has a human reviewed the output?
- Are hallucination controls applied?
Prompt Library
Purpose
Provide reusable prompt patterns for CTI research, evidence review, and detection handoff.
Practitioner-Level Explanation
Prompts should force structure. The best CTI prompts ask for claim tables, source verification, uncertainty, gaps, and downstream artifacts rather than narrative summaries. A prompt library should be treated like code: versioned, reviewed, and improved based on errors.
CTI Relevance
Good prompts reduce rework and make AI outputs easier to validate.
Common Mistakes
- Letting the model invent sources or facts.
- Using AI output without source verification.
- Putting sensitive or restricted data into public tools.
- Skipping human analytic judgment.
Practical Workflow

- Choose the task type.
- Define source limits.
- Specify evidence labels and confidence terms.
- Request structured output.
- Ask for gaps and candidate rows.
- Review manually.
Example / Mini Case
Research prompt: Extract only source-supported claims. For each claim provide URL, evidence label, confidence reason, defensive implication, and whether it should become a source-register, evidence-register, TTP, hunt, or detection row.
Analyst Checklist
- Are sources real and checked?
- Are claims evidence-labeled?
- Is sensitive data excluded?
- Has a human reviewed the output?
- Are hallucination controls applied?
Part 10: Templates
Source Register Template
Purpose
Track source provenance, reliability, credibility, review status, and downstream use.
Fields
- source_id: Unique source identifier.
- publisher: Organization or author.
- title: Exact source title.
- url: Stable source URL.
- publication_date: Date the source was published.
- accessed_date: Date the analyst accessed it.
- source_type: Government, vendor CTI, academic, media, persona claim, internal, or other.
- reliability: A-F source reliability rating.
- credibility: 1–6 information credibility rating.
- summary: Short source summary.
- limitations: Known limits, missing evidence, or caveats.
- downstream_links: Evidence, actor, TTP, hunt, detection, or report links.
Example Values
source_id: SRC-001
publisher: Example Vendor CTI
title: Example Campaign Report
url: https://example.com/report
publication_date: 2026-05-01
accessed_date: 2026-05-16
source_type: Vendor CTI
reliability: B
credibility: 2
summary: Reports phishing leading to script execution.
limitations: No raw telemetry shown.
downstream_links: EV-001, HUNT-003Quality Gates
- URL resolves or archive is recorded.
- Publication and access dates are present.
- Reliability and credibility are justified.
- Limitations are not empty.
Common Failure Modes
- Using a source without access date.
- Rating the publisher but not the claim.
- No link to downstream evidence.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: source ID, publisher, title, URL or access location, publication date when available, accessed date, source type, reliability, credibility, limitations, downstream use.
Optional: archive URL, archive hash, language, collection method, reviewer, next review date.
Pass / Fail Example
Pass: A vendor report row includes title, URL, publication date, accessed date, A-F reliability, 1–6 credibility, a limitation, and linked evidence IDs.
Fail: A row says "vendor blog" with no URL, no date, no access metadata, and no explanation of why the source is trusted.
Complete Filled Example
source_id: SRC-ATTACK-001
publisher: MITRE ATT&CK
title: Enterprise ATT&CK documentation
url: https://attack.mitre.org/
publication_date: Ongoing
accessed_date: 2026-05-16
source_type: Framework documentation
reliability: A
credibility: 2
summary: Official behavior taxonomy used for technique mapping.
limitations: Not attribution evidence and not proof of detection coverage.
downstream_links: ATT&CK mapping rules, DRL model, detection backlog.Evidence Register Template
Purpose
Record claim-level evidence so CTI judgments remain traceable.
Fields
- evidence_id: Unique evidence identifier.
- claim: Single claim, not a paragraph of mixed claims.
- evidence_label: Observed, Reported, Assessed, Inferred, Unknown, or Gap.
- source_id: Source register ID.
- confidence: High, Medium, or Low.
- confidence_reason: Why the confidence level was assigned.
- contradiction_or_gap: Known conflict or missing evidence.
- downstream_use: Report, actor page, TTP, hunt, detection, or executive summary.
Example Values
evidence_id: EV-014
claim: Vendor reports archive attachment leading to script execution.
evidence_label: Reported
source_id: SRC-004
confidence: Medium
confidence_reason: Reliable source, but no raw telemetry included.
contradiction_or_gap: Unknown whether observed in our environment.
downstream_use: HUNT-002, DET-CAND-005Quality Gates
- One claim per row.
- Evidence label is explicit.
- Confidence has a reason.
- Gaps and contradictions are visible.
Common Failure Modes
- Combining multiple claims in one row.
- Using confidence without reason.
- No downstream action or gap.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: evidence ID, single claim, evidence label, source ID, reliability, credibility, confidence, confidence reason, contradiction or gap, downstream use.
Optional: quote summary, analyst owner, review date, superseded-by field.
Pass / Fail Example
Pass: One row records one claim and explains why confidence is medium.
Fail: One row mixes targeting, tooling, attribution, and detection implications into a paragraph.
Complete Filled Example
evidence_id: EV-ATTACK-001
claim: ATT&CK mapping describes behavior and should not be used as actor attribution proof.
evidence_label: Reported
source_id: SRC-ATTACK-001
source_reliability: A
information_credibility: 2
confidence: High confidence
confidence_reason: Official framework documentation and consistent defensive practice.
contradiction_or_gap: Campaign-specific mapping still requires separate evidence.
downstream_use: ATT&CK mapping rules and detection backlog.Collection Gap Register
Purpose
Track missing information that affects CTI judgments or defensive action.
Fields
- gap_id: Unique gap identifier.
- requirement: PIR/SIR affected.
- gap_statement: What is missing.
- impact: Blocking, confidence-limiting, or contextual.
- collection_path: How to close or reduce the gap.
- owner: Person or team responsible.
- due_date: Review or collection date.
- status: Open, in progress, closed, accepted risk.
Example Values
gap_id: GAP-006
requirement: PIR-002
gap_statement: Unknown whether endpoint telemetry records command-line fields for script hosts.
impact: Blocking
collection_path: Validate EDR schema and retention.
owner: Detection Engineering
due_date: 2026-05-30
status: OpenQuality Gates
- Impact is classified.
- Owner exists.
- Collection path is realistic.
- Accepted gaps are risk-owned.
Common Failure Modes
- Gap has no owner.
- Gap is vague.
- Gap never reviewed.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: gap ID, affected requirement, gap statement, impact, collection path, owner, due date, status.
Optional: risk acceptance owner, escalation date, related evidence IDs.
Pass / Fail Example
Pass: The gap states exactly which telemetry field is missing and who must validate it.
Fail: The gap says "need more intel" with no owner or collection path.
Complete Filled Example
gap_id: GAP-DRL-001
requirement: DET-CAND-001 promotion to DRL-6
gap_statement: Unknown whether EDR records parent process for archive utilities.
impact: Blocking validation.
collection_path: Query 30-day EDR schema sample and confirm field retention.
owner: Detection Engineering
due_date: 2026-06-01
status: OpenActor Profile Template
Purpose
Create an actor profile that supports decisions, hunts, and detections.
Fields
- actor_id: Stable actor identifier.
- primary_name: Preferred name and rationale.
- aliases: Aliases with source for each.
- sponsor_assessment: Sponsor claim with evidence label and confidence.
- targeting: Sectors, regions, and victimology with dates.
- ttps: Behavior mappings with evidence.
- tools: Tools and malware with source-backed behavior.
- detections: Mapped hunts or detections.
- gaps: Unknowns and collection needs.
- last_reviewed: Review date and owner.
Example Values
actor_id: ACT-001
primary_name: Example Cluster
aliases: VendorA Name, VendorB Name
sponsor_assessment: Assessed-by-source, medium confidence
targeting: Telecom and public-sector reporting since 2024
ttps: T1566 phishing, evidence EV-003
tools: ExampleLoader, reported by SRC-002
detections: HUNT-004
gaps: No public 2026 primary source found
last_reviewed: 2026-05-16Quality Gates
- Aliases are source-confirmed.
- Actor, persona, and sponsor are separated.
- TTPs are behavior-backed.
- Gaps are explicit.
Common Failure Modes
- Alias drift.
- Tool overlap used as attribution proof.
- No relevance section.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: primary name, alias table with source per alias, sponsor statement or Gap, targeting, TTPs, tools, evidence IDs, detection implications, gaps, freshness date.
Optional: infrastructure notes, persona claims, timeline, confidence history, retired aliases.
Pass / Fail Example
Pass: The profile separates actor, persona, sponsor, and tool claims, with source and confidence for each.
Fail: The profile merges vendor aliases without source mapping and treats shared tooling as attribution proof.
Complete Filled Example
actor_id: ACT-EXAMPLE-001
primary_name: Example Cluster
aliases: VendorA ExampleName (SRC-001); VendorB ExampleKitten (SRC-002)
sponsor_assessment: Gap; no primary source confirms sponsor.
targeting: Reported telecom and public-sector targeting, 2024-2026.
ttps: T1505.003 web shell, EV-010, medium mapping confidence.
tools: ExampleShell, Reported, SRC-002.
detections: HUNT-EDGE-001, DET-CAND-003.
gaps: No 2026 primary reporting on current infrastructure.
last_reviewed: 2026-05-16Hunting Hypothesis Template
Purpose
Create falsifiable hunt plans from CTI claims.
Fields
- hunt_id: Unique hunt identifier.
- hypothesis: If/then behavior statement.
- source_claim: Claim and source backing the hunt.
- telemetry: Required tables/logs.
- fields: Required fields.
- lookback: Search period.
- malicious_pattern: Expected suspicious behavior.
- benign_pattern: Expected legitimate pattern.
- false_positives: Likely benign sources.
- escalation: When to open incident or case.
Example Values
hunt_id: HUNT-011
hypothesis: If phishing leads to script execution, then endpoints receiving suspicious mail may spawn script interpreters within 24 hours.
source_claim: EV-009
telemetry: Email gateway, EDR process, network logs
fields: recipient, attachment, process, command line, destination
lookback: 30 days
false_positives: IT automation, software installers
escalation: Script execution plus unknown external download.Quality Gates
- Hypothesis is falsifiable.
- Telemetry and fields are listed.
- False positives are named.
- Stop condition exists.
Common Failure Modes
- Keyword search disguised as a hunt.
- No benign baseline.
- No escalation path.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: hypothesis, source claim, telemetry, fields, lookback, malicious pattern, benign pattern, false positives, escalation threshold, stop condition.
Optional: ATT&CK mapping, query draft, reviewer, pilot notes.
Pass / Fail Example
Pass: Hypothesis is falsifiable and names both malicious and benign patterns.
Fail: Hypothesis is a keyword search with no stop condition.
Complete Filled Example
hunt_id: HUNT-RMM-001
hypothesis: If unauthorized RMM is used after initial access, then a non-IT host will show new RMM install plus external remote session without a change ticket.
source_claim: EV-RMM-001
telemetry: EDR process, software inventory, network, identity, ticketing
fields: host, user, process, command_line, destination, ticket_id
lookback: 30 days
malicious_pattern: New RMM install on non-IT host plus external session.
benign_pattern: Approved helpdesk deployment with ticket and known admin user.
false_positives: Vendor support, helpdesk, migrations.
escalation: No ticket plus suspicious pre-install email or external source.
stop_condition: All hits explained by approved deployment records.Detection Backlog Item
Purpose
Track detection candidates from idea to retirement.
Fields
- detection_id: Unique detection identifier.
- title: Short behavior-focused title.
- source_behavior: Behavior being detected.
- evidence_id: Claim/evidence backing the idea.
- telemetry: Required data source.
- logic_summary: Plain-language detection logic.
- false_positives: Expected benign matches.
- validation: Positive, negative, replay, or pilot status.
- readiness: Hunt, pilot, production, retired, or DRL level.
- owner: Responsible engineer or team.
Example Values
detection_id: DET-007
title: Archive Extraction Followed by Script Execution
source_behavior: Phishing archive launches script interpreter
evidence_id: EV-009
telemetry: EDR process and file events
logic_summary: Archive extraction followed by powershell/cscript/wscript within 10 minutes
false_positives: Admin packages, installers
validation: Synthetic positive and negative tests pending
readiness: Hunt
owner: Detection EngineeringQuality Gates
- Behavior-focused title.
- Evidence linked.
- Telemetry verified.
- Validation status honest.
- Owner and next step present.
Common Failure Modes
- Actor-name detection title.
- No false positives.
- Production status without tests.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: detection ID, behavior title, evidence ID, telemetry, field mapping, logic summary, false positives, validation status, DRL, owner, review date, rollback plan.
Optional: Sigma/KQL/SPL paths, ATT&CK mapping, SOC pilot notes, retirement reason.
Pass / Fail Example
Pass: Detection is marked DRL-4 with draft logic and no production claim.
Fail: Detection is marked production because it has a Sigma rule but no replay, owner, or SOC handoff.
Complete Filled Example
detection_id: DET-CAND-001
title: Non-IT RMM Install Followed by External Session
source_behavior: Reported RMM abuse after initial access.
evidence_id: EV-RMM-001
telemetry: EDR software inventory, process, network, identity, ticketing
field_mapping: host, user, product_name, process_name, destination_ip, ticket_id
logic_summary: New RMM install on non-IT host followed by external session within 60 minutes.
false_positives: Helpdesk deployment, approved vendor support.
validation: Positive/negative synthetic tests pending.
readiness: DRL-4 / Hunt
owner: Detection Engineering
review_date: 2026-06-16
rollback_plan: Disable scheduled query and revert tuning list.Infrastructure Pivot Log
Purpose
Document accepted and rejected infrastructure pivots with link strength and limitations.
Fields
- pivot_id: Unique pivot identifier.
- seed: Initial IOC or artifact.
- pivot_type: Passive DNS, certificate, ASN, URL path, favicon, malware config, or telemetry.
- related_indicator: Candidate related indicator.
- time_window: First/last seen or relevant date window.
- link_strength: Weak, moderate, or strong.
- decision: Accepted, rejected, or pending.
- reason: Why the decision was made.
- limitations: False-positive and coverage risks.
Example Values
pivot_id: PIV-002
seed: example[.]com
pivot_type: Certificate
related_indicator: update-example[.]com
time_window: 2026-04-01 to 2026-04-08
link_strength: Moderate
decision: Accepted
reason: Shared rare SAN pattern and URL path.
limitations: Attribution remains Unknown.Quality Gates
- Every pivot has a time window.
- Rejected pivots are preserved.
- Link strength is justified.
- Attribution is not inferred from weak pivots.
Common Failure Modes
- Graph sprawl.
- No rejected-pivot record.
- No false-positive discussion.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: seed, pivot type, related indicator, time window, link strength, decision, reason, limitations.
Optional: tool used, screenshot/hash of result, analyst owner, expiry date.
Pass / Fail Example
Pass: A certificate pivot is accepted because of rare SAN pattern plus matching URL path in the same week.
Fail: Every domain on the same ASN is treated as actor infrastructure.
Complete Filled Example
pivot_id: PIV-014
seed: login-example[.]com
pivot_type: Certificate + URL path
related_indicator: auth-example[.]com
time_window: 2026-05-10 to 2026-05-14
link_strength: Moderate
decision: Accepted as candidate cluster, not attribution.
reason: Same cert issuance window and same uncommon path structure.
limitations: Could be shared phishing kit; actor remains Unknown.SOC Handoff Note
Purpose
Package a hunt or detection for SOC triage and escalation.
Fields
- handoff_id: Unique handoff identifier.
- alert_or_hunt: Name of alert or hunt.
- why_it_matters: Threat and impact context.
- first_checks: Initial triage steps.
- required_logs: Logs needed for triage.
- false_positives: Expected benign causes.
- escalation: Escalation threshold.
- response: Authorized response guidance.
- feedback: What SOC should report back.
Example Values
handoff_id: SOC-004
alert_or_hunt: Non-IT RMM Installation
why_it_matters: Reported adversary behavior uses RMM after phishing.
first_checks: User, host role, install source, ticket, remote session.
required_logs: EDR, software inventory, email, identity.
false_positives: Helpdesk support, approved vendor work.
escalation: No ticket plus external session plus suspicious email.
response: Isolate only per IR policy.
feedback: True/false positive and tuning notes.Quality Gates
- First checks are concrete.
- Escalation threshold is clear.
- False positives are realistic.
- Response stays within authority.
Common Failure Modes
- No triage path.
- Overbroad escalation.
- No feedback loop.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: alert/hunt name, why it matters, first checks, required logs, false positives, escalation threshold, response authority, feedback loop, owner.
Optional: screenshots, sample queries, known-good admin lists, rollback contact.
Pass / Fail Example
Pass: SOC can triage without reading the original CTI report.
Fail: Handoff says "investigate suspicious activity" with no first checks or escalation threshold.
Complete Filled Example
handoff_id: SOC-RMM-001
alert_or_hunt: Non-IT RMM Install Followed by External Session
why_it_matters: Unauthorized RMM can provide persistent remote control.
first_checks: host owner, install source, parent process, ticket, user, remote destination.
required_logs: EDR, software inventory, identity, network, ticketing.
false_positives: Helpdesk, vendor support, IT migration.
escalation: No ticket plus external session plus suspicious pre-install activity.
response: Follow IR policy; isolate only under incident commander authority.
feedback: True positive, false positive class, missing fields, tuning request.
owner: SOC LeadExecutive Summary Template
Purpose
Summarize CTI judgments for senior decision-makers without losing uncertainty.
Fields
- decision: Decision the summary supports.
- bottom_line: One-paragraph conclusion.
- why_now: Why the issue matters now.
- confidence: Confidence and reason.
- business_impact: Operational or risk impact.
- recommended_actions: Specific executive-level actions.
- limits: What is unknown or not proven.
- owner: Accountable owner for follow-up.
Example Values
decision: Approve 30-day hunt for remote admin tooling abuse.
bottom_line: Public reporting and local exposure justify a scoped hunt, not emergency blocking.
why_now: Multiple recent reports describe RMM abuse after initial access.
confidence: Medium; sources are credible but local telemetry is untested.
business_impact: Potential unauthorized remote control of endpoints.
recommended_actions: Approve hunt, validate telemetry, review RMM policy.
limits: No evidence of compromise in this environment.
owner: SOC Lead.Quality Gates
- Decision is explicit.
- No unsupported attribution.
- Confidence is explained.
- Actions are owned.
Common Failure Modes
- Too technical for audience.
- No decision.
- Uncertainty hidden.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: decision, bottom line, why now, confidence, business impact, recommended actions, limitations, owner.
Optional: risk rating, timeline, budget ask, appendix link.
Pass / Fail Example
Pass: Executive can approve, defer, or reject a concrete action.
Fail: Summary uses dramatic threat language but gives no decision or owner.
Complete Filled Example
decision: Approve a 30-day hunt for unauthorized RMM use.
bottom_line: Public reporting and local exposure justify a scoped hunt, not emergency blocking.
why_now: Recent reporting describes RMM abuse after initial access; local RMM baseline is incomplete.
confidence: Medium; reporting is credible but local telemetry is not fully validated.
business_impact: Unauthorized remote access could affect endpoint integrity and incident response.
recommended_actions: Approve hunt, validate telemetry, define approved RMM inventory.
limits: No local compromise evidence.
owner: SOC Lead and Detection Engineering.Finished Intelligence Report Template
Purpose
Structure a CTI report that supports decisions rather than only summarizing research.
Fields
- title: Report title.
- audience: Consumer and decision owner.
- executive_summary: Concise decision-focused summary.
- key_judgments: Evidence-backed judgments with confidence.
- evidence: Source and evidence references.
- assessment: Analytic interpretation.
- implications: Defensive, operational, or business impact.
- recommendations: Specific actions.
- gaps: Known unknowns.
- appendix: Source and technical detail.
Example Values
title: CTI Assessment of RMM Abuse Reporting
audience: SOC Lead and Detection Engineering
executive_summary: Public reporting supports a hunt, not production alerting yet.
key_judgments: Medium-confidence relevance due to current RMM exposure.
recommendations: Run 30-day hunt and baseline admin tooling.
gaps: Unknown local false-positive volume.Quality Gates
- Audience and decision are clear.
- Key judgments include confidence.
- Recommendations are actionable.
- Gaps are visible.
Common Failure Modes
- Research dump.
- No decision supported.
- No confidence language.
Practical Workflow
- Create the artifact only after the intelligence requirement or decision is clear.
- Fill required fields before writing narrative prose.
- Attach evidence labels, source references, confidence, and limitations.
- Review with the intended consumer.
- Update the artifact when evidence, telemetry, or decision context changes.
Analyst Checklist
- Is the consumer defined?
- Are required fields complete?
- Are claims source-backed or marked Gap?
- Is confidence justified?
- Are limitations explicit?
- Is there a next action or owner?
Required vs Optional Fields
Required: audience, decision, key judgments, evidence references, confidence, implications, recommendations, gaps, limitations.
Optional: technical appendix, source register extract, detection backlog links.
Pass / Fail Example
Pass: Key judgments are evidence-backed and recommendations are owned.
Fail: Report summarizes articles but does not support a decision.
Complete Filled Example
title: Assessment of RMM Abuse Relevance to Corporate Endpoint Estate
audience: SOC Lead and Detection Engineering
decision: Approve scoped 30-day hunt or defer.
key_judgment: Medium-confidence relevance due to public reporting and local RMM exposure.
evidence: EV-RMM-001, SRC-RMM-001
recommendation: Run DRL-4 hunt; do not deploy production alert yet.
gaps: No benign baseline or historical replay.
limitations: No evidence of compromise in this environment.