
Paved paths are not a new idea. The concept is simple and well understood: give developers a pre-built, secure-by-default starting point so they don't have to figure out authentication, secrets management, input validation, and logging from scratch every time they spin up a new service. If the secure option is also the fastest option, developers will take it.
Everyone agrees this is the right approach. And yet, almost no one executes it well!
Here's what actually happens. A platform team builds a golden path template. It works beautifully for six months. Then a dependency gets a critical CVE and nobody updates the template for three weeks. An internal API ships a breaking change and the scaffold starts failing on step four. The team that built the template gets reorged. New developers try the template, hit errors, google the fix, can't find it, and build from scratch. Word spreads: "don't use the template, it's broken." Within a year, the golden path is a ghost town, and you're right back where you started — every team rolling their own security controls, inconsistently.
The problem isn't the concept of paved paths. The problem is that we treat them as static artifacts maintained by humans on a best-effort basis. A small platform team of 4–6 engineers cannot keep pace with the rate of change in dependencies, internal APIs, cloud provider updates, and developer expectations across an enterprise.
So let's fix the actual problem. Not "build better templates." Build templates that maintain themselves.
How Paved Paths Feed the Assurance Pipeline
In the continuous assurance model from Part 1, paved paths are Stage 0 — they sit upstream of everything else. Here's why that matters:
Every vulnerability that's prevented at the platform level is a vulnerability that never enters the input funnel, never triggers a scanner, never produces a finding for the LLM to contextualize, never drags down an assurance score, never constrains a deployment. Paved paths are the most efficient way to reduce the total workload on every downstream stage.
First, Let's Get Clear on What a Paved Path Actually Is
A paved path is not a template repository that developers clone and then drift from. It is a living, maintained, opinionated platform layer that developers build on top of.
When a developer creates a new service, they run a CLI command or click through a portal and get a running service with:
- Authentication wired to the identity provider
- Authorization using the internal policy engine
- Input validation middleware active by default
- Secrets pulled from the vault, not hardcoded
- Structured logging configured to the security team's spec
- CI/CD pipeline with the full security validation stack pre-attached
The critical design choice is this: the paved path has to be the fastest way to ship. Not the most secure way. Not the compliant way. The fastest way. If a developer can get to production quicker by going off-path, you've already lost.
Going off-path should require more work, not less. And in the continuous assurance model I described in Part 1, it does — because off-path deviations raise the risk score in the input funnel, which activates heavier automated validation, which means tighter deployment constraints. Staying on the path means less friction. Going off means more scrutiny. The incentive structure does the enforcement.
The Rot Problem
But none of that matters if the path itself is broken. And this is where most programs fail. The rot happens in predictable ways. Let me summarize them using tables (you will notice my love for tabular depictions of data throughout my writing!):
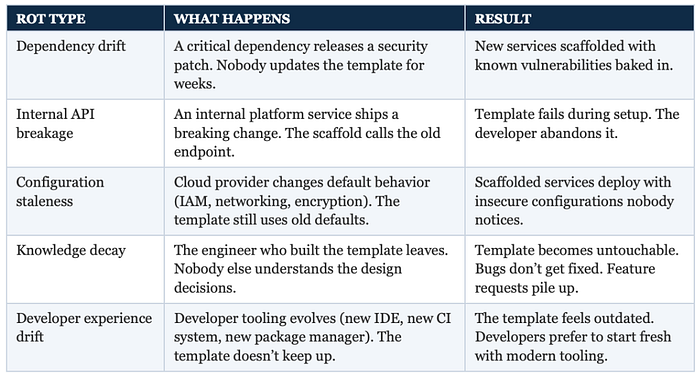
The common response to this is "hire more platform engineers" or "dedicate more time to maintenance." That's a staffing solution to a systems problem. It doesn't scale. What scales is making the paths maintain themselves.
The Agent Layer: Self-Maintaining Paved Paths
Here's the shift I'm proposing: instead of a platform team manually maintaining paved paths, you layer a set of specialized AI agents on top that continuously monitor, update, test, and evolve the paths. The platform team shifts from building and maintaining everything to curating and reviewing agent-generated changes.
Five agents. Each one solves a specific rot problem.
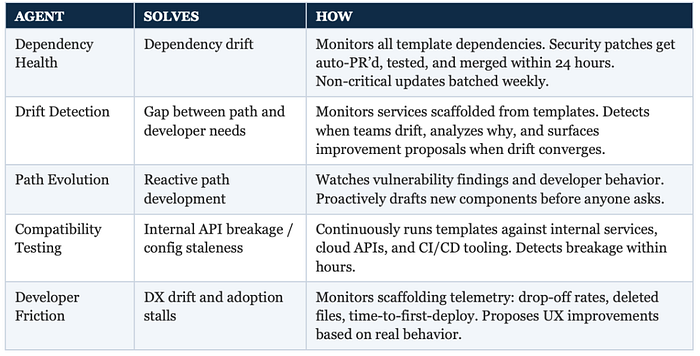
Three of these — Dependency Health, Compatibility Testing, and Developer Friction — are relatively self-explanatory. They automate maintenance work that platform teams already know they should be doing but can't keep up with. The two that change the game are Drift Detection and Path Evolution.
Drift Detection Agent
Solves: The gap between what the paved path provides and what developers actually need
Most programs treat off-path deviation as a compliance problem. Developers went rogue, didn't follow the standard, and needed to be corralled back. The Drift Detection Agent reframes it: if enough developers deviate in the same direction, that's not a discipline failure. That's a product signal.
If fifteen teams all modify the same auth middleware to add custom claim validation, the agent doesn't flag fifteen violations. It surfaces one improvement proposal: "15 services modified default auth middleware the same way. Here's the converging pattern. Recommend adding this as a configurable option in the scaffold." The platform team didn't have to run a survey. The code told them what developers needed.
What about one-off modifications unique to a single team? Drift like these that doesn't converge gets ignored. The agent distinguishes between systemic gaps and team-specific customizations. It optimizes for patterns that affect the most developers. Neat, huh?
Path Evolution Agent
Solves: The reactive nature of paved path development
Traditional paved path teams are reactive. They build a component when someone asks for it, or when a vulnerability gets bad enough that leadership demands a fix. The Path Evolution Agent is proactive. It watches production telemetry, vulnerability findings from the validation core, and developer behavior patterns across the organization — and proposes new paved path components before anyone asks.
If the validation core keeps catching the same CORS misconfiguration across multiple repos, this agent doesn't wait for a human to notice the pattern and decide to build a middleware. It drafts the middleware itself, writes tests based on the vulnerability patterns it's observed, and submits it as a pull request for the platform team to review. It includes the data: "This pattern appeared in 23 repos over the last 90 days. 8 resulted in findings. Here's a middleware that prevents it. Here are the tests."
The platform team's role shifts from "build everything from scratch" to "review and approve agent-generated components." That's a fundamentally different (and more scalable, IMHO) operating model.
How the Agents Work Together
Individually, each agent solves a specific rot problem. But the real power is in the orchestration. These agents aren't five independent tools running in parallel — they form a pipeline within the pipeline, where one agent's output becomes another agent's input. Let's look at two orchestration patterns as examples:
Pattern 1: Gap to Component Delivery
The Drift Detection Agent notices 15 teams modifying the same auth middleware. It surfaces the gap signal. The Path Evolution Agent picks it up and drafts a configurable auth component based on the converging pattern. The Compatibility Testing Agent runs the new component against all internal APIs and cloud versions. The Dependency Health Agent evaluates the new dependencies it introduces. The component ships. Then the Developer Friction Agent monitors adoption — are developers actually using it, or still drifting?
Full lifecycle: Detect → Propose → Validate → Ship → Measure → feeds back to Detect. The platform team reviewed and approved the component. The agents did everything else.
Pattern 2: Friction Tracing Across Agent Actions
The Developer Friction Agent detects that time-to-first-deploy has increased 40% after a recent template update. It correlates this with a Compatibility Testing Agent change from last week that added a new validation step. The Drift Detection Agent confirms — developers are skipping the step. The Path Evolution Agent proposes a streamlined version that preserves the security control but removes the friction. The Compatibility Testing Agent validates it. The Developer Friction Agent monitors the result.
Unintended consequence detected, root cause identified across agents, fix proposed, validated, and measured — without a human initiating anything.
The mental model: the five agents are an autonomous maintenance team that runs continuously. Each has a specialty, but they pass work to each other as needed. The human platform team is their engineering manager — setting priorities, reviewing important decisions, and stepping in when judgment is needed. The agents handle the volume.
What Happens When Developers Go Off-Path
Going off-path isn't forbidden. Sometimes there's a legitimate reason: the paved path doesn't support a niche use case, or a team needs a capability that hasn't been built yet. The system handles this without blocking anyone.
When a developer deviates from the paved path — rolling custom auth, hardcoding secrets, etc— the deviation is detected automatically and feeds into the input funnel as a risk signal (see Part 1 for reference). Their change gets a higher risk score, which means heavier automated validation, which means potentially tighter deployment constraints.
The developer isn't blocked. They're not told "you can't do this." But the environment responds proportionally: more scrutiny, tighter constraints, until the risk signal resolves.
The Takeaway
Paved paths are not a new idea. The concept has been in every AppSec maturity model for years. But the reason they underdeliver in practice isn't that the concept is wrong — it's that we've been treating them as static artifacts maintained by humans who don't have the bandwidth to keep up with the development velocity.
The innovation isn't better templates. It's an agent layer that makes the templates self-maintaining: dependencies always current, internal breakages caught in hours, new components proposed proactively based on real data, developer friction measured and addressed continuously. The platform team shifts from building and maintaining to curating and reviewing. The scaling model changes from linear to sublinear.
And because paved paths are Stage 0 in the assurance pipeline, every improvement here cascades downstream. Fewer vulnerabilities to scan for. Fewer findings to triage. Less deployment friction.
That's the highest-leverage investment you can make in your security program. Not another scanner. Not another review process. A paved path that developers actually trust because it's never broken, never stale, and always the fastest way to ship.
Next in the series: Part 3 dives into the Input Funnel — how to build an ML-powered risk classifier that scores every code change automatically, so no human ever has to decide "does this need a security review?"