
It is easy to talk about AI hacking as if it were still a conference-demo problem. The stronger evidence says otherwise. Over the last two years, the field has shifted from speculative prompt tricks toward documented incidents, concrete CVEs, and security advisories involving real products and enterprise workflows.
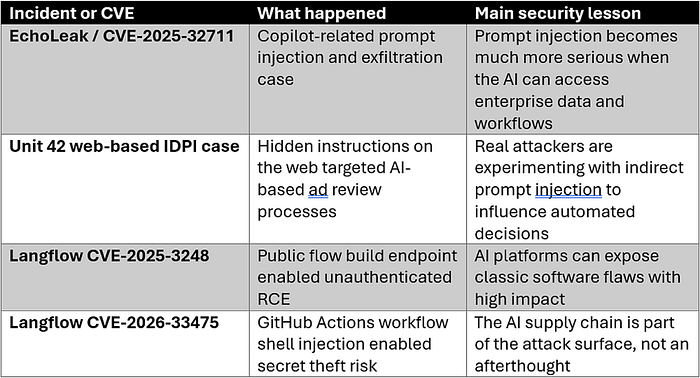
One of the most widely discussed examples is EchoLeak, tracked as CVE-2025–32711, a vulnerability associated with Microsoft 365 Copilot. Public write-ups describe it as a case where prompt injection and AI-driven exfiltration met in a real enterprise setting [7]. The importance of EchoLeak is not just the bug itself. It is what the bug symbolizes: a move from amusing prompt exploits toward situations where AI assistants sit close enough to valuable data that prompt manipulation can become a genuine business risk.
Microsoft's own discussion of indirect prompt injection reinforces the broader lesson. The company warns that attacker-controlled content in webpages, documents, emails, or tool output can be misread as instruction by an instruction-tuned model, leading to data exfiltration or unintended actions under the victim user's privileges [2]. That is a concise description of why AI security is now an enterprise problem rather than a niche research curiosity.
Another important lesson comes from Langflow, a platform for building AI-powered agents and workflows. One Langflow advisory, CVE-2025–3248, describes an unauthenticated remote code execution issue in a public flow build endpoint, where attacker-controlled flow data could trigger arbitrary Python execution on the server [5]. This is not prompt injection in the narrow sense. It is a classic application-security failure inside an AI workflow platform. That matters because many organizations still talk as if "AI security" only means safer prompts. In practice, insecure endpoints, dynamic execution paths, and weak authentication can be just as dangerous.
A separate standardized record, CVE-2026–33475, shows another side of the problem. The NVD describes a shell injection issue in Langflow GitHub Actions workflows before version 1.9.0, where unsanitized user-controlled context variables could allow command injection through branch names or pull request titles [6]. This is a supply-chain lesson. AI systems do not live in a bubble. They are packaged, tested, deployed, and maintained through ordinary engineering infrastructure, which means they inherit all the familiar risks of CI/CD, secrets handling, and automation pipelines.
What do these cases teach a beginner? First, the most dangerous AI attacks often appear at the intersection of model behavior and system design. A model may misread hostile text, but the real incident occurs because the model also has access, memory, permissions, or downstream trust. Second, AI-specific flaws and classic software flaws now overlap heavily. A modern assessor needs to understand both. Third, the attack surface keeps expanding as models gain tools, multimodal inputs, and autonomous workflows.
There is one more trend worth watching. Unit 42 argues that the web itself is increasingly becoming an LLM prompt-delivery surface, and that real-world malicious indirect prompt injection is moving toward higher-impact use cases [3]. That idea should stick with readers. Attackers are rarely obligated to attack the model head-on. If a hidden instruction inside ordinary content can shape what the model sees, decides, or does, then every connected content source becomes part of the threat model.
The practical takeaway is not panic. It is maturity. Organizations need the same discipline for AI systems that they learned, often painfully, to apply to web apps and cloud infrastructure: least privilege, defense in depth, careful input handling, output controls, segmentation, monitoring, and repeatable security testing. AI changes the mechanics, but not the need for disciplined engineering.
If you are just entering the field, that should be encouraging. AI hacking is not magic. It is the study of how language-driven systems fail when trust is misplaced.
References
[1] OWASP GenAI Security Project: LLM01 Prompt Injection
[4] HackerOne: LLM Application Pentest
[7] Hack The Box: Inside CVE-2025–32711 (EchoLeak ): Prompt injection meets AI exfiltration
Ethical hacking disclaimer: This article is intended for lawful security education, responsible disclosure, and authorized assessment only. Never use these techniques to bypass safety controls, recover confidential information, or test a system you do not own or have permission to evaluate.