

That's exactly what happened in Open WebUI.
— -
Open WebUI is a project that has already received a great deal of security attention. There are dozens of CVEs on record, a SECURITY.mdthat carefully delineates what the maintainers do and do not consider a vulnerability, and a visible institutional memory of past reports. When a codebase has been examined that many times, the reasonable assumption is that the obvious doors are closed.
So when I cloned `v0.9.4` and started reading, my working assumption was that I would spend a few days mapping FastAPI routers, confirm the known controls were in place, and close the engagement with no findings.
Background
For readers unfamiliar with it: Open WebUI is the self-hosted front end that a large share of the local-LLM community has standardized on. Point it at Ollama or any OpenAI-compatible endpoint and you get a polished, multi-user chat interface with retrieval-augmented generation, web search, document ingestion, and image handling — deployable with a single docker compose upcommand.
The architecture is fairly conventional, which also makes it relatively straightforward to audit:
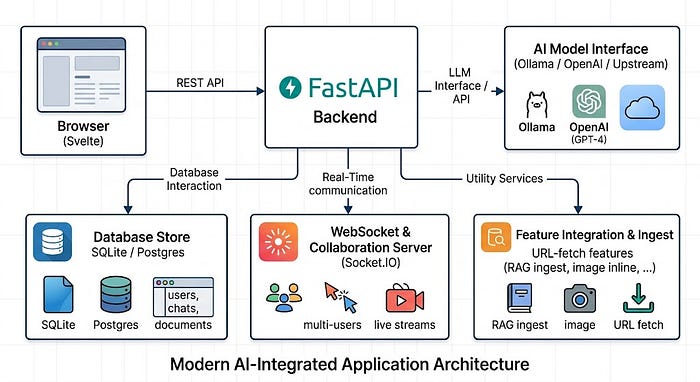
That last branch is the one this article is about. A significant portion of Open WebUI's value comes from features of the form *"the user supplies a URL, and the server retrieves it on their behalf"* — ingesting a web page into a vector store, inlining an image into a prompt, loading a remote PDF. Each of those features results in a server-side request whose destination is partially or fully controlled by a user who may not be trusted.
The maintainers are aware of this. There is a configuration flag (`ENABLE_RAG_LOCAL_WEB_FETCH`, disabled by default) and a central guard, `validate_url()`, whose sole responsibility is to prevent a user from pointing the server at `http://169.254.169.254/latest/meta-data/` and exfiltrating cloud credentials.
That guard is where I spent most of my time.
The Guard
Lightly trimmed:
def validate_url(url):
parsed_url = urllib.parse.urlparse(url)
if parsed_url.scheme not in ['http', 'https']:
raise ValueError(...)
if not ENABLE_RAG_LOCAL_WEB_FETCH:
ipv4, ipv6 = resolve_hostname(parsed_url.hostname)
for ip in ipv4 + ipv6:
if not ipaddress.ip_address(ip).is_global:
raise ValueError(...)
return TrueResolve the hostname; if any resulting address is not globally routable — loopback, RFC 1918, link-local — reject the request. It is simple, and for the URL you give it, it is correct.
I worked through the standard bypass catalogue. Decimal IP encoding (`http://2130706433/`) — normalised by `ipaddress`, blocked. IPv4-mapped IPv6 (`[::ffff:127.0.0.1]`) — blocked. Credential-in-authority confusion (`http://google.com@127.0.0.1/`) — `urlparse` handles it, blocked. The function held up.
Then I reached line 91 and the comment attached to it:
# This is technically still vulnerable to DNS rebinding attacks, ...Comments like this are valuable to an auditor — not because they reveal an exploit directly, but because they reveal the author's mental model. This one says, explicitly: *we know validation and use happen at different moments, and we have accepted that gap.* The maintainers had identified a time-of-check/time-of-use window and labelled it "DNS rebinding."
That label is accurate. It is also incomplete. I started asking what else could change inside that window.
Following the Call Graph
validate_url() does not perform any network I/O beyond the DNS lookup. It approves a URL and returns. The actual security property therefore depends entirely on what each *caller* does with the approved URL afterward.
A grep for validate_url( across the backend, followed by one question per call site: *which HTTP client consumes this URL, and what are its defaults?*
The first hit, in the RAG ingestion path (`retrieval/utils.py`):
validate_url(url)
response = requests.get(url, stream=True, timeout=30)I read it twice, then confirmed against the requests documentation, because it seemed too straightforward to have survived this long.
It had. request.get() follows HTTP redirects by default — up to thirty hops.
So: validate_url() resolves attacker.example.com, observes a public IP, and approves. requests.get() connects to attacker.example.com, receives
HTTP/1.1 302 Found
Location: http://169.254.169.254/latest/meta-data/iam/security-credentials/and follows it — because no one instructed it not to. The validator inspected the initial destination. No one re-validated the destination after the redirect.
"Surely This Was Considered"
That was, genuinely, my next thought. Redirect-based SSRF is well documented; I expected to find a project-wide session wrapper, a custom adapter, *something* that disabled redirects globally.
What I found instead is what elevated this from a suspicion to a finding. A few hundred lines away, in the same module, sits a class named `SafeWebBaseLoader`. Its fetch method reads:
async with session.get(url, ..., allow_redirects=False) as response:The control exists. Someone on the project recognised redirects as an SSRF bypass, applied the correct mitigation — and applied it to exactly one call site. The remaining three never received it.
Discovering a missing control is routine. Discovering a control that is correctly implemented within the same file where it is also missing is something else. It is the codebase confirming, in its own words, that the protection is supposed to be there.
Enumerating the Sinks
With the pattern identified, the remainder was enumeration. Three vulnerable sinks in total:
**1. RAG web ingestion** — the case above. Reachable via `POST /api/v1/retrieval/process/web` by any authenticated user under the default configuration. Notably, when the redirected target serves a non-`text/*` `Content-Type`, the response body is returned verbatim in the JSON response. Cloud metadata endpoints typically serve text/plain and therefore remain blind in this specific sink. However, any internal service responding with application/json — or even a misconfigured content type — yields a full-read SSRF.
**2. Chat image inlining** — `utils/files.py`. For every chat completion request, a middleware helper walks the message for `image_url` entries and inlines each one as base64 before forwarding to the model:
validate_url(url)
session = await get_session()
async with session.get(url, ssl=...) as response: # aiohttp — also follows redirects by default
image_data = await response.read()A different HTTP library, the same default behaviour, the same bypass. This path is **unconditional**: no feature flag, no dedicated endpoint. Any chat message containing an image URL triggers it.
The response body does not return directly to the caller; it is base64-encoded into the prompt sent to the upstream model. That makes it semi-blind — unless the user has configured the model endpoint to point at infrastructure they control, in which case the "model" receiving the payload is simply the attacker.
**3. Image editing** — `routers/images.py`. Structurally identical to sink 2, but gated behind `ENABLE_IMAGE_EDIT`, which defaults to off. The project's own threat model excludes non-default configuration from scope, so this is recorded for completeness rather than as a primary finding.
Two of three sinks are reachable by an ordinary authenticated user on a stock installation. That clears the project's stated bar for a valid report.
Demonstrating It
I prefer not to ask maintainers to take a finding on faith, so the next step was a proof-of-concept that could be reproduced in minutes.
First, confirming the validator behaves as described, inside the official Docker image:
>>> validate_url('https://public-host.example/?next=http://localhost:8080/')
True
>>> validate_url('http://localhost:8080/')
ValueError: Invalid URLThe redirector's URL passes; the direct internal URL does not. The check does precisely what it claims — and nothing more.
Second, an actual redirect to follow. Public open-redirect services have — sensibly — begun refusing to forward to private address ranges, so the PoC uses an eight-line HTTP server on any internet-reachable host:
class H(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(302)
self.send_header('Location', os.environ['TARGET'])
self.end_headers()Set `TARGET` to the internal resource of interest, submit the redirector's URL to either reachable endpoint, and observe the Open WebUI server's IP appear in the redirector's access log— followed immediately by a request from that same server to the internal target.
That is the entire exploit. No race condition, no timing window, no exotic encoding. One `302` and the default behaviour of the two most widely used HTTP client libraries in the Python ecosystem.
Severity
I initially assessed this as **CVSS 3.1 7.7 (High)** but the final score determined was 8.5/10.
The most realistic worst-case scenario is also one of the most common: Open WebUI deployed on an EC2 instance with an IAM role attached; an authenticated user fires the redirect at IMDS; temporary AWS credentials are returned. The path from "low-privilege login on a chat interface" to "credentials in the hosting cloud account" is two HTTP requests long.
The Fix
At each call site, the immediate remediation is a single keyword argument:
diff
- response = requests.get(url, stream=True, timeout=30)
+ response = requests.get(url, stream=True, timeout=30, allow_redirects=False)Three such changes close the reported sinks.
The durable remediation — and the one I recommended — is structural: replace the validate-then-fetch pattern with a single `safe_fetch(url)` helper that performs validation, issues the request with redirects disabled, and, if redirect support is desired, re-validates each `Location` header before following it. One safe code path, used everywhere, rather than a convention that every future contributor must independently remember.
What I Actually Took Away
The redirect itself is not the interesting part of this story. It is a documented pattern; if I had not found it, the next reviewer with `grep` and an afternoon would have.
The interesting part is line 91: `# This is technically still vulnerable to DNS rebinding attacks.`
That comment is correct. Its author understood the time-of-check/time-of-use problem precisely. But by *naming* the gap "DNS rebinding," they drew a boundary around it — and once a weakness has a name, it is remarkably easy to stop asking what else fits the same shape. The author was concerned that the hostname could resolve differently between validation and use. The broader truth is that *anything* about the request can change between validation and use — and an HTTP redirect changes the most important property of all: the destination.
I am not exempt from this. No one is. We identify a risk, we give it a label, and the label quietly becomes the perimeter of our concern.
So the durable lesson, beyond "*disable redirects after URL validation, every time*," is this: when you encounter a comment that begins "*this is technically still vulnerable to…*", do not stop at verifying the named risk. Ask what the author was fundamentally worried about beneath the specific term they chose. The named vulnerability is one point on a curve. The curve is almost always more interesting than the point.