
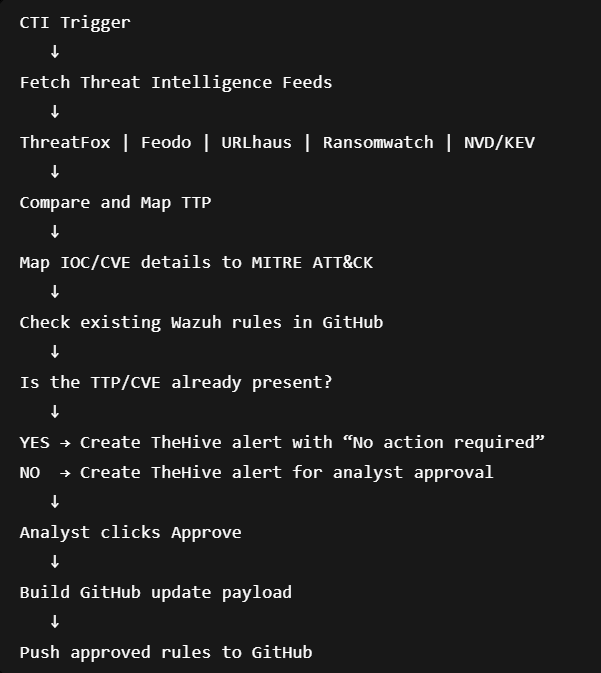
- This project is a Threat Intelligence Automation Pipeline built using Shuffle SOAR, TheHive, GitHub, and Wazuh rule mapping.
- The goal is to automatically fetch the latest threat intelligence from multiple sources, extract IOCs/CVEs, map them to MITRE ATT&CK TTPs, and check whether detection rules already exist in the GitHub Wazuh rules repository.
- If a new TTP or new CVE is not already present in GitHub, the workflow creates an alert in TheHive for analyst review.
- After analyst approval, the workflow automatically updates the GitHub rules file with the new approved rule details and date.
Threat Intel Sources Used
- ThreatFox — fetches recent malware IOCs, C2 domains, IPs, and payload-related indicators.
- Feodo Tracker — fetches active botnet C2 IP blocklists.
- URLhaus / Phishing URL Feed — fetches malicious URLs and payload delivery links.
- Ransomwatch — fetches ransomware group-related intelligence.
- NVD / KEV-based CVE Feed — fetches exploited CVEs and zero-day style vulnerability intelligence.
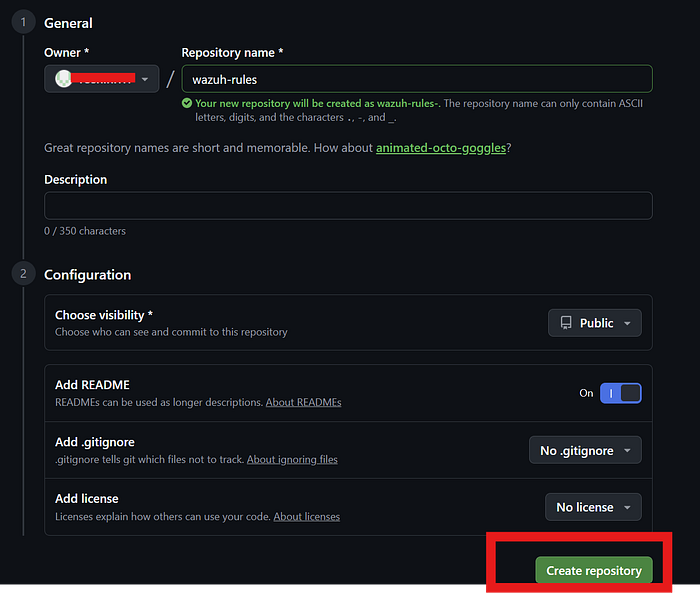
We'll store existing_rules.json on GitHub so Shuffle can fetch it via URL anytime.
1. Go to github.com and login
2. Click the "+" icon top right → "New repository"
3. Name it:
wazuh-rules4. Set it to Public
5. Check "Add a README file"
6. Click "Create repository"
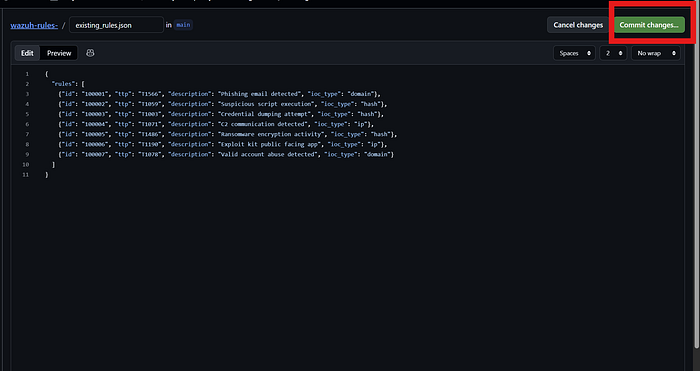
On your repo page click "Add file" → "Create new file"
2. In the filename field type:
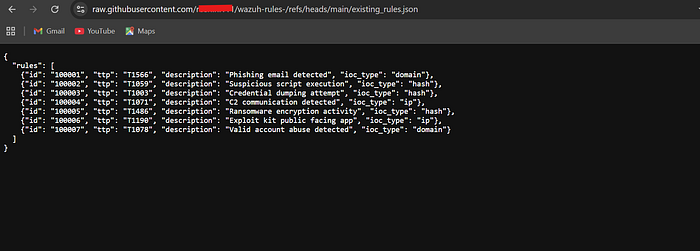
existing_rules.json3. In the content area paste exactly this:
json
{
"rules": [
{"id": "100001", "ttp": "T1566", "description": "Phishing email detected", "ioc_type": "domain"},
{"id": "100002", "ttp": "T1059", "description": "Suspicious script execution", "ioc_type": "hash"},
{"id": "100003", "ttp": "T1003", "description": "Credential dumping attempt", "ioc_type": "hash"},
{"id": "100004", "ttp": "T1071", "description": "C2 communication detected", "ioc_type": "ip"},
{"id": "100005", "ttp": "T1486", "description": "Ransomware encryption activity", "ioc_type": "hash"},
{"id": "100006", "ttp": "T1190", "description": "Exploit kit public facing app", "ioc_type": "ip"},
{"id": "100007", "ttp": "T1078", "description": "Valid account abuse detected", "ioc_type": "domain"}
]
}4. Scroll down → click "Commit changes" → click "Commit changes" again on the popup
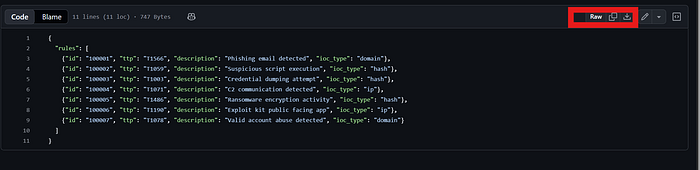
Till now we have:
- A GitHub repo with your existing Wazuh rules(or you could launch a wazuh on cloud and do it maybe in further blogs I would show you )
- why I chose this method is that you get a basic understanding on the project we might advance later
- A raw URL Shuffle can fetch anytime
- 7 baseline TTPs already defined
- In Shuffle click "+" or "New Workflow"
- Name it:
CTI_TTP_MonitorClick Save/Create
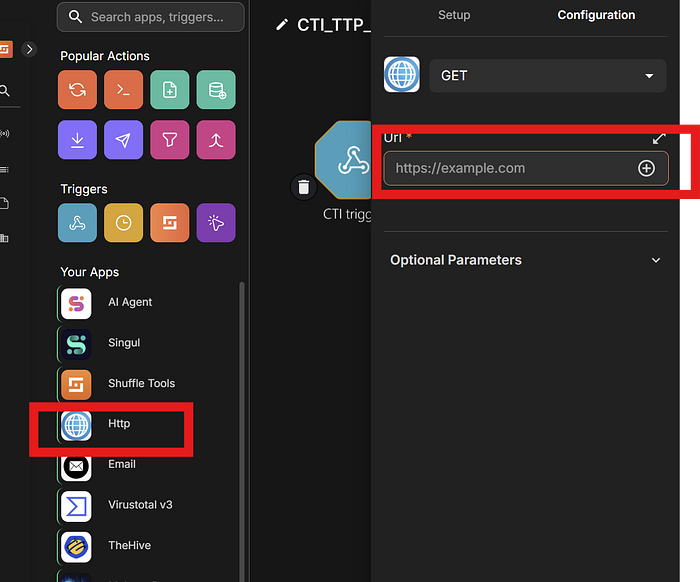
Drag Http from left sidebar onto canvas
Connect Fetch_Existing_Rules → this new Http node
Click it and fill in:
https://raw.githubusercontent.com/paste your github repo url==============================================================
Next attach the fetch existing rules to Fetch_ThreatFox
Action: GET
URL:
https://threatfox.abuse.ch/export/csv/recent/4. Save it ===============================================================
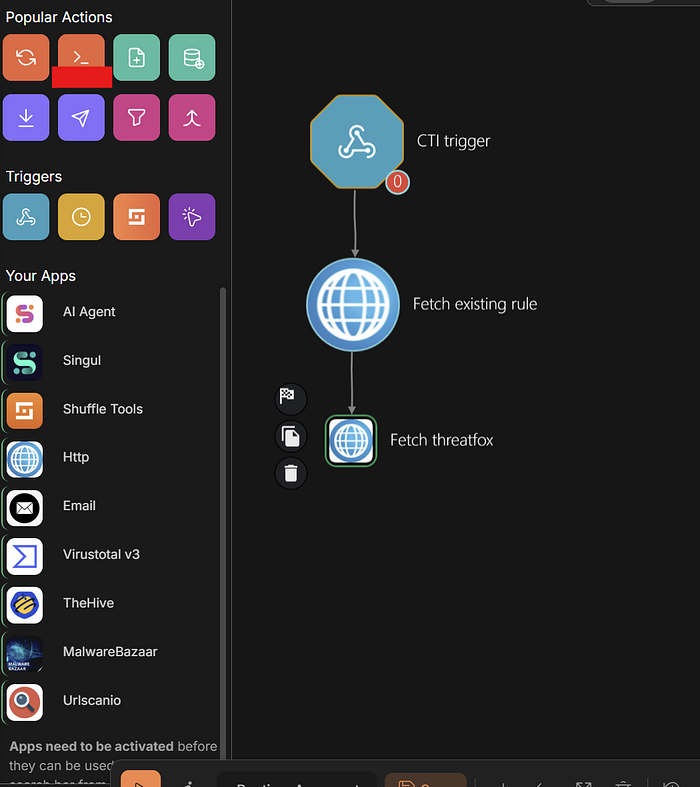
then attach to Fetch_Feodo_C2
Action: GET
URL:
https://feodotracker.abuse.ch/downloads/ipblocklist.txt=============================================================== Fetch_Feodo_C2 to Fetch_URLhaus
Action: GET
URL:
https://feodotracker.abuse.ch/downloads/ipblocklist.txt===============================================================
Fetch_URLhaus to Fetch_Zeroday
Action: GET
URL:
https://services.nvd.nist.gov/rest/json/cves/2.0?resultsPerPage=20&kevStartDate=2026-01-19T00:00:00.000Z&kevEndDate=2026-05-18T23:59:59.000Z&noRejected===============================================================
Fetch_Zeroday to Fetch_Ransomware
Action: GET
URL:
https://raw.githubusercontent.com/joshhighet/ransomwatch/main/groups.json===============================================================
Fetch_Ransomware to Compare_and_Map_TTP (variation 1)
paste this code in python compile
import json
import csv
import io
existing_rules_raw = """$fetch_existing_rules.body"""
existing_ttps = set()
try:
rules_data = json.loads(existing_rules_raw)
for rule in rules_data.get("rules", []):
existing_ttps.add(rule.get("ttp", ""))
except Exception as e:
existing_ttps = set()
MITRE_MAP = {
"emotet": ["T1566", "Initial Access", "Phishing"],
"cobalt": ["T1059", "Execution", "Command Scripting"],
"mimikatz": ["T1003", "Credential Access", "Credential Dumping"],
"ransomware": ["T1486", "Impact", "Data Encrypted"],
"c2": ["T1071", "Command Control", "C2 Communication"],
"phishing": ["T1566", "Initial Access", "Phishing"],
"exploit": ["T1203", "Execution", "Exploitation"],
"stealer": ["T1555", "Credential Access", "Credential Stores"],
"backdoor": ["T1543", "Persistence", "System Process"],
"keylogger": ["T1056", "Collection", "Input Capture"],
"botnet": ["T1583", "Resource Dev", "Infrastructure"],
"rat": ["T1219", "Command Control", "Remote Access"],
"trojan": ["T1204", "Execution", "User Execution"],
"worm": ["T1091", "Lateral Movement", "Removable Media"],
}
threatfox_raw = """$fetch_threatfox.body"""
new_findings = []
seen_iocs = set()
lines = threatfox_raw.splitlines()
for line in lines:
if line.startswith("#") or not line.strip():
continue
parts = line.split(",")
if len(parts) < 3:
continue
ioc_value = parts[2].strip().strip('"')
ioc_type = parts[3].strip().strip('"') if len(parts) > 3 else ""
malware = parts[4].strip().strip('"').lower() if len(parts) > 4 else ""
confidence = parts[5].strip().strip('"') if len(parts) > 5 else ""
if ioc_value in seen_iocs:
continue
seen_iocs.add(ioc_value)
matched = None
for keyword, vals in MITRE_MAP.items():
if keyword in malware:
matched = vals
break
if not matched:
continue
if matched[0] in existing_ttps:
continue
new_findings.append({
"ioc": ioc_value,
"ioc_type": ioc_type,
"malware": malware,
"ttp": matched[0],
"tactic": matched[1],
"technique": matched[2],
"confidence": confidence
})
print(json.dumps(new_findings[:20]))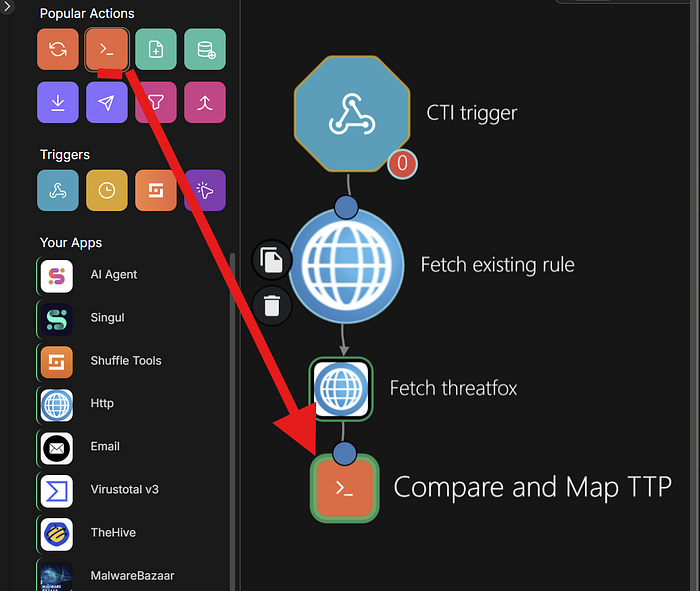
and also keep you're webhook running set it to start
paste the below code in python in build report
import json
import re
from datetime import datetime
def get_body(raw):
if isinstance(raw, str):
try:
parsed = json.loads(raw)
return parsed.get("body", "")
except:
return raw
elif isinstance(raw, dict):
return raw.get("body", "")
return ""
MITRE_MAP = {
"emotet": ["T1566", "Initial Access", "Phishing"],
"cobalt": ["T1059", "Execution", "Command Scripting"],
"mimikatz": ["T1003", "Credential Access", "Credential Dumping"],
"ransomware": ["T1486", "Impact", "Data Encrypted"],
"lockbit": ["T1486", "Impact", "Data Encrypted"],
"blackcat": ["T1486", "Impact", "Data Encrypted"],
"alphv": ["T1486", "Impact", "Data Encrypted"],
"c2": ["T1071", "Command Control", "C2 Communication"],
"phishing": ["T1566", "Initial Access", "Phishing"],
"exploit": ["T1203", "Execution", "Exploitation"],
"stealer": ["T1555", "Credential Access", "Credential Stores"],
"backdoor": ["T1543", "Persistence", "System Process"],
"keylogger": ["T1056", "Collection", "Input Capture"],
"botnet": ["T1583", "Resource Dev", "Infrastructure"],
"rat": ["T1219", "Command Control", "Remote Access"],
"trojan": ["T1204", "Execution", "User Execution"],
"worm": ["T1091", "Lateral Movement", "Removable Media"],
"infostealer": ["T1555", "Credential Access", "Credential Stores"],
"loader": ["T1204", "Execution", "User Execution"],
"buffer": ["T1203", "Execution", "Exploitation"],
"overflow": ["T1203", "Execution", "Exploitation"],
"injection": ["T1055", "Defense Evasion", "Process Injection"],
"privilege": ["T1068", "Privilege Esc", "Exploitation"],
"remote code": ["T1210", "Lateral Movement", "Remote Exploitation"],
}
new_findings = []
seen_iocs = set()
def is_valid_ioc(ioc):
# Skip JSON wrapper junk
if not ioc or len(ioc) < 4 or len(ioc) > 300:
return False
if ioc.startswith("{") or ioc.startswith("[") or "status" in ioc.lower():
return False
if '"' in ioc or "body" in ioc.lower():
return False
return True
def match_ttp(text):
text = text.lower()
for keyword, vals in MITRE_MAP.items():
if keyword in text:
return vals
return None
def add_finding(ioc, ioc_type, malware, source, confidence="N/A"):
if not is_valid_ioc(ioc) or ioc in seen_iocs:
return
matched = match_ttp(malware)
if not matched:
return
seen_iocs.add(ioc)
new_findings.append({
"ioc": ioc,
"ioc_type": ioc_type,
"malware": malware,
"ttp": matched[0],
"tactic": matched[1],
"technique": matched[2],
"confidence": confidence,
"source": source
})
# ── 1. ThreatFox ──
try:
body = get_body("""$fetch_threatfox""")
for line in body.splitlines():
if line.startswith("#") or not line.strip():
continue
parts = line.split(",")
if len(parts) < 3:
continue
ioc_value = parts[2].strip().strip('"')
ioc_type = parts[3].strip().strip('"') if len(parts) > 3 else ""
malware = parts[4].strip().strip('"').lower() if len(parts) > 4 else ""
confidence = parts[5].strip().strip('"') if len(parts) > 5 else "N/A"
add_finding(ioc_value, ioc_type, malware, "ThreatFox", confidence)
except:
pass
# ── 2. Feodo C2 IPs ──
try:
body = get_body("""$fetch_feodo_c2""")
for line in body.splitlines():
line = line.strip()
if line.startswith("#") or not line:
continue
# Only valid IPv4 addresses
if re.match(r'^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$', line):
add_finding(line, "ip", "c2", "FeodoTracker", "High")
except:
pass
# ── 3. OpenPhish URLs ──
try:
body = get_body("""$fetch_urlhaus""")
for line in body.splitlines():
line = line.strip()
if not line:
continue
# Only valid URLs
if line.startswith("http://") or line.startswith("https://"):
add_finding(line, "url", "phishing", "OpenPhish", "Medium")
except:
pass
# ── 4. Ransomwatch Groups ──
try:
body = get_body("""$fetch_ransomware""")
if isinstance(body, str):
groups = json.loads(body)
else:
groups = body
if isinstance(groups, list):
for group in groups[:50]:
if not isinstance(group, dict):
continue
name = group.get("name", "").lower()
meta = group.get("meta", "").lower()
combined = name + " " + meta + " ransomware"
if name and len(name) < 100:
add_finding(name, "ransomware_group", combined, "Ransomwatch", "High")
except:
pass
# ── 5. NVD Zero-Day CVEs ──
try:
body = get_body("""$fetch_zeroday""")
if isinstance(body, str):
nvd_data = json.loads(body)
else:
nvd_data = body
vulns = nvd_data.get("vulnerabilities", []) if isinstance(nvd_data, dict) else []
for v in vulns:
cve = v.get("cve", {})
cve_id = cve.get("id", "")
descs = cve.get("descriptions", [])
desc = next((d["value"] for d in descs if d.get("lang") == "en"), "")
if cve_id:
add_finding(cve_id, "cve", desc, "NVD-NIST", "Critical")
except:
pass
# ── GROUPED REPORT ──
date = datetime.utcnow().strftime("%Y-%m-%d %H:%M UTC")
report = "SOC THREAT INTEL REPORT\n"
report += "========================\n"
report += "Date: " + date + "\n"
report += "Total New TTPs: " + str(len(new_findings)) + "\n\n"
if len(new_findings) == 0:
report += "No new TTPs detected.\n"
else:
sources = {}
for f in new_findings:
src = f["source"]
if src not in sources:
sources[src] = []
sources[src].append(f)
for src, items in sources.items():
report += "=== " + src + " (" + str(len(items)) + " findings) ===\n\n"
for f in items[:10]:
report += "IOC : " + f.get("ioc", "N/A") + "\n"
report += "Malware : " + f.get("malware", "N/A")[:80] + "\n"
report += "MITRE TTP : " + f.get("ttp", "N/A") + "\n"
report += "Tactic : " + f.get("tactic", "N/A") + "\n"
report += "Technique : " + f.get("technique", "N/A") + "\n"
report += "Confidence : " + f.get("confidence", "N/A") + "\n"
report += "---\n"
if len(items) > 10:
report += "... and " + str(len(items) - 10) + " more\n"
report += "\n"
report += "========================\n"
report += "ACTION REQUIRED:\n"
report += "Review Wazuh rules: https://github.com/roshini111/wazuh-rules-\n"
report += "Reply APPROVE or REJECT.\n"
print(report)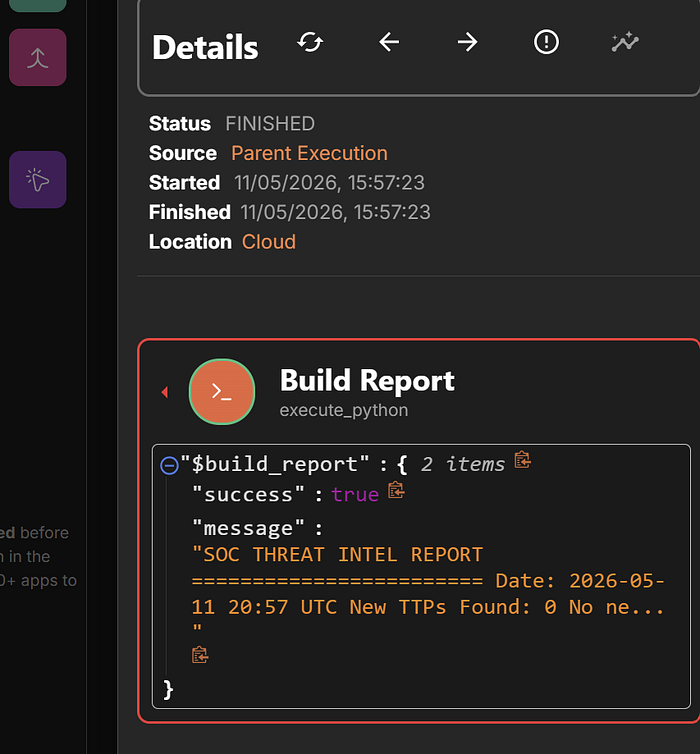
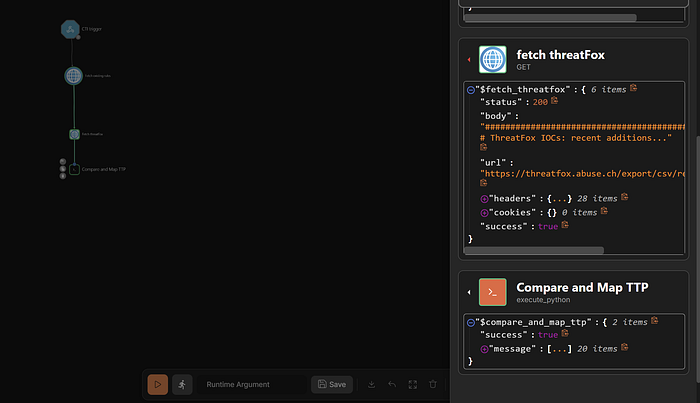
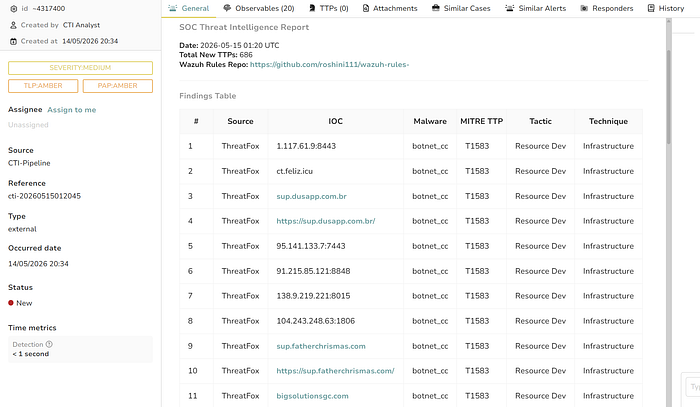
"New TTPs Found: 0" means all TTPs from ThreatFox are already covered by your existing rules the deduplication is working correctly!
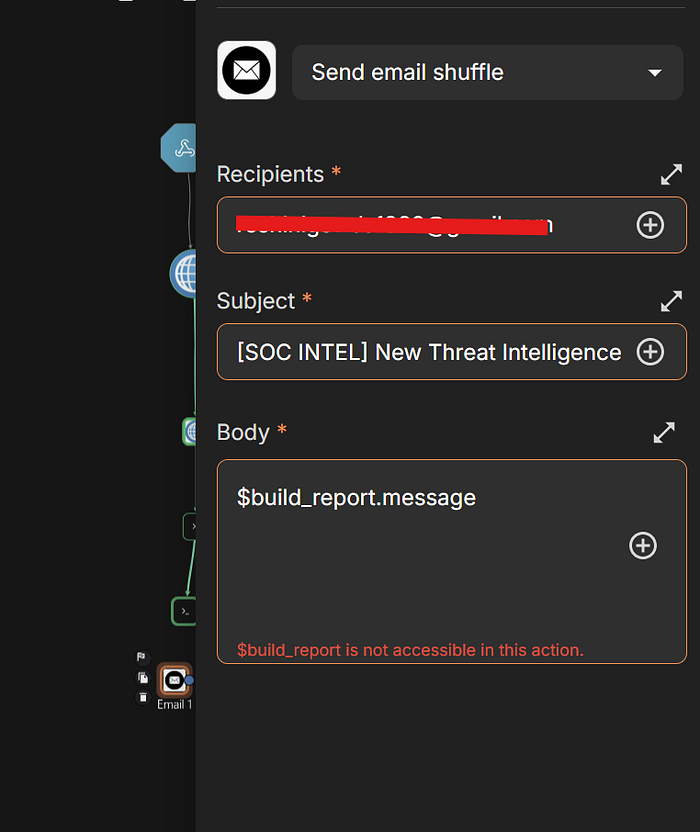

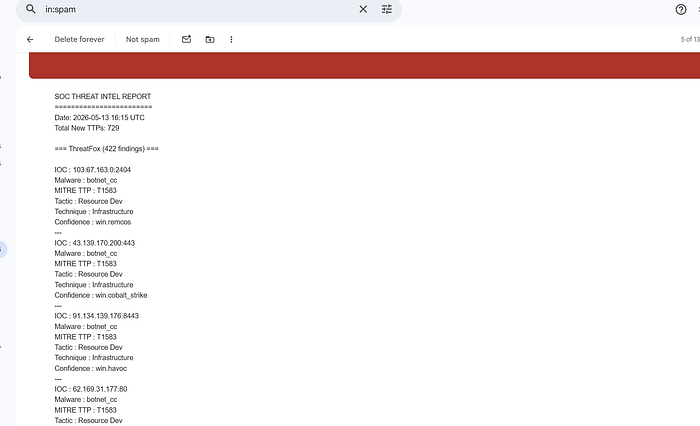
Till this stage, the basic project workflow has been completed successfully. I am currently unable to proceed with the email notification part because my free email quota has been exhausted. As the next step, I will continue the execution and approval process through TheHive instead.
===============================================================
For now, I will install and configure TheHive by referring to my previous SOC automation blog, where I have already documented the setup process step by step.(https://medium.com/@Commoness/list/soc-automation-project-4c0fbf01245c)


this is the code for the above output hence its creating space issue hence I am gonna add just top 20 as of now which would be posted in next picture
import json
import re
from datetime import datetime
def get_body(raw):
if isinstance(raw, str):
try:
parsed = json.loads(raw)
return parsed.get("body", "")
except:
return raw
elif isinstance(raw, dict):
return raw.get("body", "")
return ""
def sanitize(text):
if not text:
return ""
text = str(text).replace('"', "'").replace("\n", " ").replace("\r", " ").replace("\\", "/").replace("|", "-")
return text[:150]
MITRE_MAP = {
"emotet": ["T1566", "Initial Access", "Phishing"],
"cobalt": ["T1059", "Execution", "Command Scripting"],
"mimikatz": ["T1003", "Credential Access", "Credential Dumping"],
"ransomware": ["T1486", "Impact", "Data Encrypted"],
"lockbit": ["T1486", "Impact", "Data Encrypted"],
"blackcat": ["T1486", "Impact", "Data Encrypted"],
"alphv": ["T1486", "Impact", "Data Encrypted"],
"c2": ["T1071", "Command Control", "C2 Communication"],
"phishing": ["T1566", "Initial Access", "Phishing"],
"exploit": ["T1203", "Execution", "Exploitation"],
"stealer": ["T1555", "Credential Access", "Credential Stores"],
"backdoor": ["T1543", "Persistence", "System Process"],
"keylogger": ["T1056", "Collection", "Input Capture"],
"botnet": ["T1583", "Resource Dev", "Infrastructure"],
"rat": ["T1219", "Command Control", "Remote Access"],
"trojan": ["T1204", "Execution", "User Execution"],
"worm": ["T1091", "Lateral Movement", "Removable Media"],
"infostealer": ["T1555", "Credential Access", "Credential Stores"],
"loader": ["T1204", "Execution", "User Execution"],
"buffer": ["T1203", "Execution", "Exploitation"],
"overflow": ["T1203", "Execution", "Exploitation"],
"injection": ["T1055", "Defense Evasion", "Process Injection"],
"privilege": ["T1068", "Privilege Esc", "Exploitation"],
"remote code": ["T1210", "Lateral Movement", "Remote Exploitation"],
}
new_findings = []
seen_iocs = set()
def is_valid_ioc(ioc):
if not ioc or len(ioc) < 4 or len(ioc) > 300:
return False
if ioc.startswith("{") or ioc.startswith("[") or "status" in ioc.lower():
return False
if '"' in ioc or "body" in ioc.lower():
return False
return True
def match_ttp(text):
text = text.lower()
for keyword, vals in MITRE_MAP.items():
if keyword in text:
return vals
return None
def add_finding(ioc, ioc_type, malware, source, confidence="N/A"):
if not is_valid_ioc(ioc) or ioc in seen_iocs:
return
matched = match_ttp(malware)
if not matched:
return
seen_iocs.add(ioc)
new_findings.append({
"ioc": ioc,
"ioc_type": ioc_type,
"malware": malware,
"ttp": matched[0],
"tactic": matched[1],
"technique": matched[2],
"confidence": confidence,
"source": source
})
try:
body = get_body("""$fetch_threatfox""")
for line in body.splitlines():
if line.startswith("#") or not line.strip():
continue
parts = line.split(",")
if len(parts) < 3:
continue
ioc_value = parts[2].strip().strip('"')
ioc_type = parts[3].strip().strip('"') if len(parts) > 3 else ""
malware = parts[4].strip().strip('"').lower() if len(parts) > 4 else ""
confidence = parts[5].strip().strip('"') if len(parts) > 5 else "N/A"
add_finding(ioc_value, ioc_type, malware, "ThreatFox", confidence)
except:
pass
try:
body = get_body("""$fetch_feodo_c2""")
for line in body.splitlines():
line = line.strip()
if line.startswith("#") or not line:
continue
if re.match(r'^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$', line):
add_finding(line, "ip", "c2", "FeodoTracker", "High")
except:
pass
try:
body = get_body("""$fetch_urlhaus""")
for line in body.splitlines():
line = line.strip()
if not line:
continue
if line.startswith("http://") or line.startswith("https://"):
add_finding(line, "url", "phishing", "OpenPhish", "Medium")
except:
pass
try:
body = get_body("""$fetch_ransomware""")
if isinstance(body, str):
groups = json.loads(body)
else:
groups = body
if isinstance(groups, list):
for group in groups[:50]:
if not isinstance(group, dict):
continue
name = group.get("name", "").lower()
meta = group.get("meta", "").lower()
combined = name + " " + meta + " ransomware"
if name and len(name) < 100:
add_finding(name, "ransomware_group", combined, "Ransomwatch", "High")
except:
pass
try:
body = get_body("""$fetch_zeroday""")
if isinstance(body, str):
nvd_data = json.loads(body)
else:
nvd_data = body
vulns = nvd_data.get("vulnerabilities", []) if isinstance(nvd_data, dict) else []
for v in vulns:
cve = v.get("cve", {})
cve_id = cve.get("id", "")
descs = cve.get("descriptions", [])
desc = next((d["value"] for d in descs if d.get("lang") == "en"), "")
if cve_id:
add_finding(cve_id, "cve", desc, "NVD-NIST", "Critical")
except:
pass
date = datetime.utcnow().strftime("%Y-%m-%d %H:%M UTC")
# ── BUILD MARKDOWN TABLE FOR THEHIVE ──
table = "## SOC Threat Intelligence Report\n\n"
table += "**Date:** " + date + "\n\n"
table += "**Total New TTPs:** " + str(len(new_findings)) + "\n\n"
table += "**Wazuh Rules Repo:** https://github.com/roshini111/wazuh-rules-\n\n"
table += "---\n\n"
table += "### Findings Table\n\n"
table += "| # | Source | IOC | Malware | MITRE TTP | Tactic | Technique |\n"
table += "|---|--------|-----|---------|-----------|--------|----------|\n"
for i, f in enumerate(new_findings[:50], 1):
table += "| " + str(i)
table += " | " + sanitize(f.get("source", "N/A"))[:20]
table += " | " + sanitize(f.get("ioc", "N/A"))[:40]
table += " | " + sanitize(f.get("malware", "N/A"))[:25]
table += " | " + sanitize(f.get("ttp", "N/A"))
table += " | " + sanitize(f.get("tactic", "N/A"))
table += " | " + sanitize(f.get("technique", "N/A"))
table += " |\n"
if len(new_findings) > 50:
table += "\n*... and " + str(len(new_findings) - 50) + " more findings*\n"
table += "\n---\n\n"
table += "### Summary by Source\n\n"
sources_count = {}
for f in new_findings:
s = f["source"]
sources_count[s] = sources_count.get(s, 0) + 1
table += "| Source | Count |\n|--------|-------|\n"
for s, c in sources_count.items():
table += "| " + s + " | " + str(c) + " |\n"
alert_payload = {
"title": "CTI Alert - " + str(len(new_findings)) + " New Threats Detected",
"description": table,
"type": "external",
"source": "CTI-Pipeline",
"sourceRef": "cti-" + datetime.utcnow().strftime("%Y%m%d%H%M%S"),
"severity": 2,
"tlp": 2,
"pap": 2,
"tags": ["cti", "automation", "mitre", "wazuh"],
"observables": []
}
for f in new_findings[:20]:
data_type = f.get("ioc_type", "other").lower()
if data_type in ["ip", "ipv4"]:
data_type = "ip"
elif data_type == "url":
data_type = "url"
elif data_type in ["domain", "hostname"]:
data_type = "domain"
else:
data_type = "other"
alert_payload["observables"].append({
"dataType": data_type,
"data": sanitize(f.get("ioc", "N/A")),
"message": sanitize(
"Source: " + f.get("source", "N/A") +
" | Malware: " + f.get("malware", "N/A") +
" | TTP: " + f.get("ttp", "N/A") +
" | Tactic: " + f.get("tactic", "N/A") +
" | Technique: " + f.get("technique", "N/A")
)
})
print(json.dumps(alert_payload))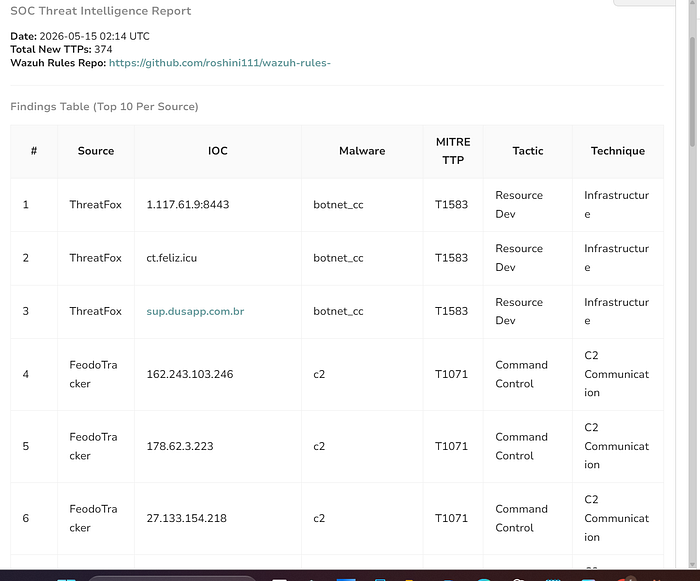
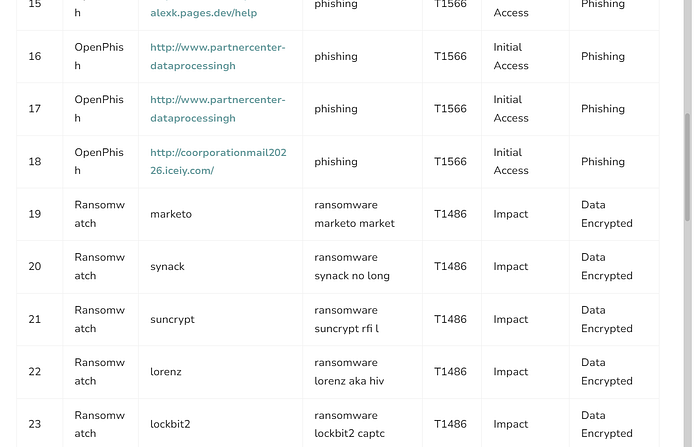
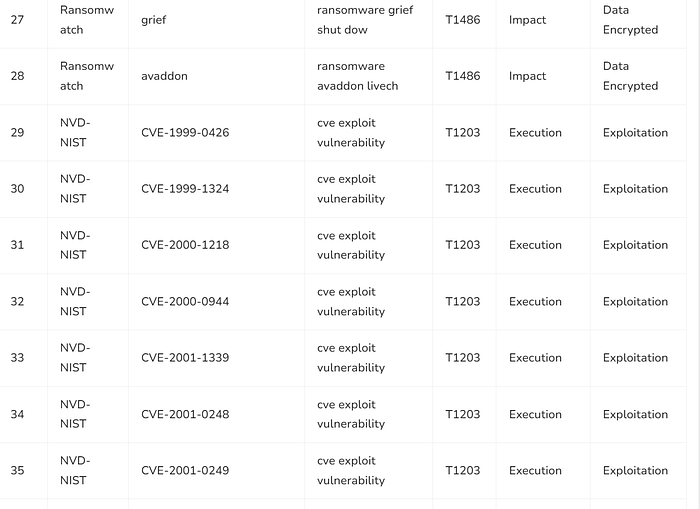
===============================================================
The code for this workflow is attached below. I will still be improving and expanding this project further, so this blog might become slightly longer over time as I continue advancing the automation process.
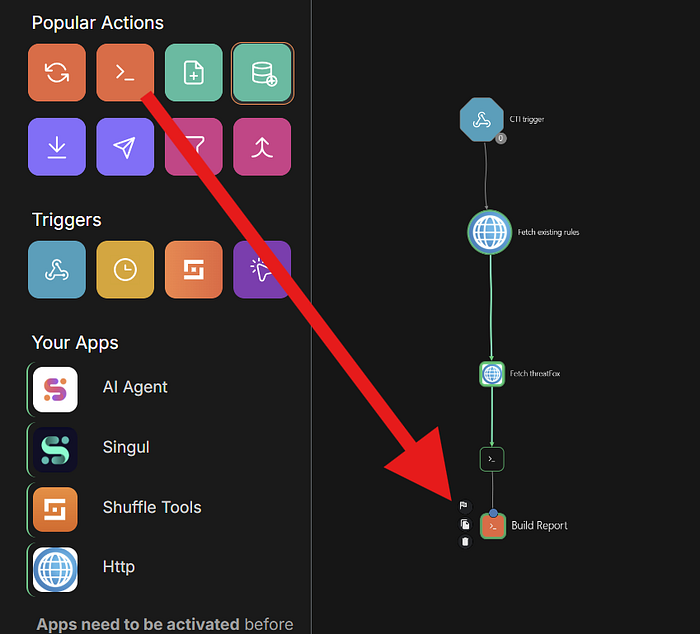
In my previous version, the workflow directly connected the generated report to TheHive after the report-building stage. However, in this updated version, I wanted the pipeline to automatically create and update detection rules in GitHub before sending the final alert to TheHive.
Because of that, I introduced additional stages into the workflow such as:
- GitHub SHA retrieval
- Build GitHub update payload
- GitHub rule update logic
- GitHub push automation
Only after these stages are completed does the workflow proceed to TheHive for analyst review and alert management.
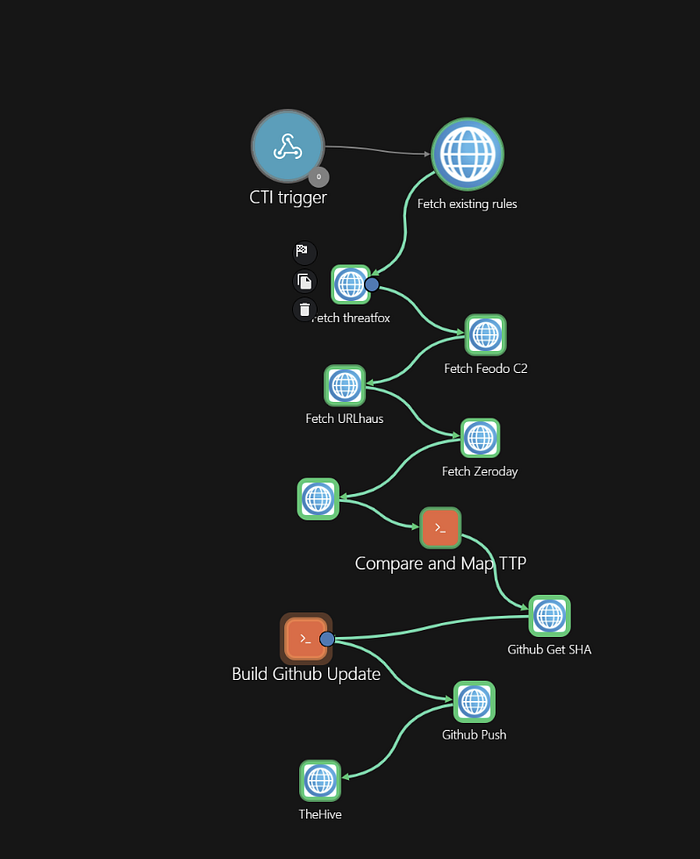
now again change the code for compare and map ttp
import json
import re
import csv
import ast
import base64
from io import StringIO
from datetime import datetime
# ─────────────────────────────────────────────
# CONFIG
# ─────────────────────────────────────────────
GITHUB_REPO = "roshini111/wazuh-rules-"
APPROVAL_WEBHOOK = "https://shuffler.io/api/v1/hooks/webhook_6cfc2dd1-a9b1-4e21-988a-6cdd707de425"
# ─────────────────────────────────────────────
# RAW SHUFFLE INPUTS
# These names must match your Shuffle node names exactly
# ─────────────────────────────────────────────
RAW_EXISTING = """$fetch_existing_rules"""
RAW_EXISTING_BODY = """$fetch_existing_rules.body"""
RAW_THREATFOX = """$fetch_threatfox"""
RAW_THREATFOX_BODY = """$fetch_threatfox.body"""
RAW_FEODO = """$fetch_feodo_c2"""
RAW_FEODO_BODY = """$fetch_feodo_c2.body"""
RAW_URLHAUS = """$fetch_urlhaus"""
RAW_URLHAUS_BODY = """$fetch_urlhaus.body"""
RAW_RANSOMWARE = """$fetch_ransomware"""
RAW_RANSOMWARE_BODY = """$fetch_ransomware.body"""
RAW_ZERODAY = """$fetch_zeroday"""
RAW_ZERODAY_BODY = """$fetch_zeroday.body"""
debug_info = {}
# ─────────────────────────────────────────────
# HELPERS
# ─────────────────────────────────────────────
def sanitize(text):
if not text:
return ""
text = str(text)
text = text.replace('"', "'")
text = text.replace("\n", " ")
text = text.replace("\r", " ")
text = text.replace("\\", "/")
text = text.replace("|", "-")
return text[:150]
def parse_shuffle_json(raw_full, raw_body, label):
debug_info[label + "_raw_len"] = len(str(raw_full))
debug_info[label + "_body_len"] = len(str(raw_body))
debug_info[label + "_raw_preview"] = str(raw_full)[:250]
debug_info[label + "_body_preview"] = str(raw_body)[:250]
for raw in [raw_body, raw_full]:
if raw is None:
continue
if isinstance(raw, dict):
if "body" in raw:
return raw["body"]
return raw
if isinstance(raw, list):
return raw
s = str(raw).strip()
if not s:
continue
if "CLEANED after finishing" in s:
debug_info[label + "_problem"] = "Shuffle cleaned this output."
return None
try:
parsed = json.loads(s, strict=False)
if isinstance(parsed, dict) and "body" in parsed:
return parsed["body"]
return parsed
except Exception as e:
debug_info[label + "_json_error"] = str(e)[:150]
try:
parsed = ast.literal_eval(s)
if isinstance(parsed, dict) and "body" in parsed:
return parsed["body"]
return parsed
except Exception as e:
debug_info[label + "_ast_error"] = str(e)[:150]
return None
def parse_shuffle_text(raw_full, raw_body, label):
debug_info[label + "_raw_len"] = len(str(raw_full))
debug_info[label + "_body_len"] = len(str(raw_body))
debug_info[label + "_raw_preview"] = str(raw_full)[:250]
debug_info[label + "_body_preview"] = str(raw_body)[:250]
if raw_body and len(str(raw_body).strip()) > 0:
return str(raw_body)
s = str(raw_full).strip()
if not s:
return ""
if "CLEANED after finishing" in s:
debug_info[label + "_problem"] = "Shuffle cleaned this output."
return ""
try:
parsed = json.loads(s, strict=False)
if isinstance(parsed, dict) and "body" in parsed:
return str(parsed.get("body", ""))
except Exception as e:
debug_info[label + "_text_json_error"] = str(e)[:150]
return s
MITRE_MAP = {
"emotet": ["T1566", "Initial Access", "Phishing"],
"phishing": ["T1566", "Initial Access", "Phishing"],
"cobalt": ["T1059", "Execution", "Command and Scripting Interpreter"],
"powershell": ["T1059", "Execution", "Command and Scripting Interpreter"],
"command": ["T1059", "Execution", "Command and Scripting Interpreter"],
"mimikatz": ["T1003", "Credential Access", "Credential Dumping"],
"credential": ["T1003", "Credential Access", "Credential Dumping"],
"ransomware": ["T1486", "Impact", "Data Encrypted for Impact"],
"lockbit": ["T1486", "Impact", "Data Encrypted for Impact"],
"blackcat": ["T1486", "Impact", "Data Encrypted for Impact"],
"alphv": ["T1486", "Impact", "Data Encrypted for Impact"],
"group": ["T1486", "Impact", "Data Encrypted for Impact"],
"c2": ["T1071", "Command and Control", "Application Layer Protocol"],
"botnet": ["T1071", "Command and Control", "Application Layer Protocol"],
"botnet_cc": ["T1071", "Command and Control", "Application Layer Protocol"],
"payload_delivery": ["T1204", "Execution", "User Execution"],
"malware": ["T1204", "Execution", "User Execution"],
"trojan": ["T1204", "Execution", "User Execution"],
"loader": ["T1204", "Execution", "User Execution"],
"downloader": ["T1204", "Execution", "User Execution"],
"exploit": ["T1203", "Execution", "Exploitation for Client Execution"],
"cve": ["T1203", "Execution", "Exploitation for Client Execution"],
"vulnerability": ["T1203", "Execution", "Exploitation for Client Execution"],
"zero day": ["T1203", "Execution", "Exploitation for Client Execution"],
"stealer": ["T1555", "Credential Access", "Credentials from Password Stores"],
"infostealer": ["T1555", "Credential Access", "Credentials from Password Stores"],
"backdoor": ["T1543", "Persistence", "Create or Modify System Process"],
"keylogger": ["T1056", "Collection", "Input Capture"],
"rat": ["T1219", "Command and Control", "Remote Access Software"],
"worm": ["T1091", "Lateral Movement", "Replication Through Removable Media"],
"injection": ["T1055", "Defense Evasion", "Process Injection"],
"privilege": ["T1068", "Privilege Escalation", "Exploitation for Privilege Escalation"],
"remote code": ["T1210", "Lateral Movement", "Exploitation of Remote Services"]
}
new_findings = []
seen_iocs = set()
def match_ttp(text):
text = str(text).lower()
for keyword, values in MITRE_MAP.items():
if keyword in text:
return values
return None
def add_finding(ioc, ioc_type, malware, source, confidence="N/A"):
if not ioc:
return
ioc = str(ioc).strip()
if len(ioc) < 3 or len(ioc) > 300:
return
unique_key = source + "|" + ioc
if unique_key in seen_iocs:
return
matched = match_ttp(malware)
if not matched:
matched = match_ttp(ioc_type)
if not matched:
return
seen_iocs.add(unique_key)
new_findings.append({
"ioc": ioc,
"ioc_type": str(ioc_type),
"malware": str(malware),
"ttp": matched[0],
"tactic": matched[1],
"technique": matched[2],
"confidence": str(confidence),
"source": source
})
# ─────────────────────────────────────────────
# EXISTING GITHUB RULES
# Collect existing TTPs and existing CVE IDs
# ─────────────────────────────────────────────
existing_ttps = set()
existing_cves = set()
existing_rule_text = ""
existing_rules_count = 0
try:
existing_data = parse_shuffle_json(RAW_EXISTING, RAW_EXISTING_BODY, "existing_rules")
rules = []
if isinstance(existing_data, dict):
rules = existing_data.get("rules", [])
elif isinstance(existing_data, list):
rules = existing_data
for rule in rules:
if not isinstance(rule, dict):
continue
existing_rules_count += 1
ttp = str(rule.get("ttp", "")).strip()
if ttp:
existing_ttps.add(ttp)
rule_text = json.dumps(rule).lower()
existing_rule_text += " " + rule_text
found_cves = re.findall(r"cve-\d{4}-\d+", rule_text)
for cve in found_cves:
existing_cves.add(cve.upper())
debug_info["existing_rules_found"] = existing_rules_count
debug_info["existing_ttps"] = sorted(list(existing_ttps))
debug_info["existing_cves_found"] = sorted(list(existing_cves))[:20]
except Exception as e:
debug_info["existing_rules_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# 1. THREATFOX CSV
# ─────────────────────────────────────────────
try:
body = parse_shuffle_text(RAW_THREATFOX, RAW_THREATFOX_BODY, "threatfox")
rows = 0
added = 0
for row in csv.reader(StringIO(body)):
if not row:
continue
if row[0].startswith("#"):
continue
rows += 1
if len(row) < 10:
continue
ioc_value = row[2].strip().strip("'")
ioc_type = row[3].strip().strip("'")
threat_type = row[4].strip().lower()
malware = row[5].strip().lower()
malware_printable = row[7].strip().lower()
confidence = row[9].strip()
combined = threat_type + " " + malware + " " + malware_printable + " malware c2"
before = len(new_findings)
add_finding(ioc_value, ioc_type, combined, "ThreatFox", confidence)
if len(new_findings) > before:
added += 1
debug_info["threatfox_rows"] = rows
debug_info["threatfox_added"] = added
except Exception as e:
debug_info["threatfox_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# 2. FEODO C2
# ─────────────────────────────────────────────
try:
body = parse_shuffle_text(RAW_FEODO, RAW_FEODO_BODY, "feodo")
added = 0
for line in body.splitlines():
line = line.strip()
if not line or line.startswith("#"):
continue
if re.match(r"^\d{1,3}(\.\d{1,3}){3}$", line):
before = len(new_findings)
add_finding(line, "ip", "c2 botnet malware", "FeodoTracker", "High")
if len(new_findings) > before:
added += 1
debug_info["feodo_added"] = added
except Exception as e:
debug_info["feodo_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# 3. URLHAUS / PHISHING URLS
# ─────────────────────────────────────────────
try:
body = parse_shuffle_text(RAW_URLHAUS, RAW_URLHAUS_BODY, "urlhaus")
added = 0
for line in body.splitlines():
line = line.strip()
if not line or line.startswith("#"):
continue
url_match = re.search(r"https?://[^\s,\"]+", line)
if url_match:
before = len(new_findings)
add_finding(url_match.group(0), "url", "payload_delivery malware phishing", "URLhaus", "Medium")
if len(new_findings) > before:
added += 1
debug_info["urlhaus_added"] = added
except Exception as e:
debug_info["urlhaus_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# 4. RANSOMWATCH
# ─────────────────────────────────────────────
try:
data = parse_shuffle_json(RAW_RANSOMWARE, RAW_RANSOMWARE_BODY, "ransomware")
checked = 0
added = 0
if isinstance(data, list):
for item in data[:150]:
if not isinstance(item, dict):
continue
checked += 1
name = item.get("name", "")
meta = item.get("meta", "")
if not name:
continue
meta_lower = str(meta).lower()
if "not a ransomware group" in meta_lower:
continue
combined = "ransomware group " + str(name).lower() + " " + meta_lower
before = len(new_findings)
add_finding(str(name).lower(), "ransomware_group", combined, "Ransomwatch", "High")
if len(new_findings) > before:
added += 1
debug_info["ransomware_type"] = str(type(data).__name__)
debug_info["ransomware_checked"] = checked
debug_info["ransomware_added"] = added
except Exception as e:
debug_info["ransomware_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# 5. NVD ZERO-DAY / CVE JSON
# ─────────────────────────────────────────────
try:
body = parse_shuffle_text(RAW_ZERODAY, RAW_ZERODAY_BODY, "zeroday")
checked = 0
added = 0
sample_cves = []
cve_ids = re.findall(r'"id"\s*:\s*"(CVE-\d{4}-\d+)"', body)
for cve_id in cve_ids[:20]:
checked += 1
sample_cves.append(cve_id)
combined = "cve exploit vulnerability zero day critical"
before = len(new_findings)
add_finding(cve_id, "cve", combined, "NVD-NIST", "Critical")
if len(new_findings) > before:
added += 1
debug_info["zeroday_type"] = "regex_text"
debug_info["zeroday_checked"] = checked
debug_info["zeroday_sample_cves"] = sample_cves[:5]
debug_info["zeroday_added"] = added
except Exception as e:
debug_info["zeroday_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# FIND ONLY RULES NOT PRESENT IN GITHUB
# Normal feeds compare by TTP
# NVD/Zeroday compares by CVE ID
# ─────────────────────────────────────────────
missing_by_key = {}
for finding in new_findings:
ttp = finding.get("ttp", "")
source = finding.get("source", "")
ioc = finding.get("ioc", "")
if not ttp:
continue
if source == "NVD-NIST":
cve_id = str(ioc).strip().upper()
if not cve_id.startswith("CVE-"):
continue
if cve_id in existing_cves:
continue
if cve_id.lower() in existing_rule_text:
continue
approval_key = "CVE|" + cve_id
else:
if ttp in existing_ttps:
continue
approval_key = "TTP|" + ttp
if approval_key not in missing_by_key:
missing_by_key[approval_key] = finding
missing_findings = list(missing_by_key.values())
debug_info["missing_rules_count"] = len(missing_findings)
debug_info["missing_rule_keys"] = list(missing_by_key.keys())[:30]
# ─────────────────────────────────────────────
# BUILD PENDING RULES FOR APPROVAL
# ─────────────────────────────────────────────
date = datetime.utcnow().strftime("%Y-%m-%d %H:%M UTC")
date_short = datetime.utcnow().strftime("%Y-%m-%d")
source_ref = "cti-" + datetime.utcnow().strftime("%Y%m%d%H%M%S")
pending_rules = []
for index, finding in enumerate(missing_findings, start=1):
pending_rules.append({
"id": "AUTO-" + date_short.replace("-", "") + "-" + sanitize(finding["ioc"]).replace(":", "-").replace("/", "-")[:30] + "-" + str(index).zfill(3),
"ttp": finding["ttp"],
"tactic": finding["tactic"],
"technique": finding["technique"],
"source": finding["source"],
"sample_ioc": finding["ioc"],
"ioc_type": finding["ioc_type"],
"malware_context": finding["malware"],
"created_date": date,
"status": "pending_analyst_approval",
"rule_name": "Detect " + finding["technique"] + " - " + finding["ttp"],
"description": "New CTI-mapped rule required from " + finding["source"] + ". For NVD-NIST, approval is based on CVE ID. Analyst approval required before GitHub update."
})
pending_rules_b64 = base64.b64encode(json.dumps({
"source_ref": source_ref,
"created_date": date,
"repo": GITHUB_REPO,
"existing_ttps": sorted(list(existing_ttps)),
"existing_cves": sorted(list(existing_cves)),
"pending_rules": pending_rules
}).encode()).decode()
# ─────────────────────────────────────────────
# BUILD THEHIVE REPORT
# ─────────────────────────────────────────────
table = "## SOC Threat Intelligence Report\n\n"
table += "**Date:** " + date + "\n\n"
table += "**Total TI Findings Collected:** " + str(len(new_findings)) + "\n\n"
table += "**Existing Rules in GitHub:** " + str(existing_rules_count) + "\n\n"
table += "**New Rules Needing Analyst Approval:** " + str(len(pending_rules)) + "\n\n"
table += "**Wazuh Rules Repo:** https://github.com/" + GITHUB_REPO + "\n\n"
table += "---\n\n"
table += "### New Rules Not Present in GitHub\n\n"
table += "| # | Source | Sample IOC / CVE | MITRE TTP | Tactic | Technique | Action |\n"
table += "|---|--------|------------------|-----------|--------|-----------|--------|\n"
if pending_rules:
counter = 1
for rule in pending_rules:
table += "| " + str(counter)
table += " | " + sanitize(rule["source"])
table += " | " + sanitize(rule["sample_ioc"])[:45]
table += " | " + sanitize(rule["ttp"])
table += " | " + sanitize(rule["tactic"])
table += " | " + sanitize(rule["technique"])
table += " | Needs analyst approval |\n"
counter += 1
else:
table += "| - | No missing rules | - | - | - | - | No action required |\n"
table += "\n---\n\n### Collection Summary by Source\n\n"
table += "| Source | Count |\n"
table += "|--------|-------|\n"
source_counts = {}
for finding in new_findings:
source = finding["source"]
source_counts[source] = source_counts.get(source, 0) + 1
if source_counts:
for source, count in source_counts.items():
table += "| " + sanitize(source) + " | " + str(count) + " |\n"
else:
table += "| None | 0 |\n"
table += "\n---\n\n### Analyst Approval\n\n"
if pending_rules:
table += "[APPROVE AND UPDATE GITHUB](" + APPROVAL_WEBHOOK + "?action=approve&ref=" + source_ref + ")\n\n"
table += "[REJECT](" + APPROVAL_WEBHOOK + "?action=reject&ref=" + source_ref + ")\n\n"
table += "If approved, only the missing rule(s) listed above should be added to GitHub with date `" + date_short + "`.\n"
else:
table += "No analyst approval needed. All detected TTPs/CVEs already exist in GitHub.\n"
table += "\n---\n\n### Debug Info\n\n"
table += "```json\n"
table += json.dumps(debug_info, indent=2)
table += "\n```\n"
# ─────────────────────────────────────────────
# THEHIVE ALERT PAYLOAD
# ─────────────────────────────────────────────
alert_payload = {
"title": "CTI Alert - " + str(len(pending_rules)) + " New Rule(s) Need Approval",
"description": table,
"type": "external",
"source": "CTI-Pipeline",
"sourceRef": source_ref,
"severity": 2,
"tlp": 2,
"pap": 2,
"tags": ["cti", "automation", "mitre", "wazuh", "approval-required"],
"customFields": {
"pending_rules_b64": {
"string": pending_rules_b64
}
},
"observables": []
}
for finding in missing_findings[:20]:
data_type = finding.get("ioc_type", "other").lower()
if data_type in ["ip", "ipv4"]:
data_type = "ip"
elif data_type == "url":
data_type = "url"
elif data_type in ["domain", "hostname", "domain_name"]:
data_type = "domain"
elif data_type in ["md5", "sha1", "sha256", "hash"]:
data_type = "hash"
elif data_type == "cve":
data_type = "other"
else:
data_type = "other"
alert_payload["observables"].append({
"dataType": data_type,
"data": sanitize(finding["ioc"]),
"message": sanitize(
"Needs new rule | Source: " + finding["source"] +
" | TTP: " + finding["ttp"] +
" | Technique: " + finding["technique"]
)
})
print(json.dumps(alert_payload))Github_Get_SHA
Action: get for the url : paste you're github repo url header paste : Authorization: Bearer api of your git Accept: application/vnd.github+json
==============================================================
Github_Get_SH to Build_Github_Update
import json
import base64
from datetime import datetime
# Pull pending rules directly from Compare and Map TTP
pending_b64 = """$compare_and_map_ttp.message.customFields.pending_rules_b64.string"""
# Pull current GitHub file body
github_sha_raw = """$github_get_sha.body"""
debug = {}
def parse_json_safe(raw, label):
try:
return json.loads(str(raw), strict=False)
except Exception as e:
debug[label + "_error"] = str(e)[:200]
return {}
# ─────────────────────────────────────────────
# DECODE PENDING RULES FROM COMPARE NODE
# ─────────────────────────────────────────────
pending_rules = []
try:
pending_b64 = str(pending_b64).strip()
if pending_b64 and not pending_b64.startswith("$"):
decoded = base64.b64decode(pending_b64).decode()
pending_data = json.loads(decoded)
pending_rules = pending_data.get("pending_rules", [])
else:
debug["pending_b64_status"] = "pending_rules_b64 missing or not replaced by Shuffle"
except Exception as e:
debug["pending_decode_error"] = str(e)[:200]
# ─────────────────────────────────────────────
# READ CURRENT GITHUB FILE
# ─────────────────────────────────────────────
github_data = parse_json_safe(github_sha_raw, "github_parse")
sha = github_data.get("sha", "")
content_b64 = github_data.get("content", "")
existing_rules_json = {
"rules": []
}
try:
if content_b64:
clean_content = content_b64.replace("\n", "")
existing_text = base64.b64decode(clean_content).decode()
existing_rules_json = json.loads(existing_text)
except Exception as e:
debug["github_content_decode_error"] = str(e)[:200]
rules = existing_rules_json.get("rules", [])
existing_ttps = set()
existing_cves = set()
existing_rule_text = json.dumps(rules).lower()
for rule in rules:
if not isinstance(rule, dict):
continue
ttp = str(rule.get("ttp", "")).strip()
if ttp:
existing_ttps.add(ttp)
cve = str(rule.get("cve", "")).strip().upper()
if cve:
existing_cves.add(cve)
# ─────────────────────────────────────────────
# ADD ONLY APPROVED NEW RULES
# ─────────────────────────────────────────────
added_rules = []
for rule in pending_rules:
if not isinstance(rule, dict):
continue
ttp = str(rule.get("ttp", "")).strip()
sample_ioc = str(rule.get("sample_ioc", "")).strip()
source = str(rule.get("source", "")).strip()
is_cve_rule = source == "NVD-NIST" and sample_ioc.upper().startswith("CVE-")
if is_cve_rule:
cve_id = sample_ioc.upper()
if cve_id in existing_cves:
continue
if cve_id.lower() in existing_rule_text:
continue
new_rule = {
"id": rule.get("id", ""),
"ttp": ttp,
"cve": cve_id,
"description": rule.get("description", ""),
"tactic": rule.get("tactic", ""),
"technique": rule.get("technique", ""),
"source": source,
"sample_ioc": sample_ioc,
"ioc_type": rule.get("ioc_type", "cve"),
"malware_context": rule.get("malware_context", ""),
"created_date": rule.get("created_date", datetime.utcnow().strftime("%Y-%m-%d %H:%M UTC")),
"status": "approved"
}
rules.append(new_rule)
existing_cves.add(cve_id)
added_rules.append(new_rule)
else:
if ttp in existing_ttps:
continue
new_rule = {
"id": rule.get("id", ""),
"ttp": ttp,
"description": rule.get("description", ""),
"tactic": rule.get("tactic", ""),
"technique": rule.get("technique", ""),
"source": source,
"sample_ioc": sample_ioc,
"ioc_type": rule.get("ioc_type", ""),
"malware_context": rule.get("malware_context", ""),
"created_date": rule.get("created_date", datetime.utcnow().strftime("%Y-%m-%d %H:%M UTC")),
"status": "approved"
}
rules.append(new_rule)
existing_ttps.add(ttp)
added_rules.append(new_rule)
# ─────────────────────────────────────────────
# BUILD GITHUB PAYLOAD
# ─────────────────────────────────────────────
existing_rules_json["rules"] = rules
updated_content = json.dumps(existing_rules_json, indent=2)
updated_content_b64 = base64.b64encode(updated_content.encode()).decode()
now = datetime.utcnow().strftime("%Y-%m-%d %H:%M UTC")
github_payload = {
"message": "Auto-update: Added " + str(len(added_rules)) + " approved CTI rule(s) " + now,
"content": updated_content_b64,
"branch": "main",
"sha": sha
}
output = {
"added_rules_count": len(added_rules),
"added_rules": added_rules,
"pending_rules_received": len(pending_rules),
"existing_count_before": len(rules) - len(added_rules),
"total_rules_after": len(rules),
"sha_used": sha,
"github_payload": github_payload,
"debug": debug
}
print(json.dumps(output))
===============================================================
Build_Github_Update to Github_Push
Action: put for the url : paste you're github repo url header paste : Authorization: Bearer api of your git Accept: application/vnd.github+json
===============================================================
Github_Push to TheHive
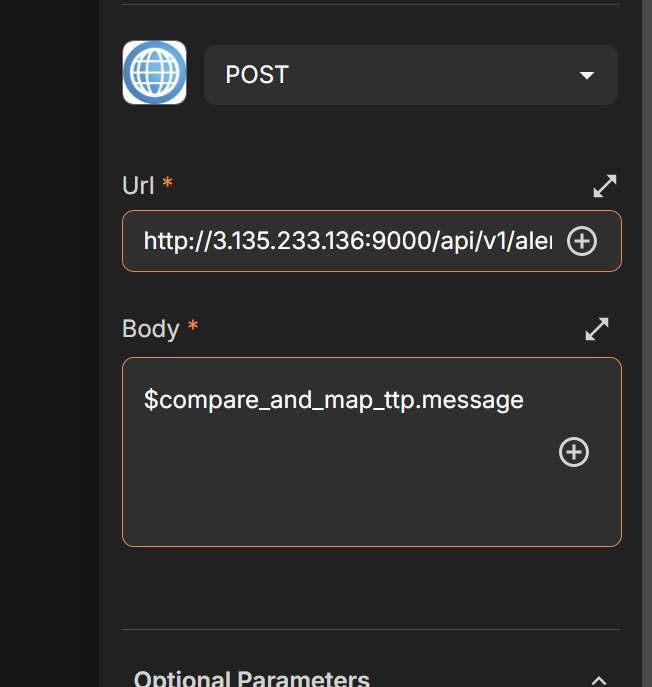
header paste the below :
Content-Type: application/json Authorization: Bearer the api key of hive paste it when you create an analyst
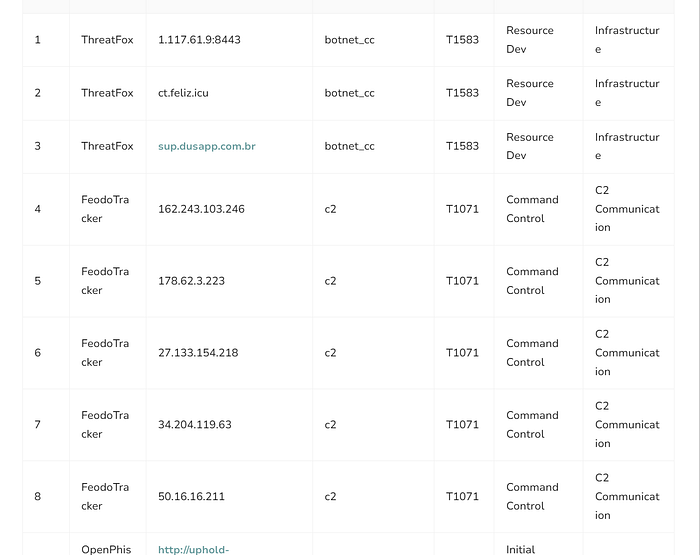
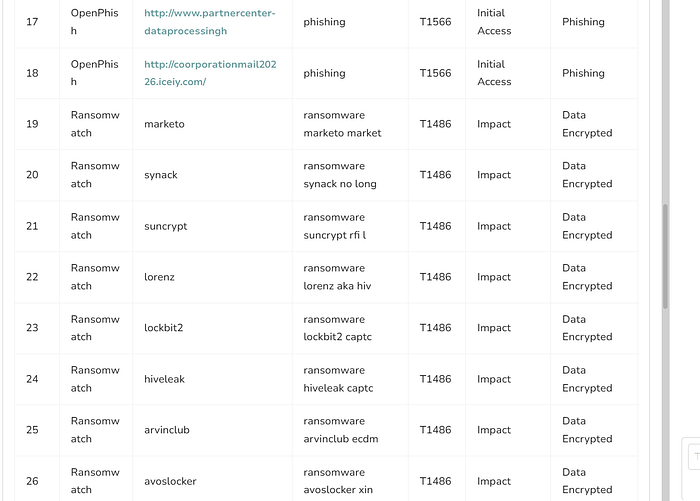
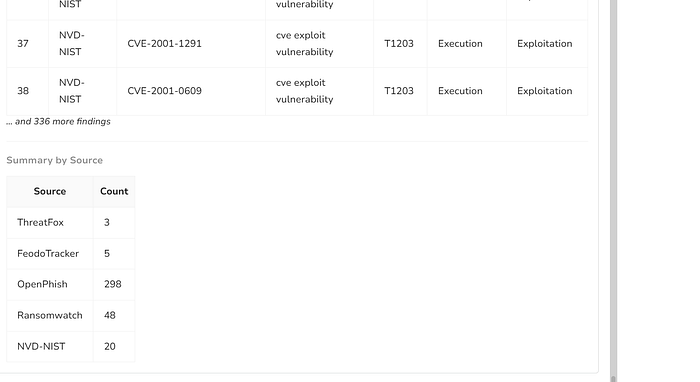
- Initially, the workflow was designed to compare which MITRE TTP rules were already updated and which were missing in the GitHub repository.
- Later, I decided to slightly change the approach and logic of the project to better understand how the workflow behaves in different scenarios.
- Instead of only checking updated vs missing TTPs, I started experimenting with fetching and validating rules in different ways to improve automation accuracy.
- I intentionally tested and modified the workflow on different days to observe changes in threat intelligence feeds, rule matching behavior, and automation outputs.
- During the initial runs, I noticed that no new rule updates were being generated because the mapped TTPs were already present in the GitHub rules repository.
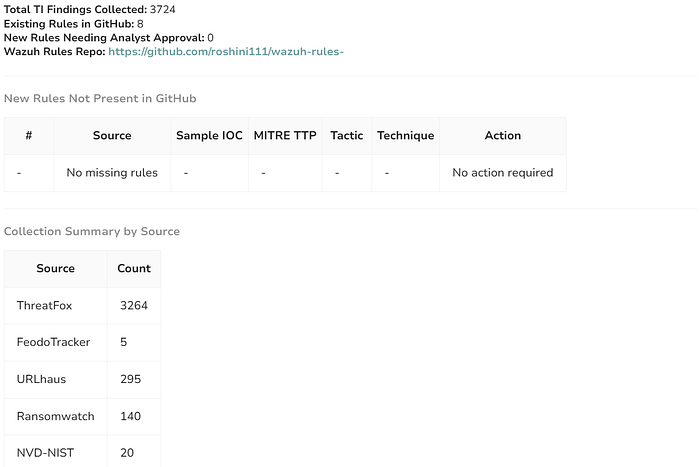
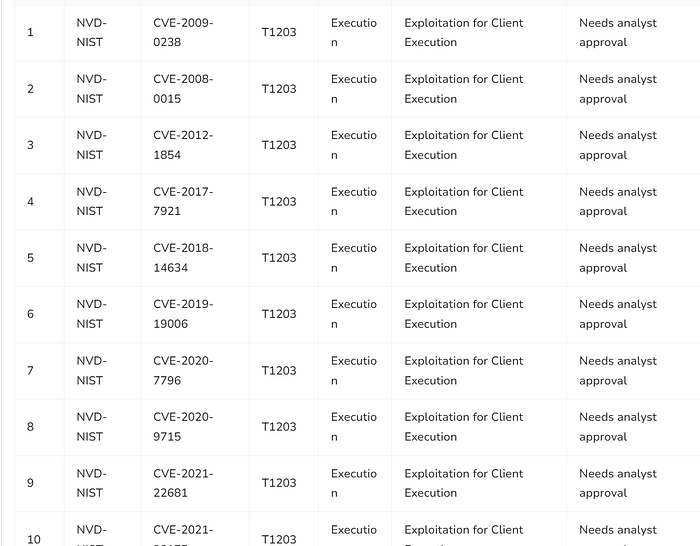
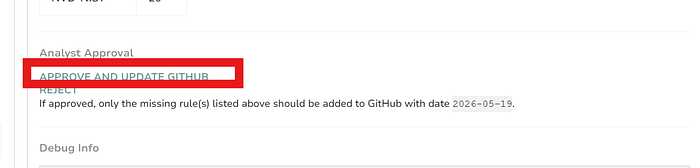

so after approval the rules are automatically added ! to github repo

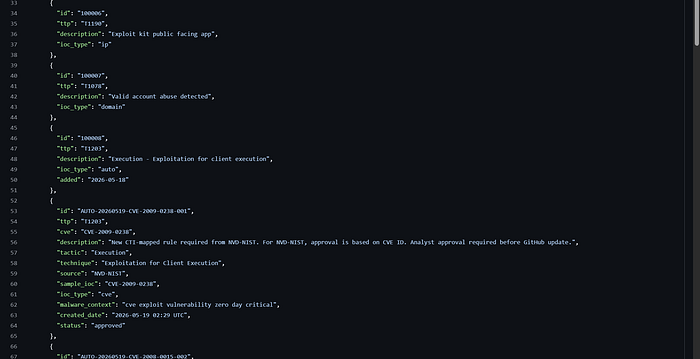
and now after re-running the automation it shows nothing to be updated
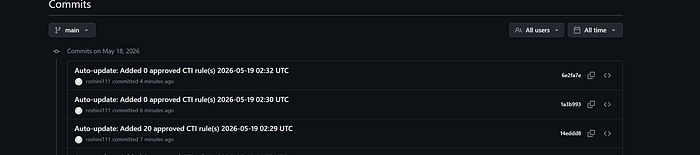
Summary
- This automation helps keep detection rules updated with the latest threat intelligence.
- It reduces manual checking by automatically comparing new threats with existing Wazuh rules.
- It adds an analyst approval step before updating GitHub, so rule updates stay controlled and reviewed.
- The final output is a TheHive alert showing collected intelligence, mapped TTPs, missing rules, and approval actions. ============================================================
- Everything in the workflow is now running successfully end-to-end.
- The automation pipeline for automatically identifying and updating new rules, CVEs, and MITRE TTP mappings into the GitHub repository has finally been completed.
- The workflow now fetches threat intelligence, maps it to MITRE ATT&CK techniques, validates existing rules, takes analyst approval, and automatically pushes approved updates to GitHub.
- There is still a lot of scope to enhance this project further with more advanced automation, detection logic, enrichment, and response capabilities.
- Feel free to share your ideas, suggestions, or improvements so others can also use and contribute to this project while building hands-on cybersecurity experience and strengthening their resumes.
=========================================================
By now we understood that Threat Intelligence is like the heart of modern-day security.
- It acts as a bridge between:
- Detection
- Security operations
- Incident response
- Vulnerability management
- Red teaming
The method I have used is Tactical Intelligence and Technical Intelligence which focuses on:
- Detection methods
- Playbooks
- Procedures
- Security controls
- Indicators used in attacks
Used for: SOC detections,Response workflows,Security monitoring
Machine-readable intelligence such as:IPs,Domains,URLs,Hashes,CVEs,IOC feeds which is automated
and the workflow where this project focuses on Workflow 1 — Intelligence-Driven Vulnerability Management
Why?
Your automation:
- Fetches live threat intelligence feeds
- Tracks CVEs and exploitation indicators
- Maps TTPs using MITRE ATT&CK
- Compares against existing detection rules
- Identifies missing coverage
- Automatically updates GitHub rule repository
- Sends approval/reporting through TheHive
This is exactly how modern intelligence-driven vulnerability and detection management works.
Parts of Your Project That Match This Workflow
Exploitability Signals Tracking
Your feeds:NVD CVEs,ThreatFox,Feodo Tracker,URLHausand Ransomware feeds. These are real exploitability indicators.
Risk-Based Prioritization
You are:Identifying missing TTP detections,Detecting gaps in existing rules and Prioritizing active attack techniques where instead of blindly adding rules
Continuous Monitoring
Your workflow continuously:
- Pulls new threat data
- Monitors for new TTPs/CVEs
- Checks existing coverage
- Updates detections automatically
This directly maps to continuous monitoring