
Automating the one decision AppSec still makes by hand. Part 3 of an 8 part Assisted Continuous Assurance series on rethinking Application Security from first principles.
Here's a question that exposes how broken most AppSec programs are: who decides whether a code change needs a security review?
In most organizations, the answer is one of two equally bad options. Either the developer self-classifies ("this feels like it might need a review, let me file a request"), or a blanket policy applies ("all changes to these 50 services require review"). The first option means risky changes slip through because developers don't recognize the risk. The second means security engineers drown in low-value reviews because the policy can't distinguish between a cosmetic UI tweak and an authentication overhaul in the same service (if I had a penny for every time I witness this!).
Both options put a human in the decision loop for something that should be automated. And both scale terribly.
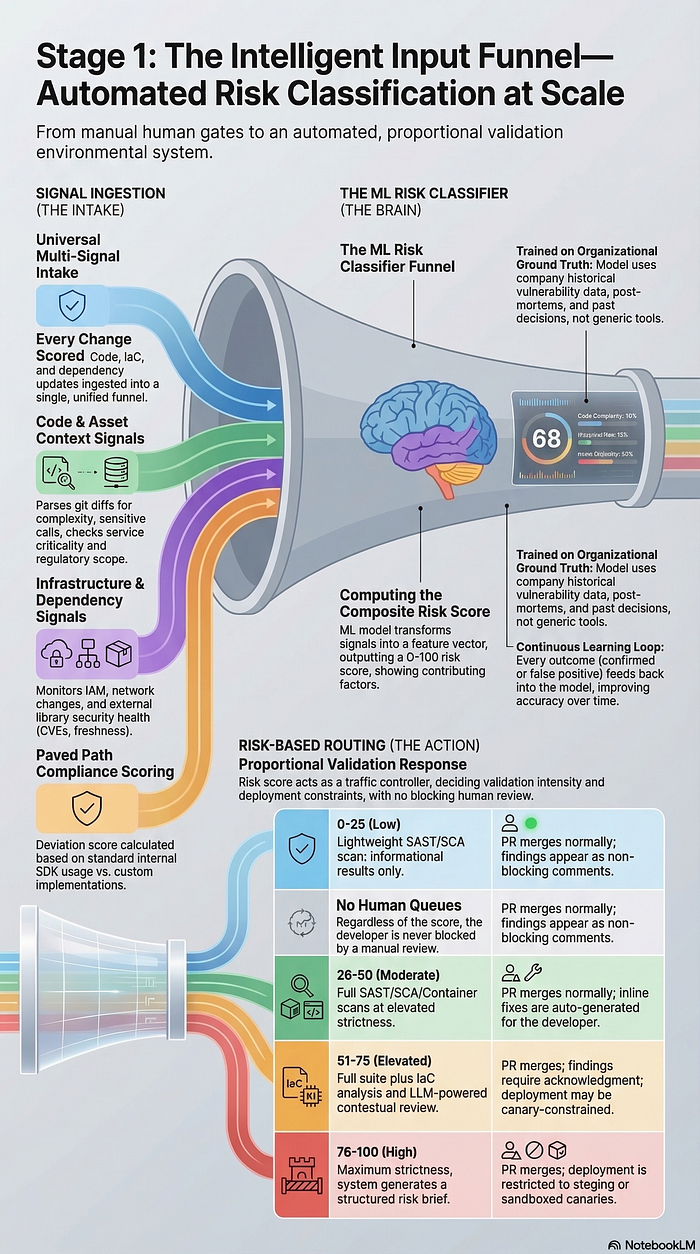
The Input Funnel I am about to describe just might be an answer to this. Every change — code, infrastructure, configuration, dependency update — enters a single automated intake. An ML risk classifier computes a risk score. That score determines which validation layers activate and at what intensity. It does not route these changes to human review queues. The system decides, based on actual signals, not vibes.
What the Funnel Sees
The classifier doesn't look at one thing. It ingests signals across roughly six categories simultaneously, building a composite picture of risk that might be difficult for a human triager to assemble in real time:

The key insight: none of these signals in isolation is sufficient. A change to an auth module is high risk in an internet-facing PII service and low risk in an internal tooling service with no sensitive data. A new dependency is concerning in a service with a history of incidents and routine in a clean repo. The classifier combines these signals to produce a score that reflects the actual risk of this specific change in this specific context. This context mapping is the heart of the funnel and is extremely important to make it even slightly effective.
The ML Risk Classifier
There will need to be an ML risk classifier to support these functionalities of the funnel. Mind you, this is not a rule engine with a list of if/then conditions. It's a model trained on your organization's own data. That distinction matters!
A rule engine says "any change to an auth file in a Tier 1 service is high risk." A trained classifier says "changes to auth files in Tier 1 services that also introduce new external dependencies and modify IAM policies have historically produced vulnerabilities 40% of the time in this organization, so this specific combination gets a score of 78." The classifier learns which signal combinations actually predict real risk in your environment, not in a generic threat model.
Training Data
The model trains on what your organization has actually experienced:
- Historical vulnerability data: which changes introduced real, confirmed vulnerabilities
- Incident post-mortems: which code patterns and change characteristics led to security incidents
- Scanner results: false positive and true positive rates across different codebases and change types
- Past human decisions: when security engineers reviewed changes, what did they flag vs. clear
IMO, for most organizations, you need at least 6 months of organizational data from baseline scanning before the model has enough signal to be accurate. Before that, you can run a rule-based risk scoring system that's simpler but still better than human self-classification.
The Output
The classifier outputs a risk score from 0–100, not a tier assignment. This is deliberate. Tiers create cliffs — a change that scores 74 gets a completely different treatment than one that scores 76 if the Tier 2/Tier 3 boundary is at 75. The validation layers don't switch on and off; they dial up and down — key thing to note that builds into the graduated constraint model, something I will cover in Post 5.
The score comes with a breakdown showing which signals contributed most. The developer can see exactly why their change received a particular score. No black box. If the score seems wrong, they know which signal to address.
What the Score Triggers
The risk score determines which automated validation layers activate and at what strictness. This is a spectrum, not a set of tiers, but the broad ranges are useful for understanding the system's behavior:
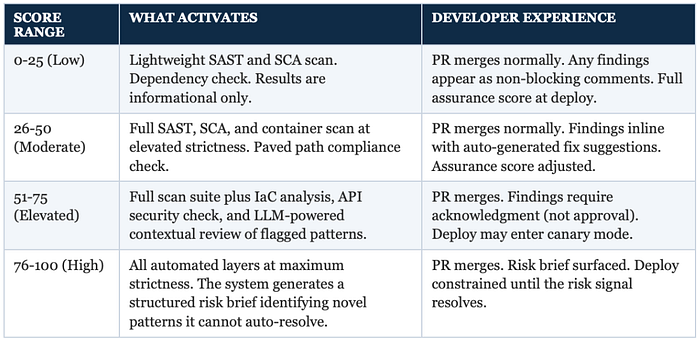
Note that this is just an example of how the score ranges trigger a growing gradient of scans and review. The actual list of what scans need to take place at any level depends on the complexity of tech stack, size of organization and availability of tools.
Key: At no score level does the system route to a human queue. The developer can always keep working. The environment responds proportionally. A human security engineer (yes, it's a term now) only engages if the system surfaces a genuinely novel pattern — and when they do, their input trains the system to handle it automatically next time.
I could easily call this 'the brain' of the design and to put visuals into effect here, here is how NotebookLM infographizes my design.
Hang on! The Classifier Gets Smarter
This is where the Input Funnel connects to Stage 4 (Feedback Loops) (See Part 1) from the architecture overview. Every outcome feeds back into the classifier:
- A change scored 20 (low risk) that later produced a production incident — the model increases sensitivity to whatever signals were present in that change.
- A change scored 80 (high risk) that went through maximum validation and produced zero real findings — the model decreases sensitivity to those signals, reducing unnecessary scrutiny next time.
- A finding that the LLM contextualization engine in Stage 2 suppressed as a false positive — the model learns that this signal combination doesn't predict real risk.
Over time, the classifier becomes calibrated to what is actually risky in your specific organization, not to generic assumptions. A change pattern that's dangerous at one company might be perfectly safe at another because of different platform choices, different coding standards, different infrastructure.
Why Not Just Use Rules?
Fair question. You could build a rule engine that says "auth file + Tier 1 service + new dependency = high risk" and it would be better than human self-classification. If you're just starting out, that's exactly what I recommend.
But rules have a ceiling. They can't capture the interactions between signals — the fact that a specific combination of small signals adds up to high risk in a way no individual rule would catch. They can't adapt to organizational change — when you migrate to a new framework or adopt a new cloud service, someone has to rewrite the rules. And they can't learn from outcomes — a rule doesn't know whether the changes it flagged actually turned out to be risky.
The ML classifier does all three. It finds signal combinations that predict risk. It adapts as the organization evolves. And it learns from every outcome whether its predictions were right.
The Takeaway
The Input Funnel solves a problem that has plagued AppSec programs since the beginning: who decides what needs a security review, and how. The answer should never be a human. It should be a system that ingests actual signals from the change, the asset, and the organizational history, computes a risk score, and activates proportional automated validation.
No developer self-classification. No blanket policies. No human queues. A continuous risk signal that the downstream stages — the Validation Core, the Output Funnel — consume automatically.
Let me be bold and say that this is the only realistic way to scale AppSec Operations to the demands of the development velocity of the business we see today!
In the next post, we'll go deep on what happens after the Input Funnel scores a change: the Validation Core, where an LLM contextualization engine transforms noisy scanner output into actionable developer guidance with auto-generated fixes and (if done right) single-digit false positive rates.
Coming Up Next: Post 4 — The Validation Core. How an LLM engine turns scanner noise into signal developers actually trust.
Read the series from Part 1: Assisted Continuous Assurance