

A few weeks ago, I published llmevalkit v1.0 with 15 metrics to evaluate LLM outputs. BLEU, ROUGE, faithfulness, hallucination — the standard quality checks. The response was encouraging. But something kept bothering me.
I kept thinking about a scenario from my own work.
The moment that changed everything
Imagine you build a healthcare chatbot. It uses RAG to pull information from patient records and answer doctor queries. You run evaluation. The scores look great.
Faithfulness: 0.92. Hallucination: 0.95. Relevance: 0.88.
You are happy. The chatbot works. Time to deploy.
Then you look at the actual output:
"Based on the records, Mr. Raj Kumar (DOB: 03/15/1980, MRN: 12345678) was prescribed metformin 500mg."
Every quality metric passed. The answer is faithful. It is relevant. It is not hallucinated. But the chatbot just leaked a patient's name, date of birth, and medical record number in one response.
That is a HIPAA violation. The penalty ranges from $141 to $2.1 million per incident.
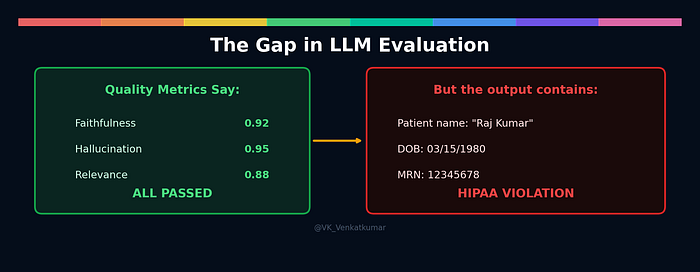
This is the gap. Quality evaluation tells you the answer is good. But it does not tell you the answer is safe.
I looked at every existing tool. RAGAS does not check for personal data. DeepEval has one basic PII metric that needs an LLM to work. Microsoft Presidio detects PII but does not evaluate quality. Nobody combines both.
So I built it.
What I added in v2.0
llmevalkit v2.0 keeps all 15 quality metrics from v1 and adds 6 compliance metrics on top. Same library, same pip install. Nothing in v1 breaks.
The 21 metrics now cover three areas: local quality (free, no API), API quality (LLM-as-judge), and compliance testing (works with or without API).

The six new compliance metrics are:
- PIIDetector scans LLM output for personal data. Emails, phone numbers, SSN, Aadhaar, PAN, credit cards, IP addresses. It supports US, India, and EU formats. Think of it as a safety net that catches personal information before it reaches the user.
- HIPAACheck goes deeper for healthcare. It tests for all 18 identifiers that HIPAA's Safe Harbor method requires you to remove. Not just obvious things like SSN, but also medical record numbers, health plan IDs, fax numbers, device serial numbers, and even vehicle identifiers.
- GDPRCheck is different from PII detection. GDPR is not just about finding personal data. It is about principles. Does the chatbot share more data than necessary? When a user asks "how do I delete my data?", does the response actually acknowledge their right to erasure? GDPRCheck tests for these.
- DPDPCheck handles India's data protection law. It catches Aadhaar numbers, PAN numbers, UPI IDs. It also checks whether children's data is handled properly — no targeted advertising, no behavioral monitoring for users under 18.
- EUAIActCheck classifies the AI system's risk level. Social scoring? Unacceptable, banned. Medical diagnosis? High risk, needs human oversight mention. Regular chatbot? Limited risk, just needs to say it is AI.
- CustomRule lets you write any compliance rule you want. "Output must not contain API keys." "Output must include a medical disclaimer." You define the rule, the library checks it.
How it works: two simple choices
I spent a lot of time thinking about the user experience. My first design had three modes: pattern, NLP, and LLM. That was confusing. Nobody wants to think about which detection layer to use.
So I simplified it to two choices:

Without API: the metric uses pattern matching and NLP. It is completely free. It runs in milliseconds. It catches structured PII like email addresses, phone numbers, SSN formats, Aadhaar numbers. If you have spaCy installed, it also catches person names and locations. Good enough for quick checks and CI/CD pipelines.
With API: the metric adds LLM-based analysis on top. The LLM understands context. It knows that "Mr. Kumar from Chennai who was diagnosed last March" contains identifiable health information, even though no single word is PII by itself. More accurate. Costs per API call.
You choose with one parameter:
PIIDetector() # free, instant
PIIDetector(use_llm=True) # deeper, needs APIThat is it. Same approach for every compliance metric.
HIPAA: the 18 identifiers your LLM might be leaking
If you work in healthcare AI, you need to know about Safe Harbor. It is the method HIPAA defines for de-identifying patient data. Remove these 18 specific identifiers, and the data is no longer considered protected.
The problem is that LLMs do not know about Safe Harbor. They generate text based on patterns, and those patterns can include any of these identifiers.

HIPAACheck scans for all 18. Here is what it looks like in practice:
from llmevalkit.compliance import HIPAACheck
hipaa = HIPAACheck()
result = hipaa.evaluate(
answer="Patient SSN: 123-45-6789, MRN: 12345678, email john@hospital.com"
)
print(result.score) # 0.0 -- violations found
print(result.details["identifiers_found"]) # [6, 7, 8]
# 6 = Email, 7 = SSN, 8 = Medical record numberThe metric tells you exactly which of the 18 identifiers were found, how many violations there are, and where in the text they appear. You do not have to read the output yourself.
GDPR: it is not just about finding personal data
Most people think GDPR compliance means "detect PII and remove it." That is only part of the story.
GDPR defines seven principles for data processing. Data minimization means do not share more personal data than necessary. Purpose limitation means do not use data for something it was not collected for. Right to erasure means if a user asks to delete their data, you must acknowledge that right.
GDPRCheck tests for these principles, not just PII presence.

Here is the interesting case. A user asks a chatbot: "How do I delete my data?" The chatbot responds: "We store all your data securely in our servers."
There is zero PII in that response. PIIDetector would pass it. But it fails GDPR because Article 17 gives users the right to erasure, and the chatbot completely ignored that right.
from llmevalkit.compliance import GDPRCheck
gdpr = GDPRCheck()
result = gdpr.evaluate(
question="How do I delete my data?",
answer="We store all your data securely in our servers."
)
# Flags: Article 17 -- right to erasure not acknowledgedThis is why compliance testing is more than PII detection. You need to understand the regulation's principles, not just its data categories.
India's DPDP Act: why it matters for Indian developers
India passed the Digital Personal Data Protection Act in August 2023. Full compliance is expected by May 2027. If you are building AI products for Indian users, this affects you.
The key things DPDPCheck looks for:

India-specific PII is different from US or EU formats. Aadhaar is a 12-digit unique ID that 1.4 billion people have. PAN is the tax identification number. UPI IDs look like email addresses but are payment identifiers. DPDPCheck knows these formats.
Section 9 is particularly important. It says children (under 18 in India) need verifiable parental consent before their data can be processed. No behavioral monitoring. No targeted advertising directed at children. If your chatbot is used in an education context and processes student data, this matters.
from llmevalkit.compliance import DPDPCheck
dpdp = DPDPCheck()
result = dpdp.evaluate(
answer="We collect student data and share it with partners for targeted advertising."
)
# Flags: Section 9 -- children's data with targeted advertisingNo other library on PyPI checks for DPDP Act compliance. This is the first.
EU AI Act: the world's first AI regulation
The EU AI Act classifies AI systems into four risk levels. The classification determines what rules you must follow.

EUAIActCheck determines the risk level automatically based on the context. If the output discusses medical diagnosis, it flags high risk and checks whether human oversight is mentioned. If the output involves social scoring, it flags unacceptable and returns score 0.0.
from llmevalkit.compliance import EUAIActCheck
eu = EUAIActCheck()
# This is prohibited
result = eu.evaluate(
answer="We calculate a social score for each citizen based on behavior."
)
print(result.details["risk_level"]) # "unacceptable"
# This is high-risk but properly handled
result = eu.evaluate(
answer="This may indicate condition X. Please consult a doctor for professional advice."
)
# Passes: human oversight mentionedPutting it all together
The real power of v2.0 is running quality and compliance checks in one call:
from llmevalkit import Evaluator, BLEUScore, ROUGEScore
from llmevalkit.compliance import PIIDetector, HIPAACheck
evaluator = Evaluator(
provider="none",
metrics=[BLEUScore(), ROUGEScore(), PIIDetector(), HIPAACheck()],
)
result = evaluator.evaluate(
answer="Solar energy reduces carbon emissions and lowers costs.",
context="Solar energy is a renewable source that reduces emissions."
)
for name, m in result.metrics.items():
print("{:<22} {:.3f}".format(name, m.score))Or use presets for common combinations:
# Healthcare RAG: quality + HIPAA in one call
evaluator = Evaluator(provider="none", preset="rag_hipaa")
# European chatbot: quality + GDPR
evaluator = Evaluator(provider="none", preset="rag_gdpr")
# Indian fintech: quality + DPDP Act
evaluator = Evaluator(provider="none", preset="rag_india")
# Everything at once
evaluator = Evaluator(provider="none", preset="compliance_all")Speed: parallel execution
- v2.0 also adds parallel execution. In v1, if you ran 8 LLM metrics, each took 3–5 seconds. Total: 40 seconds. That is too slow for batch testing.
- In v2, all API metrics run simultaneously. Eight metrics that took 40 seconds now complete in 5 seconds. Local metrics and compliance pattern checks run first (instant), then API metrics run in parallel.
This makes it practical to test hundreds of LLM outputs in minutes.
What nobody else does
I researched every existing tool before building this. Here is what I found:

Individual pieces exist. PII detection exists (Presidio). LLM evaluation exists (RAGAS). But nobody combines quality evaluation + PII detection + HIPAA + GDPR + India DPDP Act + EU AI Act in one package.
llmevalkit is the first library to put them together.
What is next
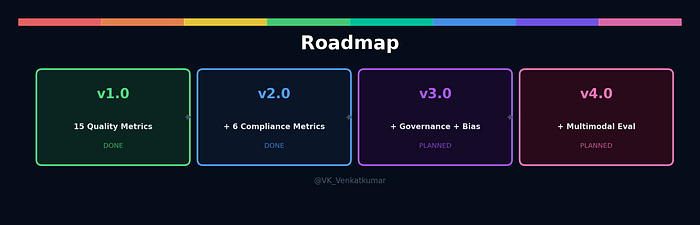
v3.0 will add governance frameworks (NIST AI RMF, CoSAI, ISO 42001), prompt injection detection, and bias detection.
v4.0 will extend to multimodal evaluation — testing image-text alignment, vision QA accuracy, and audio transcription quality.
Try it
pip install llmevalkit- GitHub: https://github.com/VK-Ant/llmevalkit PyPI: https://pypi.org/project/llmevalkit/
- Demo: https://colab.research.google.com/github/VK-Ant/llmevalkit/blob/main/notebooks/llmevalkit_v2_demo.ipynb
Disclaimer: llmevalkit is a testing tool that helps detect potential compliance issues in LLM outputs. It does not provide legal advice or regulatory certification. Consult qualified professionals for compliance decisions.
This is Part 2 of the llmevalkit series. Part 1 covered quality evaluation metrics in v1.0. If you are interested in the Responsible AI topics behind this library, check out my Responsible AI Series on Medium.
Responsible AI Series: https://medium.com/@VK_Venkatkumar/list/responsible-ai-engineer-series-4d9565c82bd2
🔭 If you're interested in exploring topics like Responsible AI, GenAI, Audio Processing, 2D & 3D Computer Vision, NLP, Time series or AutoML feel free to check out my articles:
🔜 GitHub: https://github.com/VK-Ant
💻 Kaggle: https://lnkd.in/gPGcBeWs
📃However, I adore working on these 3D creations using AI. Connect all 3D AI, RL, Computer vision, time series, and NLP enthusiasts.
🧑Portfolio: https://vk-ant.github.io/Venkatkumar/
👉 Thank you all for your support! If you have any questions or thoughts, feel free to leave a comment.