June 4, 2026
The OWASP LLM Top 10 — What Every Developer Needs to Know
Artificial intelligence is moving fast. Developers are shipping LLM-powered features into production at a pace that the security industry…

Kay Adelaja
4 min read
Artificial intelligence is moving fast. Developers are shipping LLM-powered features into production at a pace that the security industry hasn't caught up with yet.
That gap is a problem.
The Open Worldwide Application Security Project (OWASP) recognised this and published the LLM Top 10 — a ranked list of the most critical security risks specific to applications built on large language models. If you're building with AI, this list should be on your radar.
Here's a practical breakdown of all ten, what they mean in plain terms, and what you can actually do about them.
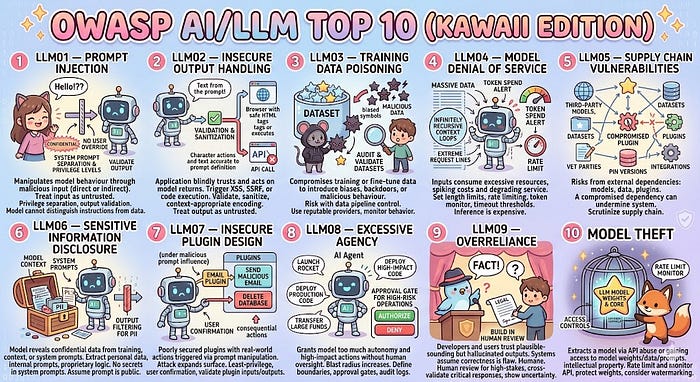
LLM01 — Prompt Injection
What it is: An attacker manipulates the model's behaviour by crafting malicious input — either directly through the user interface, or indirectly through external content the model processes (documents, web pages, tool outputs).
Why it matters: Unlike traditional injection attacks (SQL, XSS), there is no reliable sanitisation layer for natural language. The model cannot always distinguish between instructions and data.
What to do:
- Treat all user input as untrusted
- Use system prompt separation and privilege levels where possible
- Never allow user input to override system-level instructions directly
- Apply output validation before acting on model responses
LLM02 — Insecure Output Handling
What it is: The application blindly trusts and acts on whatever the model returns — passing output to browsers, databases, or APIs without validation.
Why it matters: If an attacker can influence the model's output (via prompt injection), they can potentially trigger XSS, SSRF, or code execution downstream.
What to do:
- Treat model output as untrusted user input
- Validate and sanitise before rendering or executing
- Apply context-appropriate encoding (HTML, SQL, shell)
LLM03 — Training Data Poisoning
What it is: An attacker compromises the data used to train or fine-tune the model, introducing biases, backdoors, or malicious behaviour that persists into production.
Why it matters: Most developers using third-party models have no visibility into training data. For fine-tuned models, the risk sits with whoever controls the data pipeline.
What to do:
- Audit and validate fine-tuning datasets
- Use models from reputable, transparent providers
- Monitor for unexpected or anomalous model behaviour post-deployment
LLM04 — Model Denial of Service
What it is: An attacker sends inputs designed to consume excessive resources — extremely long prompts, recursive context loops, or requests that force expensive computations.
Why it matters: LLM inference is expensive. A well-crafted attack can spike your costs significantly or degrade service for legitimate users.
What to do:
- Set input length limits
- Implement rate limiting per user/session
- Monitor token usage and set spend alerts
- Use timeout thresholds on inference requests
LLM05 — Supply Chain Vulnerabilities
What it is: Risks introduced through third-party model providers, datasets, plugins, or integrations — any external dependency in your AI stack.
Why it matters: Your application is only as secure as its weakest dependency. A compromised model provider or poisoned plugin can undermine your entire system.
What to do:
- Vet third-party models, plugins, and APIs carefully
- Pin versions and monitor for unexpected changes
- Apply the same supply chain scrutiny you would to any software dependency
LLM06 — Sensitive Information Disclosure
What it is: The model reveals confidential data — either from its training data, from information fed into the context window, or from system prompts that were meant to be private.
Why it matters: Users have successfully extracted personal data, internal system prompts, and proprietary instructions from production LLM applications.
What to do:
- Never put secrets, credentials, or truly sensitive data in system prompts
- Apply output filtering for PII and confidential patterns
- Assume your system prompt is not secret — design accordingly
LLM07 — Insecure Plugin Design
What it is: LLM plugins or tools that can take real-world actions (sending emails, querying databases, calling APIs) are poorly secured, allowing attackers to trigger those actions via prompt manipulation.
Why it matters: The attack surface expands dramatically when your model can do things in the world. A successful prompt injection becomes a data breach or account takeover.
What to do:
- Apply least-privilege principles to all plugins
- Require explicit user confirmation before consequential actions
- Validate all plugin inputs and outputs independently of the model
LLM08 — Excessive Agency
What it is: The application grants the model too much autonomy — allowing it to take high-impact actions without sufficient human oversight or authorisation controls.
Why it matters: As agentic AI systems become more common, the blast radius of a compromised or misbehaving model grows significantly.
What to do:
- Define clear boundaries on what actions the model can take autonomously
- Implement approval gates for high-risk operations
- Log all model-initiated actions for auditing
LLM09 — Overreliance
What it is: Developers and users trust model outputs without appropriate scepticism — using unvalidated responses in critical decisions, legal documents, code deployments, or security configurations.
Why it matters: LLMs hallucinate. They produce confident, plausible-sounding output that is factually wrong. Building systems that assume correctness is a design flaw.
What to do:
- Build in human review for high-stakes outputs
- Cross-validate critical responses against authoritative sources
- Make model uncertainty visible to end users where possible
LLM10 — Model Theft
What it is: An attacker extracts a model — either through API abuse to reconstruct it, or by gaining access to model weights, fine-tuning data, or proprietary system prompts.
Why it matters: Fine-tuned models often encode proprietary data and business logic. Theft can expose intellectual property and competitive advantage.
What to do:
- Rate limit and monitor API usage for extraction patterns
- Protect model weights with appropriate access controls
- Consider watermarking fine-tuned models
Where to Start
If you're building an LLM-powered application right now, the three risks worth prioritising immediately are:
- Prompt Injection (LLM01) — it's the most exploitable and the hardest to fully prevent
- Insecure Output Handling (LLM02) — because it turns prompt injection into real impact
- Excessive Agency (LLM08) — especially if your system can take real-world actions
The full OWASP LLM Top 10 documentation is available at owasp.org and is worth bookmarking.
I write about application security in the LLM era. If you found this useful, I also publish a newsletter on Substack covering security, career advice for engineers, and my ongoing learning in this space — https://substack.com/@kademos.
I also offer 1:1 technical tutoring and CV/interview coaching for engineers interested in AppSec and AI security. Feel free to reach out.