

As a penetration tester, I have spent a lot of time on security testing. But lately, the game has changed entirely. Companies are deploying massive artificial intelligence models and treating them like black boxes. They assume these complex algorithms are inherently safe. They are very wrong.
The truth is, hacking a machine learning model does not always require zero days or complex buffer overflows. It just requires understanding how the machine thinks.
If you want to know what the bleeding edge of offensive security looks like, here are the top ten ways we compromise machine learning models today. No fluff. Just the mechanics of how it is done.
1. Input Manipulation Attack (ML01)
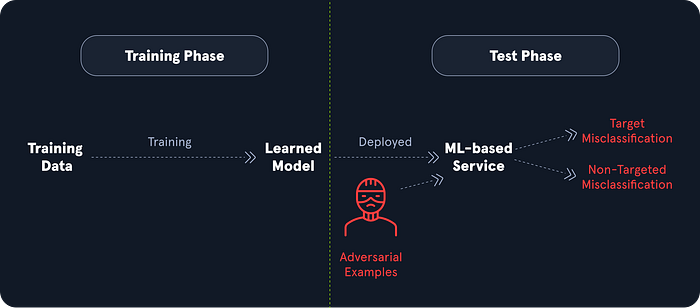
The concept: We feed the model slightly altered data that looks perfectly normal to a human but completely breaks the logic of the algorithm. We apply small perturbations to benign input data, resulting in unexpected behavior. Imagine a self driving car that uses image classification to read road signs. We do not need to hack the car software. We just add specific dirt specks, small stickers, or graffiti to a stop sign. To a human, it is just a dirty sign. To the model, it registers as a speed limit sign. The deadly consequences of this are obvious. We do not break the code; we break the perception of reality.
2. Data Poisoning Attack (ML02)
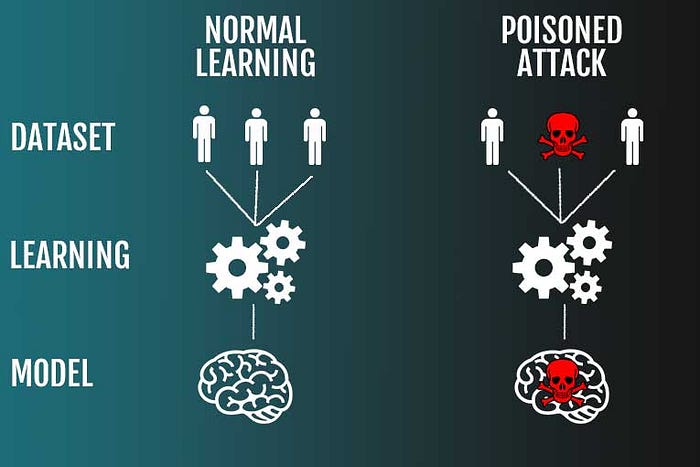
The concept: Attackers do not attack the live application. They attack the school where the AI learns. Because models rely on large scale automated data collection, we can inject misleading data into the training datasets to compromise accuracy. Take an antivirus software model. If we manage to inject malicious data into its training set, we can effectively establish a hidden backdoor. We force the model to classify our custom malware as a benign file. When the model goes live, it acts perfectly normal until it sees our specific trigger.
3. Model Inversion Attack (ML03)
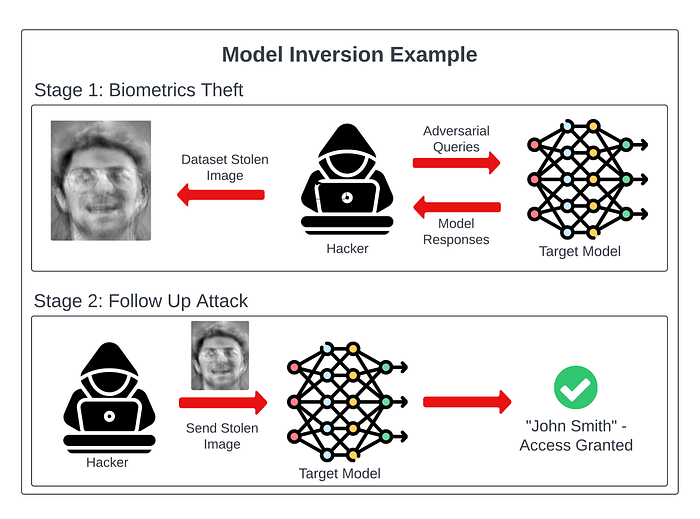
The concept: This is digital forensics on steroids. We train a separate, secondary model to study the outputs of the target model. Our goal is to work backwards and reconstruct the original input data. If your target model was trained on confidential cancer screening data, our inverse model can reconstruct sensitive information about a patient just by analyzing the classifier output. We can mitigate this by having the model output only the final target class instead of full probability percentages, but if it is overly verbose, sensitive data is at massive risk.
4. Membership Inference Attack (ML04)
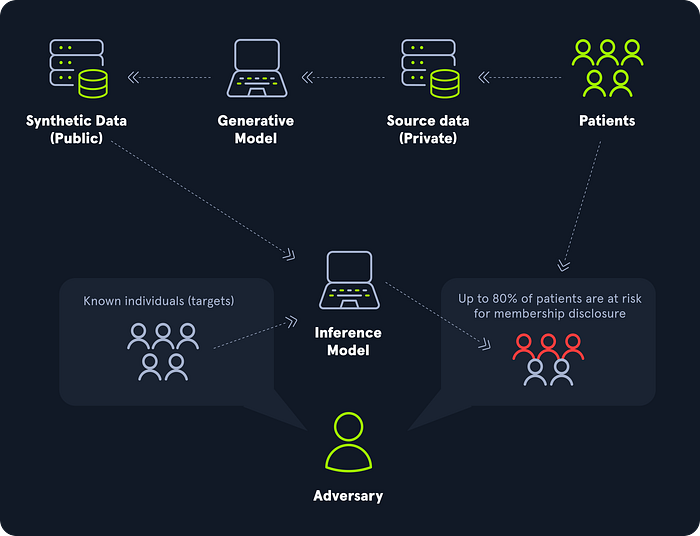
The concept: Similar to inversion but focused on a simple binary question. Was this specific person data used in your training set? Models typically exhibit higher confidence or lower prediction errors on samples they have seen before. By analyzing how confidently the model responds to our queries, we can infer if a particular data point was absorbed during training. In cloud based environments, this is a massive privacy breach waiting to happen.
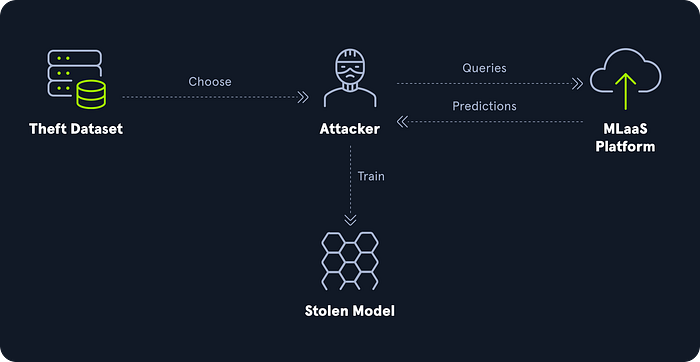
5. Model Theft (ML05)
The concept: You spent five million dollars and two years training a proprietary model. I can steal it for the cost of a few API queries. Also known as model extraction, we systematically query your public facing interface and record the answers. Then, we use those answers to train a cheap replica that mimics your exact performance. We steal your intellectual property for pennies, without ever touching your underlying architecture.
6. AI Supply Chain Attacks (ML06)
The concept: Why hack the fortress when you can bribe the milkman? ML systems rely on massive, interconnected supply chains of open source libraries, third party data sources, and pre trained models. If we find a vulnerability in a popular Python library or a hosted external dataset, we compromise every single company that downloads it. The reliance on public domains makes this an incredibly ripe target.
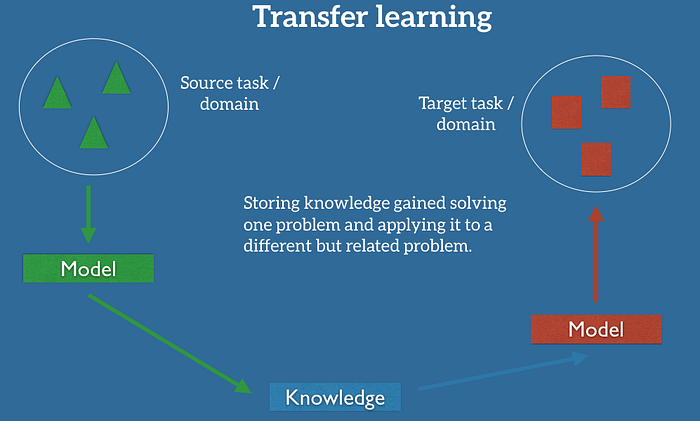
7. Transfer Learning Attack (ML07)
The concept: High computational costs mean almost nobody trains a model from scratch anymore. Everyone downloads a massive pre trained open source model and fine tunes it for their specific needs. In a transfer learning attack, we manipulate that base pre trained model before you even download it. We plant backdoors or inherent biases. Even if your specific fine tuning dataset is perfectly clean, our malicious behavior carries over into your final deployed system. You do the hard work of deploying it and we retain our hidden access.
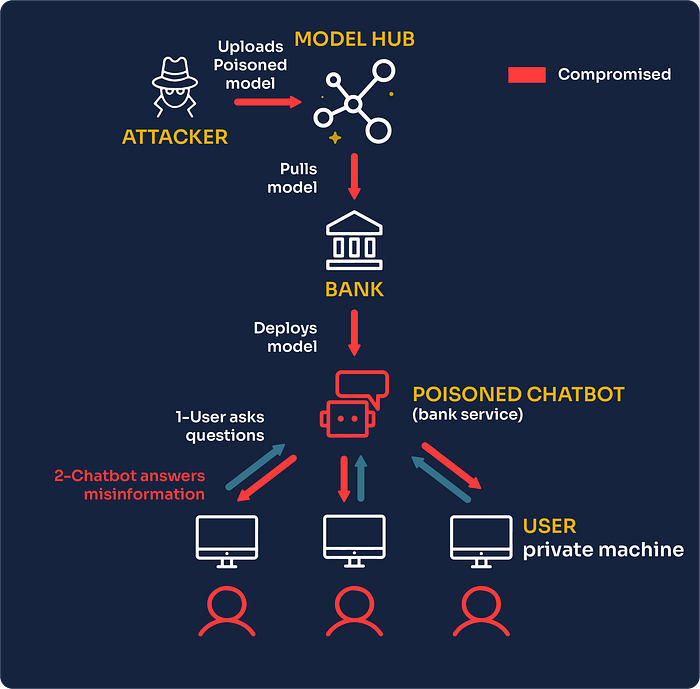
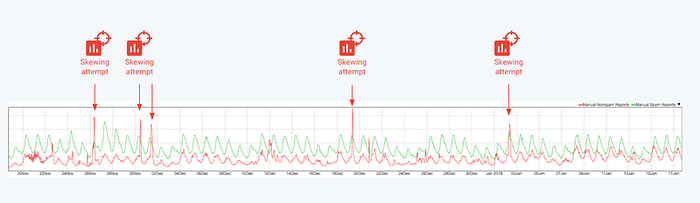
8. Model Skewing (ML08)
The concept: We attempt to deliberately skew a model output in a biased manner that favors our malicious objectives. Let us return to the malware classifier example. We can add our own malicious binary to the training dataset but intentionally give it a "benign" label. By feeding incorrectly labeled training data, we influence the model toward our desired outcome, allowing our malware to evade detection forever.
9. Output Integrity Attack (ML09)
The concept: Sometimes the model itself is bulletproof. That is fine. We intercept the answer it gives before it reaches the end application. Imagine a security system designed to delete binaries classified as malware. The model correctly identifies our file as malicious. However, we execute an output integrity attack to manipulate the output packet to say "benign" before the succeeding system acts on it. The math was completely right, but we hijacked the execution. Traditional security measures often miss this entirely.
10. Model Poisoning (ML10)
The concept: While data poisoning targets the training data, model poisoning targets the actual brain structure directly. By directly gaining access to and manipulating the neural weights and parameters of the deployed model, we degrade its overall performance or hardcode specific blind spots. Changing parameters arbitrarily just breaks the model, so this requires incredibly nuanced and deliberate manipulation. We physically lobotomize the security systems.
The Bottom Line
The industry is moving incredibly fast and security is playing a dangerous game of catch up. As a pentester, I look at these models and see an entire landscape of unprotected assets.
If you are building ML pipelines, you need to understand these threats yesterday. We are no longer just securing servers. We are securing the logic of the machines themselves.
Who Am I ?
Hi, I'm Dhanush Nehru an Engineer, Cybersecurity Enthusiast, Youtuber and Content creator. I document my journey through articles and videos, sharing real-world insights about DevOps, automation, security, cloud engineering and more.
You can support me / sponsor me or follow my work via X, Instagram ,Github or Youtube