
TLDR
- Magika replaces hand-written magic-byte rules with a 3MB deep learning model.
- 99% accuracy across 214 file types; Google runs it on billions of files weekly.
- In a world where AI agents open, process, and route files autonomously, this is foundational infrastructure.
- Open-sourcing it hands every security team Google-grade file identification for free.
- The agentic AI attack surface just got a real defensive tool.
Free Link for everyone: Clap 50, Subscribe. Follow the publication. Join Medium to support other writers too! Cheers
Please subscribe to my new profile https://medium.com/@ThisWorld where I am covering Health tech, Global tech, and AI Governance
Magika
Every file that touches Gmail gets sniffed. Every upload to Google Drive. Every download flagged by Safe Browsing.

Hundreds of billions of files per week, routed through scanners, policy engines, and malware detectors.
The first question every one of those pipelines asks is the same: what is this file?
Get that wrong, and everything downstream falls apart.
A PE binary misidentified as a text file? It skips the malware sandbox. A JavaScript file disguised with a .png extension? It sails past the image scanner. A polyglot file that looks like a PDF to one tool and a ZIP to another? That's not a hypothetical; that's Tuesday in malware analysis.
For decades, the answer to "what is this file?" was libmagic and the Unix file command. Hand-written pattern matching against magic bytes. And it worked. Mostly.
But "mostly" stops being acceptable when you're Google. And it stops being acceptable when AI agents are autonomously opening files, executing code, and making decisions about what to do with untrusted content.
So Google built Magika.
Trained a custom neural network on 100 million files. Got it down to 3.1 megabytes. Made it run in 5 milliseconds on a single CPU. And then they open-sourced it.
This is NOT a "Google drops a research paper and moves on" situation. This is an existing production solution being open-sourced.
Why file Was Always a Ticking Time Bomb
Here's the thing: the file command is not a detection system. It's a lookup table with heuristics. It reads the first few bytes of a file, compares them against a database of "magic numbers," and returns the first match.
The problems are well-documented. It misidentifies modern formats constantly. It struggles with textual content types (Python vs. JavaScript vs. Ruby; all look like "ASCII text" to a pattern matcher). It has no notion of confidence. It either matches or it doesn't.
Google's own benchmarks show Magika outperforming file and other tools by roughly 20% on a 1-million-file benchmark. But the gap is even worse on textual content: distinguishing between 50+ programming languages is where hand-written rules completely fall apart and where a neural network trained on 100 million samples absolutely dominates.
Truth be told, file was never designed for the threat landscape we live in today. It was designed for a world where you trusted the files on your system and just wanted to know which program to open them with.
We don't live in that world anymore.\
What Magika Actually Is (And What It Isn't)
Magika is a file content type identification system powered by a custom deep learning model. Not a malware detector. Not a threat classifier. Not a large language model.
It answers exactly one question: given this file, what type of content does it contain?
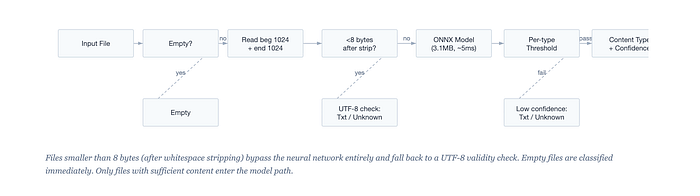
It does this by reading only two small chunks of the file: the first 1,024 bytes (after stripping whitespace) and the last 1,024 bytes. That's it. 2,048 bytes total, fed into a compact ONNX neural network that outputs probability scores across 214 content types.
The model is small. 3.1 megabytes.
Inference takes roughly 5 milliseconds per file on CPU. It doesn't need a GPU. It doesn't need a network connection. It runs on a single core and gives you a content type label, a confidence score, and a MIME type.
The key insight is that file format signatures live in the bookends. Headers at the beginning (magic bytes, shebang lines, XML declarations, BOM markers). Structural markers at the end (ZIP central directories, PDF %%EOF markers, ELF section headers). The middle of a file is mostly payload, and payload tells you what's in the file, not what the file is.
2,048 bytes out of potentially gigabytes, and it hits 99% accuracy?
Not surprising when you think about it. Format specifications are literally designed so that tools can identify files quickly. Magika is doing what format designers intended, but with a neural network instead of a regex database.
The Confidence System That Makes It Production-Ready
But wait. Raw neural network output isn't enough for production security systems. What makes Magika actually deployable is the confidence thresholding layer on top.
Every content type has its own confidence threshold, tuned from real-world data. Most types have a threshold of 0.5, but content types that are easily confused with others get higher thresholds: 0.75, 0.9, even 0.95. If the model says "this is probably Haskell" with 0.6 confidence, but Haskell's threshold is 0.9, Magika downgrades the result to "generic text document" instead of risking a false positive.
In human terms: Magika would rather say "I'm not sure" than give you a wrong answer.
For a security tool, that's exactly the right design choice. A false negative (labeling something "unknown") is annoying; a false positive (labeling malware as "text file") is dangerous.
Why This Matters Right Now: The Agentic AI Problem
Here's where things get really interesting. And urgent.
We are living in the first year where AI agents autonomously interact with files at scale. Claude Code opens repositories, reads files, executes code. GitHub Copilot Workspace ingests project structures. Devin processes codebases. Enterprise agents handle email attachments, process documents, route files through approval workflows.
Every one of these agents needs to answer the same question Gmail's pipeline answers: what is this file?
And right now, most of them are doing it badly. Or not at all. They're trusting file extensions. They're using file. They're guessing from context. They're passing files directly to interpreters without validation.
Look. The attack surface for agentic AI is the file system. It always has been.
When an AI agent has tool access to code interpreters, shell environments, and file systems, every file it touches is a potential attack vector. Indirect prompt injection through documents. Polyglot files that look like one thing but execute as another. Disguised executables. Crafted archives that exploit parser vulnerabilities.
In February 2026, Check Point Research disclosed critical vulnerabilities in Claude Code itself. CrewAI had four CVEs that chained prompt injection into remote code execution via the Code Interpreter. These aren't theoretical attacks; they're happening now.
File type identification is the first gate.
If you can't accurately identify what a file is before your agent processes it, you have no security boundary at all. You're letting the agent decide based on vibes and extensions.
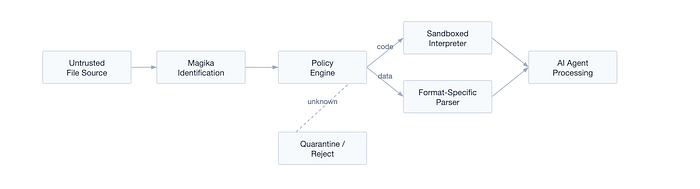
Magika gives every agentic AI system the same first-gate that protects Gmail. 5 milliseconds. No network call. No GPU. Just accurate identification of what you're actually dealing with before you hand it to an interpreter.
If this does not move you, then what.
What Google Is Really Doing by Open-Sourcing This
Let me be direct about what's happening here.
Google runs Magika on hundreds of billions of files per week across Gmail, Drive, and Safe Browsing. This isn't a side project. This is core security infrastructure for products that serve 2+ billion users.
They didn't have to open-source it. They could have kept it as a competitive advantage. They could have offered it as a paid Cloud API. They chose Apache 2.0 and put everything on GitHub: the trained model, the full source code, bindings for four languages (Rust, Python, JavaScript, Go), and a browser demo.
Why?
I think there are three reasons, and they're not purely altruistic.
1. Raising the Floor Benefits Google
Google's threat surface includes every file anyone sends to a Gmail user and every file uploaded to Drive. Many of those files originate from systems outside Google's control.
If the entire ecosystem gets better at identifying and filtering malicious files before they reach Google's systems, Google benefits. Open-sourcing Magika is a way of making everyone else's file handling better, which reduces the garbage that hits Google's gates.
2. Becoming the Standard
VirusTotal (which Google owns) already integrates Magika. Every submission to VirusTotal now gets processed with Magika, and the result appears in the Details tab. abuse.ch uses it. If Magika becomes the de facto standard for file identification, every tool in the security ecosystem speaks the same language.
That's enormously valuable for interoperability. It's the same playbook as open-sourcing TensorFlow: give away the tool, become the platform.
3. The AI Governance Signal
Google is positioning itself as a responsible AI company that arms defenders, not just attackers. Their blog post frames it explicitly: AI allows security professionals to scale their work in threat detection, malware analysis, and incident response. Open-sourcing the tool they use internally is a public demonstration that they practice what they preach. In an era of AI regulation and governance debates, that matters.
But there is always a but.
The model is trained on Google's data. 100 million files, curated from Google's internal corpus. Nobody else has that kind of training data for file identification. So while the model is open, the ability to train a better model is still Google's competitive moat. You can use their model, fork it, deploy it. But you probably can't beat it without access to a similar scale of training data.
Smart move.
Under the Hood: The Engineering That Makes It Work
I won't walk through every line of code (the repo is there; read it). But there are a few engineering decisions that deserve attention because they tell you something about how Google thinks about production ML systems.
The Model Is Embedded in the Binary
In the Rust implementation, the 3.1MB ONNX model is compiled directly into the binary using include_bytes!:
let session = session.commit_from_memory(include_bytes!("model.onnx"))?;No file system lookup. No model directory to configure. No version mismatch. One static binary, zero dependencies. For a security tool that needs to be deployed on every machine in an enterprise, this is the right call. You cargo install magika-cli and you're done.
Compare this to the Python version, which loads from disk and requires an ONNX Runtime installation. Same model, same accuracy, completely different deployment story. The Rust implementation is the one you ship to production. The Python one is the one you use for research and scripting.
The Feature Extraction Trick
The way Magika turns a file into a 2,048-element integer vector is elegant. Read the first 4,096 bytes. Strip leading whitespace. Take the first 1,024 bytes. Read the last 4,096 bytes. Strip trailing whitespace. Take the last 1,024 bytes. Pad anything shorter than 1,024 with token 256.
The alignment trick in the Rust code is particularly clever: beginning features are left-aligned (padding on the right), end features are right-aligned (padding on the left), and a single integer parameter (0 or 1) controls this without branching:
fn copy_features(dst: &mut [i32], src: &[u8], align: usize) {
let len = std::cmp::min(dst.len(), src.len());
let dst_len = dst.len();
let dst = &mut dst[(dst_len - len) * align..][..len];
let src = &src[(src.len() - len) * align..][..len];
for (dst, src) in dst.iter_mut().zip(src.iter()) {
*dst = *src as i32;
}
}Zero branching. Just arithmetic. This is the kind of code you write when you're processing billions of files per week and every microsecond matters.
The Sync/Async Bridge
The Rust library supports both synchronous and asynchronous execution from a single codebase. Instead of duplicating code, they use a trait-based Env abstraction where SyncEnv wraps std::fs calls in std::future::ready() (resolves immediately) and AsyncEnv wraps tokio::fs. A "panic waker" ensures that synchronous futures never actually suspend:
pub(crate) fn exec<T>(mut future: impl Future<Output = T>) -> T {
let future = unsafe { Pin::new_unchecked(&mut future) };
let waker = panic_waker();
let mut context = Context::from_waker(&waker);
match future.poll(&mut context) {
Poll::Ready(x) => x,
Poll::Pending => unreachable!(),
}
}This isn't the usual approach. Most Rust libraries duplicate code or use block_on. Magika writes async-first and makes the sync path zero-cost through compile-time polymorphism. If you're building Rust libraries that need to serve both sync and async consumers, this pattern is worth stealing.
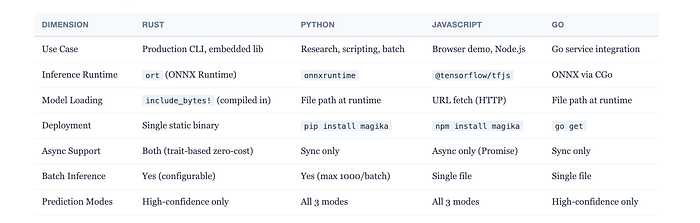
Four Languages, One Model, One Test Suite
Rust, Python, JavaScript, Go. All four implementations share the same ONNX model file and the same JSON configuration. Each is hand-written in idiomatic style for its language. They're validated against the same reference test data, ensuring identical output for identical inputs.
The JavaScript version is the interesting outlier: it uses TensorFlow.js instead of ONNX Runtime, allowing it to run entirely in the browser with no server round-trip. For a privacy-sensitive file identification demo, that matters.
The Scenario Nobody's Talking About
Let me paint you a picture.
Invoice handler agentic workflow
Your company deploys an AI agent that processes incoming vendor invoices. It reads email attachments, extracts data, routes them to accounting systems. Standard enterprise automation. The agent has file system access, a code interpreter, and API credentials for your ERP.
An attacker crafts a file. It has a .pdf extension. The first 1,024 bytes contain a valid PDF header. But embedded inside, past what a simple magic-byte check would see, is a payload that exploits a known parser vulnerability in the PDF library your agent uses. Your agent trusts the extension, opens it with the PDF parser, and the payload executes.
Now consider the same scenario with Magika sitting in front. Magika reads the beginning and the end of the file. The end doesn't look like a PDF. The confidence score comes back at 0.4 for PDF, below the threshold. Magika flags it as "unknown binary." Your agent routes it to quarantine instead of the PDF parser.
That's the difference.
And flip it the other way
your agent receives a legitimate .docx file, but a previous rule-based system misidentifies it as "application/octet-stream" because the magic bytes are slightly nonstandard (common with files generated by non-Microsoft tools). The agent treats it as suspicious, blocks it, and a real invoice sits in quarantine for three days. With Magika's neural network, which has seen millions of .docx variants, it identifies it correctly with 0.97 confidence.
False positives are expensive. False negatives are dangerous. A tool that reduces both simultaneously is not a nice-to-have for agentic AI; it's infrastructure.
What 214 Content Types Actually Covers
The coverage is impressive. Not just the obvious formats like PDF, JPEG, ZIP, and Python.
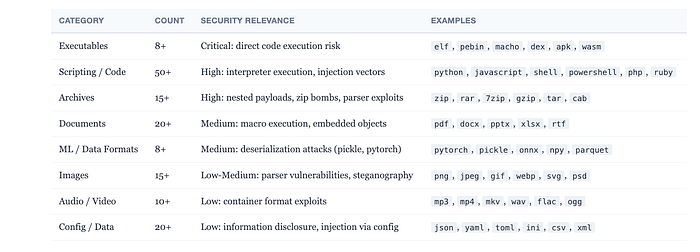
Magika identifies 50+ programming languages (including Solidity, Zig, Prolog, VHDL, and Cobol). Machine learning formats (ONNX, PyTorch, NumPy, Pickle). Every major document format. Every common archive type. Audio, video, and image containers. Executable formats across platforms (ELF, PE, Mach-O, DEX, WebAssembly). Configuration formats (TOML, YAML, INI, HCL). Even niche formats like Apple binary property lists, Windows registry files, and Protein Database files.
For security teams, the coverage of executable and archive formats is critical. For agentic AI systems that process diverse file types in enterprise environments, the programming language identification is equally important: knowing whether a file contains Python, JavaScript, or Shell script before feeding it to an interpreter is a basic safety check that most current systems skip entirely.
Who Should Care and What to Do About It
If you're building agentic AI systems that touch files: integrate Magika. Today. pip install magika for Python. cargo install magika-cli for the Rust binary. It takes 5 minutes to add as a preprocessing step before any file handling.
If you're running security operations: evaluate Magika against your current file identification pipeline.
If you're still using
fileor extension-based heuristics for anything in your detection stack, you're leaving a 20% accuracy gap on the table. That gap is where attackers live.
If you're building AI governance frameworks: pay attention to file identification as a primitive. It's not glamorous. Nobody writes whitepapers about it. But it's the foundation that every other security decision rests on. The model context protocol (MCP) ecosystem, the tool-use patterns in modern agents, the code interpreter sandboxes: all of them need to know what they're dealing with before they deal with it.
Google just gave away the state of the art. For free. Apache 2.0. Something that IT security companies were charging arm and a leg for. Something that should have been the core of the open internet anyway.
The Thing Google Can't Give You
The model is frozen. It knows 214 content types as of its training data. New file formats emerge. Attackers adapt. The ONNX model will need retraining, and Google's 100-million-file training corpus is not part of the open-source release.
You can fine-tune.
You can extend the content type registry. The model config format supports it. But training a model this accurate from scratch requires a dataset that most organizations simply don't have.
This makes Magika less like open-source software and more like open-weight AI. You get the inference, not the training. You get the gun, not the ammunition factory. It's incredibly useful. It's also strategically designed to keep Google at the center.
This is my perspective. You should do what you are comfortable with. But in the calculus of "should we use Google's open-source file identification tool or build our own," the answer is obvious. Use theirs. Build on top. Focus your energy on the parts of the security stack that aren't solved yet.
The first gate matters. Google just handed everyone the best one on the market.
I got you covered: pip install magika.
If you have read it until this point, Thank you! You are a hero (and a Nerd ❤)! I try to keep my readers up to date with "interesting happenings in the AI world," so please 🔔 clap | follow | Subscribe 🔔