

⚠️ Tools and techniques discussed in this blog is only for educational, ethical OSINT & vulnerability research purposes. Author not responsible for any misuse!
New to urlscan dorking ? Check from beginning
🌐 Site: urlscan.io
domain:example.com AND page.url:php
Sometimes, it's not visible in the first impression.
domain:example.com AND page.url:.jsp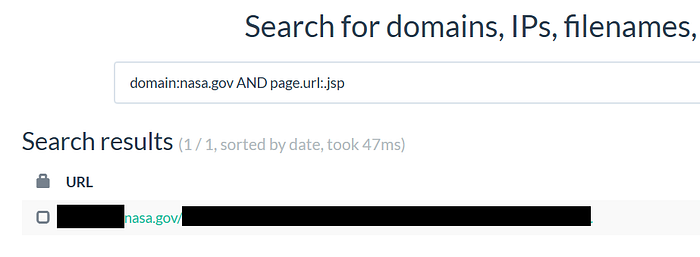
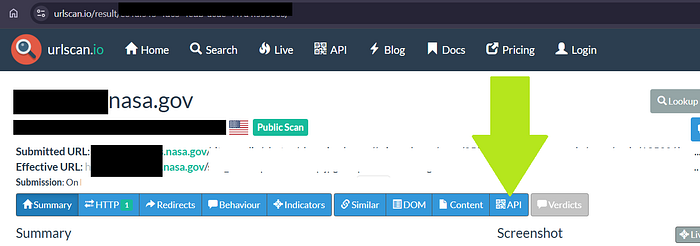
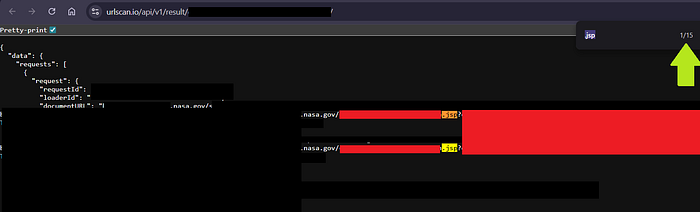
This isn't the end, it's the beginning of the narrow down approach. Instead of 10000+ subdomains, now we are more focused in which subdomains to start the active crawling using katana to find more urls of these extensions.
This recon helped us to filter the subdomains where there is possibility to find old pages.
In modern pages built with modern framework (e.g. react) they have pre-built protection from most common injection attacks (unless the dev makes the block of code insecure by himself). So shifting focus to old pages, hidden pages and forgotten pages is what will help for hunters which are after injection category vulnerability class. It's useful when all company owned assets (along with acquisitions) are in scope for wildcard broader scope hunting.
Recon through Google Cloud Shell
wget https://github.com/projectdiscovery/katana/releases/download/v1.4.0/katana_1.4.0_linux_amd64.zip
unzip katana_1.4.0_linux_amd64.zip
katana -hJSP files recon
katana -u sub.example.com | grep "\.jsp"
katana -u sub.example.com | grep "\.jsp" > jsp_files.txt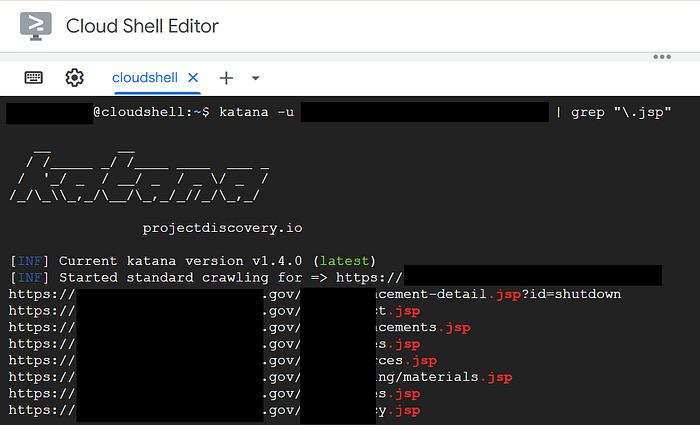
After this, open each page manually one by one, pick endpoints that has some features or functionalities or input fields to play with via proxy.
It's not about how much recon data you have… It's about how you use it :)
