
The visible part of the market still looks like developers chatting with models. The real change is deeper: organizations are starting to hand software work to systems that can read repositories, invoke tools, open pull requests, and affect production reality. Once that shift happens, the limiting factor is no longer prompt quality. It is whether the work is governable.
The operational reality
A prompt is cheap to improve. A production incident is not. That is why the "better prompting" conversation starts to feel thin the moment an agent leaves the chat window and enters a workflow with write access, credentials, CI permissions, or deploy rights.
We at CAISI keep seeing the same pattern beneath the hype. Teams evaluate agents with demos, choose a model, and write a dense instruction block that sounds responsible. Then they ask the system to modify code, run shell commands, or interact with connected tools. What matters next is not the cleverness of the prompt. What matters is whether there is any enforceable boundary between intent and action.
The reason this matters now is simple. "Copilot for one engineer" is not the end state. The end state is a background system that can take a ticket, plan the work, touch multiple files, run validations, explain what it changed, and hand a reviewer something coherent. Once the work becomes asynchronous and repeatable, governance becomes part of the runtime.
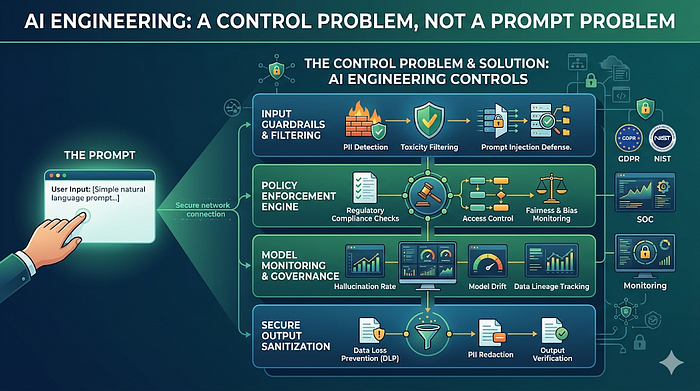
The anti-pattern
The anti-pattern is prompt-centrism: treating the quality of the instructions as if it were the same thing as control. It is not. A prompt can express intent, constraints, style, and local rules. It cannot, by itself, prove what executed, stop a write-capable action, or produce an evidence chain when something goes wrong.
This is the same mistake teams made in earlier automation waves when they confused a runbook with a control plane. A runbook tells a system what should happen. A control plane determines what can happen, what did happen, and what can be proven afterward. The difference only becomes obvious under pressure.
Serious teams do not buy novelty. They buy bounded behavior, deterministic validation, and evidence they can defend later.
The better system pattern
The better pattern is to treat AI engineering as a governed software delivery system. The model still matters, but it sits inside a larger machine: scoped context, deterministic commands, isolated execution, pre-execution policy, validation gates, reviewable artifacts, and promotion rules. In that world, prompts are one component, not the architecture.
Once you frame the problem that way, the optimization target changes. You stop asking, "Did the demo look smart?" and start asking better questions. Can the system stay inside the repo contract? Can it be stopped? Can it be replayed? Can a reviewer see what changed and why? Can AppSec inspect the write path before the action fires? Can the team explain a failure without assembling five dashboards by hand?
That is why the future of AI engineering is not "better prompting." It is better workflow design. The strongest teams will not be the teams with the most magical demos. They will be the teams whose autonomous work can be trusted to run at scale without becoming political overhead.
What leaders should optimize for instead
Once autonomy becomes part of software delivery, the right metrics change. Demo quality matters less than bounded throughput. A strong workflow should reduce cycle time without creating unexplained change risk. It should improve reviewer efficiency without hiding residual uncertainty. It should let AppSec approve a class of work with clear limits instead of forcing every run into a bespoke exception process.
That means leaders should optimize for stable interfaces, reusable blueprints, isolation, evaluation quality, and proof capture. Those are the things that make autonomous work compound. If the system depends on a handful of prompt experts to keep it inside the lines, it has not reached organizational scale yet. It has only concentrated the complexity in a small group of operators.
Why security cares
Unmanaged agents create three security problems at once. First, they expand the change surface. The system is no longer just generating suggestions. It can mutate repositories, call third-party tools, or interact with secrets and infrastructure. Second, they create supply chain ambiguity. Every connector, model, runner, script, and sandbox becomes part of the execution chain. Third, they create evidence gaps. After an incident, the question is not whether logs exist. The question is whether a coherent chain exists from trigger to action to outcome.
A buyer in AppSec is not trying to stop useful automation. They are trying to avoid silent scope expansion and unreviewable state changes. If the only control mechanism is "the prompt told it not to," the buyer is being asked to underwrite a change system without an actual boundary.
Why platform and engineering care
The internal ally sees a different pain first: ad hoc prompting does not scale across teams or repositories. One strong engineer can drive an agent interactively and get impressive results. That does not mean the workflow is reusable. It often means the human is doing the hidden orchestration that the system should have owned.
Platform teams need repeatability. They need a repo to behave like an interface. They need scripts that always enter the same validation path. They need workspaces that isolate competing runs. They need failure states that can be resumed instead of restarted from scratch. Most of all, they need an operating model that improves throughput without forcing every pull request into a manual incident review.
Concrete example: manual steering vs governed issue-to-PR flow
The contrast below is the shift that matters. One path depends on a single operator carrying the workflow in their head. The other turns work into a bounded, reviewable system.
1. Manual chat loop
An engineer repeatedly prompts, corrects, retries, and decides when to run tests. The workflow lives mostly in the human.
2. Governed trigger
A work item enters a known queue with scope, repo, boundary rules, and explicit validation entrypoints.
3. Controlled promotion
The run produces a patch, validation output, residual risk, and a PR packet that a reviewer can actually evaluate.
Practical next step
Pick one agent workflow your team already uses. Ignore the prompt for a moment and map the control surface instead.
- List every action the system can take that changes code, state, or external systems.
- Mark which of those actions are bounded by deterministic checks before execution.
- Mark which actions can produce a proof packet a reviewer could inspect later.
- Mark where the workflow still depends on a single strong operator doing hidden supervision.
That exercise will tell you more about AI readiness than another model comparison ever will. If most of the workflow still depends on human memory, prompt discipline, and goodwill, you do not have an AI engineering system yet. You have an expensive interactive assistant.
The next post stays on that line and moves one layer down: the repository itself. If the repo is the environment where work is read, interpreted, and validated, then the repo is part of the runtime contract.
We are working on that discovery problem if you want to look: https://github.com/Clyra-AI/wrkr