

1. Introduction to Search & Ranking
Every day, without even thinking about it, we interact with ranking systems.
Why? Because we use the internet all the time to search.
When you type "best wireless headphones" on Google, or when you browse "iPhone 17 Pro review" on YouTube, or when Netflix recommends "because you watched…", a ranking algorithm silently decides what you see first.
Search and ranking are the invisible engines of the internet.
Search is about retrieving relevant items from huge collections of data. It's the process of filtering billions of documents, products, or videos down to a smaller set that could answer your needs.
Ranking, on the other hand, decides the order of those results, which ones should appear on top and which can safely go on page two.
Without search, there's nothing to rank. Without ranking, we'd drown in information.
In this article, we'll explore what Search and Ranking is, its traditional approaches, and how Machine Learning changed everything.
We will cover these key points:
- What are the traditional search ranking approaches
- What are the main Machine Learning methods
- The most important real-world applications
- The core challenges in building a reliable search ranking system
2. Traditional Approaches to Search
Before Machine Learning, search was mostly rule-based, built on clever mathematical formulas and human intuition rather than learned patterns.
Let's look at some of the pillars of traditional search systems.
a) Inverted Indexes: The Foundation
At the core of most search engines, we find an inverted index: a data structure that maps words to the documents that contain them.
It's "inverted" because instead of listing words within documents, it lists documents for each word.
So if you search for "machine learning," the engine instantly retrieves all documents containing both "machine" and "learning":
"machine" → [doc1, doc5, doc7, doc10]
"learning" → [doc5, doc4, doc7, doc8]
The algorithm will intersect these lists to give us the documents [doc5, doc7].
It's simple, elegant and lightning fast.
b) TF-IDF: Measuring Importance
Once documents are retrieved, the engine needs to decide how relevant each one is.
How? With TF-IDF, short for Term Frequency–Inverse Document Frequency.
It's a beautifully simple idea that calculates how important a word is to a document, relative to the whole collection.
- TF (Term Frequency): How often does a word appear in this document?
- IDF (Inverse Document Frequency): How rare is this word across all documents?
Combine them and you get a score that highlights words that are frequent in one document but uncommon in the corpus. These are the words that truly define that document.
For example, in a page about "Python programming," the word "Python" has a high TF-IDF because it's frequent there but not in every other page.
Higher TF-IDF → word is frequent in a document but rare across others.
TF-IDF revolutionized early search engines because it gave a quantitative measure of relevance.
But it had limitations: it only looked at word counts, not meaning.
c) BM25: A Smarter Scoring Function
Then came BM25, an evolution of TF-IDF that introduced a more refined scoring approach.
It accounts for:
- Diminishing returns: Repeating a word 100 times doesn't make it infinitely more relevant.
- Document length normalization: Longer documents shouldn't automatically get higher scores.
BM25 remains incredibly strong for keyword-based search. Even today, many production systems still use it in the first retrieval stage before applying ML re-ranking models.
How Traditional Search Ranking Works
The overview of the Traditional Search Ranking Systems is shown below.
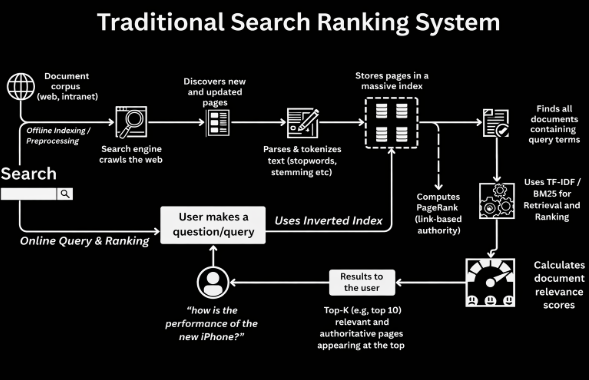
Let's break it down into 7 simple steps:
1. Crawling Search engine bots (called crawlers or spiders) continuously explore the web by following hyperlinks. They discover new and updated web pages and their content, and report it back to the search engine. The goal is to build a comprehensive, up-to-date view of the web.
2. Parsing & Tokenization Each page is now parsed and processed: text is cleaned, HTML tags are removed and the content is broken into tokens (think of a single "token" as a single "word"). Common preprocessing steps include stopword removal, lowercasing and stemming or lemmatization. The target is to convert raw text into indexable, comparable terms.
3. Indexing The processed documents are stored in an inverted index, a data structure mapping each word to the documents that contain it. This allows instant lookup of all pages mentioning a given query.
4. Authority Scoring (PageRank) Beyond textual content, traditional systems compute a static authority score for each page based on its inbound links, known as PageRank. This captures a page's global importance, independent of the query. A page linked by many other reputable pages is deemed more authoritative.
5. Query Processing & Matching When a user submits a question or a search query, the engine parses it into tokens and looks them up in the inverted index. It then retrieves all candidate documents that contain one or more of those query terms.
6. Relevance Scoring (TF-IDF / BM25) Now, each candidate document is scored based on how well its content matches the query. Formulas like TF-IDF and BM25 measure term frequency, rarity and document length to compute a relevance score.
7. Ranking & Output Finally, the engine sorts all scored documents in descending order of relevance and combines them with authority signals (e.g., PageRank). The top-K results (often the first 10) are displayed to the user.
Approaching the Layers
These approaches, while great at first, faced a serious problem: ignoring meaning and context.
In more detail:
- No understanding of synonyms or context. "Laptop" and "notebook" are treated as different words, even though users might mean the same thing.
- Poor handling of ambiguous queries. Searching for "apple" could mean a fruit or the company, and traditional methods can't guess the intent.
- Static, non-adaptive rules. These methods don't learn from user feedback. If people stop clicking on certain results, the system won't notice.
In other words: traditional search systems are static.
They don't evolve with users. And in a world where millions of new queries and documents appear every hour, that's a serious limitation.
3. Search Ranking with Machine Learning
Search ranking today is dominated by Machine Learning (ML) models. The transition from static formulas to data-driven systems was one of the biggest revolutions in information retrieval history.
Instead of engineers writing explicit rules, ML systems learn what "relevance" means by observing user behavior.
They don't just count words. They capture relationships, patterns and context across millions of interactions.
Let's see the main pillars of ML-based ranking:
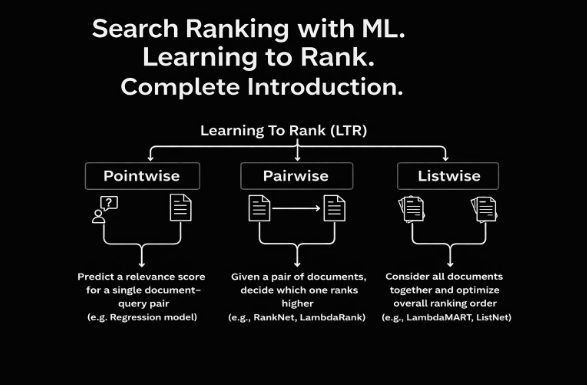
a) Learning to Rank (LTR)
At its core, ranking with ML means optimizing the order of results.
This is a special kind of supervised learning called Learning to Rank (LTR).
LTR models are trained on historical data where queries, documents and user interactions are known. Each query–document pair is assigned a label indicating how relevant the document was for that query, sometimes binary (relevant/not relevant), sometimes graded (e.g., 0–3).
The model learns a scoring function f(q,d) that predicts how relevant a document d is to a query q. When a new query arrives, it scores all candidates and sorts them by predicted relevance.
There are three major paradigms:
- Pointwise: Treat each document individually and predict its relevance score.
- Pairwise: Compare pairs of documents to learn which one should rank higher.
- Listwise: Optimize the entire ranked list at once (e.g., using NDCG-based loss).
Even simple models like linear regression can work surprisingly well here, though tree-based methods (e.g., LambdaMART) and neural models dominate modern systems.
b) User Feedback as Data
The biggest breakthrough of ML-based ranking is its ability to learn from user interactions.
Instead of manually labeling data, systems collect implicit feedback:
- Clicks: If users click a result, it might be relevant.
- Dwell time: If they stay longer on a page, even better.
- Purchases or sign-ups: Strong signals of satisfaction.
This continuous feedback loop lets models evolve automatically. When users start preferring newer or more specific results, the model catches on.
Of course, feedback data can be noisy, and users tend to click higher-ranked items more often just because they're higher (position bias). But the overall benefit is clear: ranking systems become living, learning entities.
c) Context-Aware and Neural Networks
Recent years brought a new wave: contextual and semantic ranking using Neural Networks.
Instead of relying on manually crafted features (like word overlaps or TF-IDF scores), Neural models represent text as dense vectors (embeddings) that capture meaning.
For example, using models like BERT or Sentence Transformers, both "car hire" and "rental car" would have similar embeddings, meaning that the system recognizes them as semantically close even if the words differ.
This unlocks more human-like understanding of queries and documents, enabling:
- Better handling of synonyms and paraphrases.
- Understanding of intent and context.
- Multi-modal search (text, image, voice).
These models often combine with traditional methods (e.g., BM25 for initial retrieval → BERT for re-ranking).
The result: fast, scalable, context-aware ranking systems that continually evolve and learn.
How Search Ranking with ML Works
Here's the high-level diagram of using Machine Learning for Search Ranking:
Now let's break it down into 7 steps:
1. Crawling & Data Collection Search engine crawlers explore the web, following links to find new and updated pages. Now, in addition to web content, the system also collects user interaction data (clicks, dwell time, engagement logs) to feed the learning process.
2. Feature Extraction Each document and query is converted into a structured set of features. These include text embeddings, metadata (title, freshness, popularity), link signals and user behavior metrics. These features represent textual, contextual and behavioral information numerically for ML input.
3. Feature Storage / Document Index All extracted features are stored in a feature store or extended index. Unlike the simple inverted index of traditional systems, this store contains both textual and behavioral features for each document.
4. Model Training (Learning-to-Rank) Using past query-document pairs and relevance labels (from clicks, dwell time or human judgments), the system trains Learning-to-Rank (LTR) models. Common algorithms include LambdaMART, LightGBM and BERT-based neural rankers. The goal is to learn a scoring function that predicts a relevance score.
5. Candidate Retrieval When a user enters a query, the system quickly retrieves a few hundred potential documents using BM25 or vector search (semantic retrieval). This narrows billions of documents down to a small candidate set efficiently.
6. ML Ranking Model (Inference) The trained ranking model evaluates each candidate document and predicts its relevance score given the query. It considers textual, contextual and user-specific signals to personalize results.
7. Output & Personalization The system sorts documents by predicted score and presents the Top-K results to the user. Results are personalized by context, such as user history, device, time or location.
What are the Benefits of ML-Based Ranking?
Compared to the traditional ranking method, ML-based Search Ranking is:
- Adaptive: Learns from data instead of relying on static formulas.
- Personalized: Can tailor results per user, device or context.
- Robust: Combines multiple signals beyond simple keyword matching.
- Evolving: Can retrain regularly as user behavior shifts.
In short, ML ranking is dynamic, just like the world of information itself.
4. Real-World Applications
To understand the scale and diversity of ranking systems, let's explore where they show up.
Real-World Search Ranking Applications
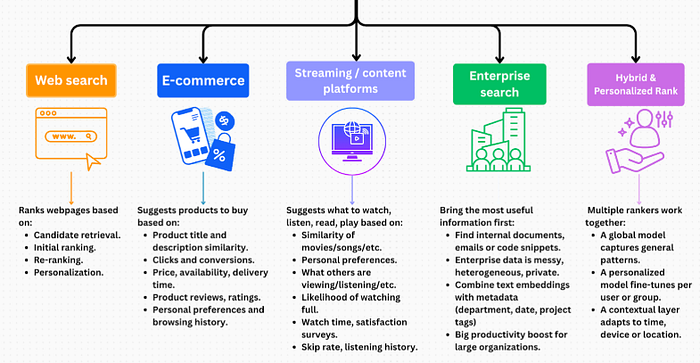
a) Web Search
This is the most obvious use case. Search engines like Google and Bing use massive ML systems with hundreds of features, from text similarity to freshness, authority and user engagement.
A query triggers several ordered stages: candidate retrieval, initial ranking, neural re-ranking, and personalization. Every stage runs in milliseconds at web scale.
b) E-Commerce Search
Think about Amazon, eBay or any online store. Ranking models decide which products you see first, not just by textual match but by likelihood of purchase. Signals include product similarity, clicks, price, reviews, and personal history. A slight improvement here can increase revenue by millions.
c) Streaming & Content Platforms
Netflix, YouTube and Spotify rank content by engagement probability. The objective changes from purchase to watch time, satisfaction, or skip rate. The principle is identical: use data to show the most probably engaging content first.
d) Enterprise Search
Inside companies, ML ranking helps employees find internal documents, emails or code snippets. Models here combine text embeddings with metadata (department, date, project tags) to surface the most useful internal knowledge.
e) Hybrid & Personalized Ranking
In many modern systems, multiple rankers work together: a global model, a personalized model, and a contextual layer. For example, the same search "best coffee" might return nearby cafés on mobile, but coffee beans on a desktop.
5. Core Challenges of ML Search Ranking
Building a ranking system sounds elegant on paper, but in reality it's filled with many high-impact challenges.
a) Defining Relevance
Relevance is subjective. What's relevant for one user might be irrelevant for another. This ambiguity makes collecting "ground truth" labels difficult. Human annotators may disagree, and users themselves change their intent over time. Relevance is a moving target.
b) Bias in Training Data
Most ranking systems learn from click logs. But clicks are biased — users often click the top results simply because they appear first. This position bias can create a self-reinforcing loop. Researchers address this using randomization experiments (A/B testing) and counterfactual learning.
c) Scalability
Large-scale search means billions of documents and millions of queries per second. Models must compute relevance scores in milliseconds. That's why ranking systems are often multi-stage: retrieve candidates fast with cheap methods, then re-rank only the top few hundred with expensive ML models.
d) Fairness & Personalization
Personalization is powerful but it can trap users in filter bubbles. If your model always shows what users already like, they'll never discover new content. There's also the challenge of ensuring small sellers or minority voices aren't systematically ranked lower.
6. Summary & Key Takeaways
- Search and ranking systems are the backbone of modern digital experiences.
- Traditional methods (TF-IDF, BM25) are static and can't capture meaning or adapt.
- Machine Learning models learn relevance dynamically from user feedback and context.
- Learning-to-Rank (LTR) frameworks (pointwise, pairwise, listwise) are the core of modern systems.
- Real-world applications span web search, e-commerce, streaming, and enterprise platforms.
- Key challenges include defining relevance, mitigating bias, ensuring scalability, and balancing personalization with fairness.
The field continues to evolve rapidly with neural networks and LLMs, making it one of the most exciting areas in applied machine learning.