

Before deep learning, ML was built from statistics + optimization theory, Ronald fisher and Vladmir vapnik was the key contributor in this domain. core idea is learning patterns from data using mathematically defined models, to make better prediction. Input data so as learn rule to predict output.
Not all data is numeric; some values represent categories or labels. try to use cat boost regression which include gender labels, that might help you in a plethoric way. every group memory has a identity how they represent, not magnitude. Now to predict continuous values efficiently using boosted decision tree is possible with LightGBM regression, build many small tree each correct previous errors. it is fast, low memory gradient boosting machine, more accurate, but can overfit.
XG boost is extreme gradient boosting, a model that built trees step by step carefully. think like tree usually has memory. but leaf growth has high speed, but overfit issue if not cutten on time, stability wise choose XG boost.
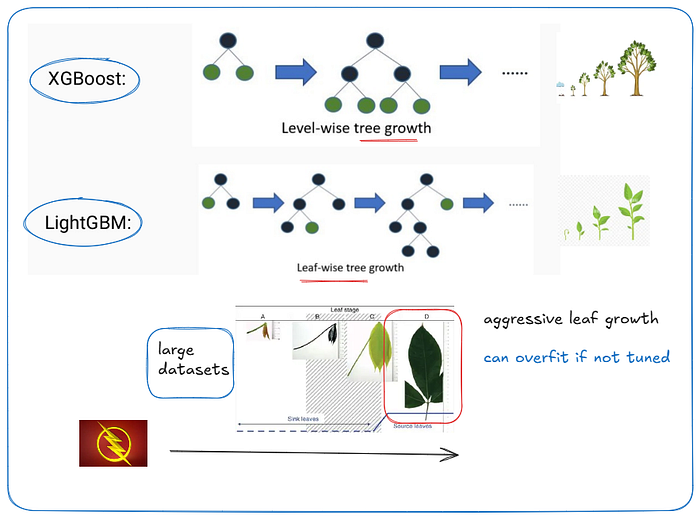
start with XG boost and move to Light GBM if scaling is vital for company's growth.
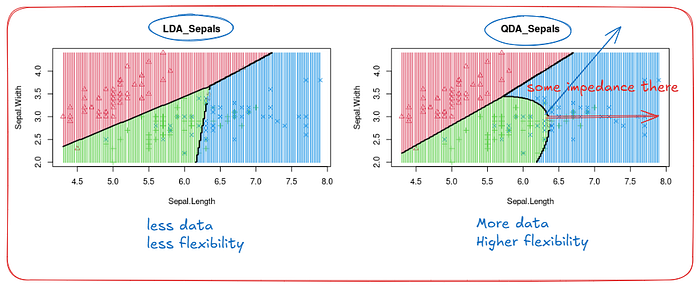
Ronald A fisher introduced next important term linear discriminant analysis and QDA, if you draw a separate boundary to separate classes based on data distribution and drawing a curved boundary to better complex data, it is efficacious for learning. Mostly in higher it will tend to behave fisher information matrix and overfit issue, recommended QDA for high level task.
Next there comes ADABOOST, but here just like mixture of expert, i can call it as mixture of weakens and focus on their mistake each time, like a holistic approach is taken. it is adaptive boosting over MOE models. fairness going to ad boost over MOE but building like high end model which parsimonious require VL JEPA, V-JEPA q learning and even MOE that's cheaper way.
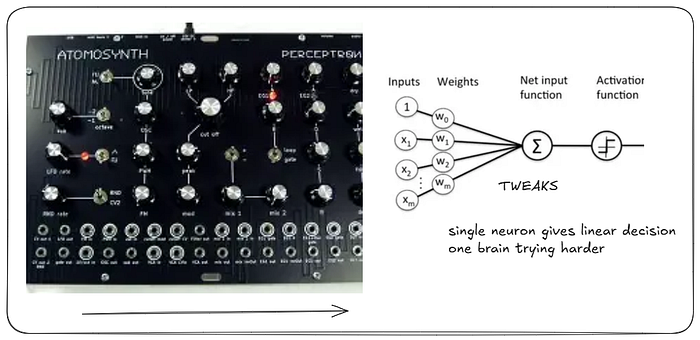
if a single model that can draw a single straight line to separate data is efficacious, try to mimic how neurons detect signals, which is known as perceptron. if prediction is wrong, adjust weight to correct it. Always linear. one brain trying harder saves time than most of the weak brain corroborating and improve it, like ada boost.
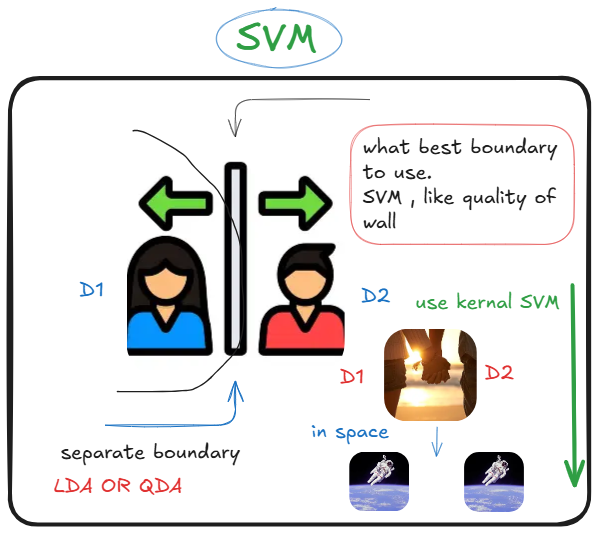
in the LDA or QDA we actually separate boundary to separate class, now what we can find the best boundary? for simplex operation recommended SVM, but in a complex pattern require kernel SVM, overfit risk elevate as usual, speed is slower take arduous time. The etymology of support vector machine is not really a suitable word, rather it should be separation vector machine.
optimize margin in transformed space > optimize margin in original space.
if your self-model makes decision by asking a series of simple questions it is decision tree, through algorithms like classification and regression tree it became really famous, and build many decision trees and combine their answers, we get Random Forest.
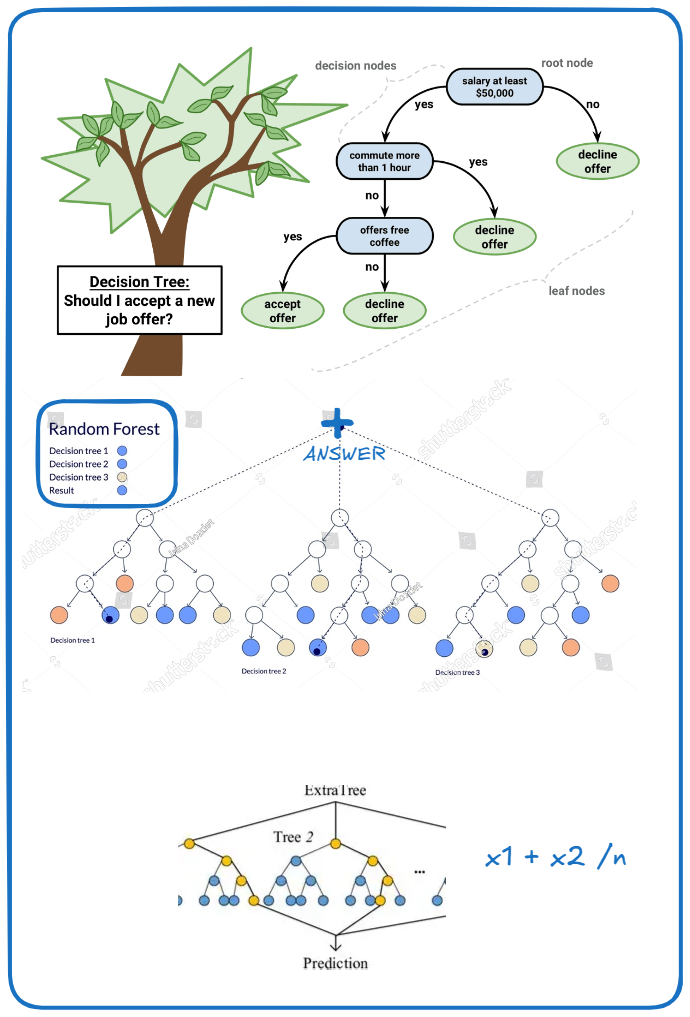
A forest of this decision trees where splits are made more randomly than usual, instead of choosing best split choose the best splits and average results make sense, that is extra trees.
Next comes , what we have ? just a probability and pick the most likely class assuming features don't influence each other is naive bayes each feature is modeled using a gaussian distribution per class, like BP, glucose etc. in the gaussian naive bayes and when feature is treated as present or absent is considered to be Bernoulli Naive bayes.

To predict something,look at the k closest data points and take their majority vote. you are what your nearest neighbours are. KNN is a lazy learner, stores all data, no training phase, computation happens only during prediction. works well in small datasets, low dimensional data, clear clusters, large k it is smoother and small k it is overfits, it is like memory of examples. KNN asumes proximity in feature spaces, if distance is meaningless ,model wil turn meaningless, so good feature scaling is essential as well as meaningful distance metric.
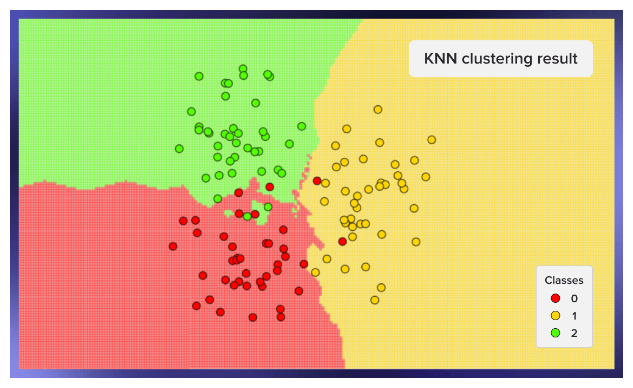
I explained here,
- Logistic Regression
- Naive Bayes
- Gaussian Naive Bayes
- Bernoulli Naive Bayes
- Multinomial Naive Bayes
- K-Nearest Neighbors (KNN)
- Support Vector Machine (SVM)
- Kernel SVM
- Decision Tree
- Random Forest
- Extra Trees
- AdaBoost
- Gradient Boosting Machine (GBM)
- XGBoost
- LightGBM
- CatBoost
- Perceptron
- Linear Discriminant Analysis
- Quadratic Discriminant Analysis