

Pourquoi la sécurité côté client ne suffit pas (Client-Side Security) ?
Dans le développement des applications web modernes, la sécurité est un enjeu majeur. Parmi les différentes approches existantes, certaines validations sont directement implémentées côté client, dans le navigateur de l'utilisateur.
Mais ces mécanismes sont-ils réellement fiables ?
Imaginez une application web de vente en ligne. Pour simplifier certaines opérations, une partie de la logique de l'application est directement exécutée dans le navigateur de l'utilisateur.
Par exemple, le prix d'un produit peut être utilisé côté client afin de calculer rapidement le montant total d'une commande.
À première vue, cela peut sembler pratique et efficace.
Mais posez-vous une question simple :
Que se passerait-il si un utilisateur décidait de modifier ces valeurs directement dans son navigateur ?
Supposons qu'un produit soit affiché à 50 000 FCFA. Si la logique de calcul est entièrement gérée côté client, un utilisateur pourrait théoriquement modifier cette valeur avant l'envoi de la commande.
Par exemple :
prix = 50000 (Prix de base)
→ prix = 500 (Prix après modification)Dans une application web, le navigateur de l'utilisateur exécute du code qui lui est entièrement accessible. Cela signifie qu'un utilisateur peut observer, modifier, ou même supprimer certaines règles implémentées côté client.
Autrement dit: Si une règle de sécurité existe uniquement dans le navigateur, elle peut être modifiée ou supprimée.
Comprendre ce principe est essentiel pour toute personne qui souhaite apprendre la cybersécurité ou développer des applications web sécurisées.
Dans cet article, nous allons voir pourquoi les mécanismes de sécurité côté client ne peuvent pas être considérés comme fiables.
Comment fonctionne une application web ?
La plupart des applications web reposent sur une architecture appelée client / serveur.
Dans ce modèle, deux éléments principaux interagissent :
- le client, qui correspond au navigateur de l'utilisateur
- le serveur, qui héberge l'application et les données
Lorsqu'un utilisateur visite un site web, son navigateur envoie une requête au serveur afin de demander une ressource, comme une page web ou des informations spécifiques.
Le serveur traite ensuite cette requête et renvoie une réponse au navigateur.
Ce fonctionnement peut être résumé simplement :
Navigateur (client) → requête → serveur
Serveur → réponse → navigateurLe navigateur reçoit alors différents éléments nécessaires à l'affichage du site :
- du HTML pour la structure de la page
- du CSS pour le style
- du JavaScript pour la logique et les interactions
Ces éléments sont ensuite exécutés directement dans le navigateur de l'utilisateur.
Et c'est précisément ici que se trouve le problème.
Le navigateur fonctionne dans un environnement entièrement contrôlé par l'utilisateur.
L'utilisateur contrôle totalement son navigateur
Dans une application web, le navigateur joue un rôle essentiel : il exécute le code nécessaire au fonctionnement de l'interface.
Cependant, contrairement au serveur, le navigateur fonctionne dans un environnement qui appartient entièrement à l'utilisateur. Cela signifie que tout ce qui est exécuté côté client peut être observé, modifié ou supprimé.
Lorsqu'un serveur envoie une page web au navigateur, celui-ci reçoit du HTML, du CSS et du JavaScript, qui sont ensuite exécutés localement sur la machine de l'utilisateur.
En pratique, cela signifie que l'utilisateur peut :
- Consulter le code
- Modifier certaines valeurs utilisées par l'application
- Altérer le comportement de l'application
Autrement dit, toute logique implémentée uniquement côté client peut être manipulée.
Dès qu'un code est exécuté sur la machine de l'utilisateur, celui-ci peut potentiellement le modifier.
Cette caractéristique est fondamentale pour comprendre pourquoi les mécanismes de sécurité côté client ne peuvent pas être considérés comme fiables.
Comment les règles côté client peuvent être manipulées ?
Puisque le code exécuté dans le navigateur est accessible, certaines règles implémentées peuvent être contournées.
Ces mécanismes sont souvent conçus pour améliorer l'expérience utilisateur, mais ils ne constituent pas une protection fiable.
Exemple 1 — Modification d'une valeur
Reprenons l'exemple d'une application de vente en ligne.
Supposons que le prix d'un produit soit utilisé côté client pour calculer le montant total d'une commande.

Dans ce cas, si le serveur ne vérifie pas la valeur réelle du prix, la commande pourrait être traitée avec une valeur incorrecte.
Exemple 2 — Modification du comportement
Un utilisateur peut également :
- activer un bouton désactivé
- modifier un champ caché
- envoyer des données différentes
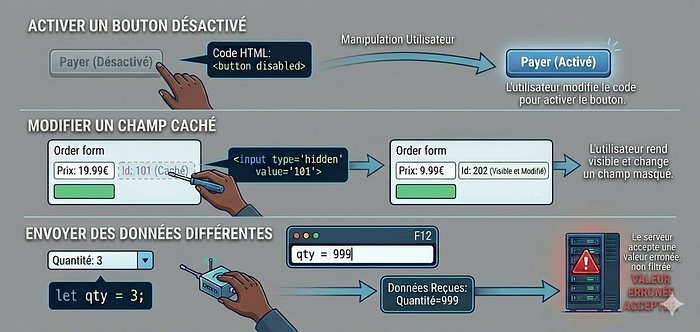
Ces manipulations permettent de contourner les règles prévues par l'interface.
Le principe fondamental : Never Trust the Client
Ces exemples illustrent une réalité simple mais souvent sous-estimée : le client ne peut pas être considéré comme un environnement de confiance.
Le code exécuté dans le navigateur étant contrôlé par l'utilisateur, toute règle côté client peut être modifiée.
C'est pour cette raison qu'un principe fondamental de la sécurité web est le suivant :
Never Trust the Client.
Autrement dit, toute donnée provenant du client doit être considérée comme potentiellement manipulée.
Les validations côté client restent utiles pour améliorer l'expérience utilisateur, mais elles ne doivent jamais être considérées comme suffisantes pour garantir la sécurité.
Toutes les vérifications critiques doivent être réalisées côté serveur, dans un environnement qui n'est pas contrôlé par l'utilisateur.
Cependant, cela ne signifie pas que le serveur est totalement sécurisé. Des vulnérabilités peuvent également exister côté serveur, mais celles-ci ne sont pas directement contrôlées par l'utilisateur, contrairement au client.
Conclusion
Les mécanismes implémentés côté client permettent d'améliorer l'expérience utilisateur en rendant les applications plus interactives et réactives.
Cependant, comme nous l'avons vu, le navigateur fonctionne dans un environnement entièrement contrôlé par l'utilisateur. Le code exécuté côté client peut donc être modifié ou détourné.
Dans ces conditions, toute règle de sécurité reposant uniquement sur le client peut être contournée.
C'est pourquoi il est essentiel de considérer toute donnée provenant du client comme non fiable et de toujours effectuer les vérifications critiques côté serveur.
Comprendre ce principe est une étape fondamentale pour analyser les vulnérabilités des applications web et concevoir des systèmes plus sécurisés.