

When the Alerts Never Stop
Picture your on-call engineer at 3 AM, three thousand simultaneous alerts across six dashboards, a payment service quietly degrading, and no clear indication of where to start looking. Three hours later, the service comes back online. But the SLA is already gone, customers have already noticed, and your team is already spent.
This isn't a worst-case scenario. For IT teams managing multi-cloud, microservices-driven infrastructure, this is Tuesday. Alert fatigue, sluggish incident response, and data overload aren't isolated problems, they're symptoms of something more fundamental: the tools running modern IT simply haven't kept pace with the environments they're supposed to manage.
That's the problem AIOps was built to solve.
What AIOps Actually Means
Gartner coined the term in 2017 to describe the application of AI and machine learning to IT operations, specifically, to automate and sharpen the detection, correlation, and resolution of incidents. IBM frames it as a platform that uses big data and ML to handle event correlation, anomaly detection, and root cause analysis at a scale no human team can match.
In practice, AIOps is the convergence of four distinct capabilities working together
• Machine Learning: Algorithms that build baselines of normal behavior and keep refining their understanding over time.
• Big Data Analytics: Real-time ingestion of logs, metrics, traces, and events from across the entire technology stack.
• Observability: Not just knowing what broke, but understanding why the context behind system behavior.
• Automation: Acting on those insights intelligently, from routing alerts to the right team to remediating incidents without waiting for a human to intervene.
None of these capabilities is new in isolation. What makes AIOps different is how they combine, creating a feedback loop that gets smarter with every incident it touches.
Why Rule-Based Monitoring Has Hit Its Ceiling
Static, rule-based monitoring made sense when infrastructure was predictable and relatively contained. Today's environments are neither.
• Data overload: Modern applications generate billions of log entries every day. No team can review that volume manually, and most of it is noise anyway.
• Multi-cloud complexity: When your infrastructure spans AWS, Azure, GCP, and on-premises systems, visibility gaps are almost inevitable.
• Alert fatigue: EMA Research found that most IT teams routinely ignore the majority of alerts they receive, not out of laziness, but because the signal-to-noise ratio has become unworkable.
• Slow mean time to resolution (MTTR): Manual triage, digging through logs, escalating to different teams, waiting for someone with context to show up, adds hours to what should be a minutes-long process.
Throwing more headcount at the problem doesn't fix it. The complexity scales faster than teams can hire.
How AIOps Works in Practice
AIOps operates across a continuous loop of ingestion, analysis, and action
• Data Ingestion: Telemetry from across the entire stack logs, metrics, APM traces, cloud events flow into a unified platform that normalizes it for analysis.
• Event Correlation: ML algorithms cluster related events and suppress the noise, collapsing thousands of individual alerts into a single, actionable incident. An engineer who was staring at 3,000 alerts is now looking at one.
• Anomaly Detection: Instead of firing when a metric crosses a static threshold, AIOps uses dynamic baselines catching unusual behavior in context, before it cascades into an outage.
• Root Cause Analysis: By correlating signals across data sources, the platform surfaces a prioritized diagnosis in minutes. Not hours, not an inbox full of pings asking "is this related to your thing?"
• Automated Remediation: For well-understood issue types, AIOps can trigger fixes automatically restarting a service, scaling resources, rolling back a deployment without waiting for someone to wake up.
The Real Benefits
• Faster MTTR: AI-driven root cause analysis can cut resolution times by 50–80%, depending on the environment and maturity of the implementation.
• Reduced downtime: Predictive detection catches emerging issues before users ever notice them. Prevention is always cheaper than response.
• Operational efficiency: Engineers shift from reactive firefighting to proactive, strategic work, the kind that actually moves the business forward.
• Lower costs: Fewer outages, leaner operations, and reduced on-call burden translate directly into cost savings and better retention
AIOps vs. Traditional IT Operations
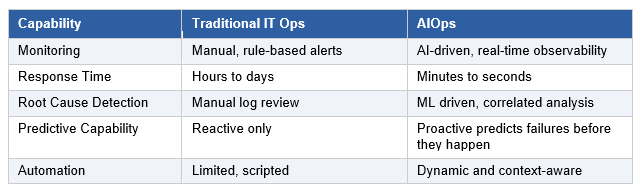
Traditional monitoring relies on static thresholds and manual correlation, which scales poorly across distributed, cloud-native environments. AIOps replaces that with real-time observability, ML-based anomaly detection, and automated root cause analysis across telemetry streams.
The most meaningful shift is in predictive capability. Traditional Ops is fundamentally reactive, triggered by failures after they occur. AIOps uses pattern recognition across historical and live data to forecast incidents before they impact users, often within a window that allows automated remediation to run before an alert is even raised.
Automation also evolves. Static runbooks give way to context-aware workflows that adjust based on system state, severity, and topology. The result is a measurable reduction in MTTR, alert noise, and on-call fatigue.
The Platforms Worth Knowing
The AIOps market has matured considerably over the past few years. Dynatrace remains a standout, particularly for its Davis AI engine and deep Kubernetes observability. Datadog has strong traction in cloud-native environments. Splunk IT Service Intelligence, IBM Watson AIOps, ServiceNow ITOM, and New Relic each bring different strengths depending on your existing toolchain.
Platform selection is rarely just a technology decision. It's also a question of where your team's expertise lives, which integrations you actually need, and what your organization can realistically adopt and maintain.
Where Implementations Get Complicated
AIOps delivers genuine value, but it's worth being clear-eyed about the friction involved
• Integration complexity: Connecting dozens of monitoring tools and data sources is time-consuming work that requires both technical skill and organizational patience.
• Data quality: ML models are only as useful as the data they learn from. Organizations with inconsistent logging practices will see degraded accuracy before they see improvements.
• Trust and explainability: Engineers are often skeptical of automated recommendations they can't trace. Explainability isn't a nice-to-have and it's a prerequisite for adoption.
• Cost and skills: Enterprise platforms carry significant licensing costs, and finding people who can bridge IT operations and data science is genuinely hard.
None of these challenges are insurmountable, but treating them as afterthoughts tends to undermine implementations that are technically sound.
Where This Is All Heading
For years, the future of AIOps lived mostly in keynote slides and vendor demos. That is no longer true. The next wave is already here, quietly showing up in production environments at companies that do not talk about it much, because they are too busy benefiting from it.
"The best AIOps deployments are the ones nobody notices, because nothing is breaking loud enough to mention."
Here is what that next wave actually looks like in practice
- Conversational Operations Generative AI has changed how engineers interact with their own systems. No more writing complex queries or stitching dashboards together at midnight. They just ask.
"What caused the latency spike in the payment service last night?"
A few seconds later, a clean incident summary appears. The kind that used to take a senior engineer two hours and three coffees to assemble.
2. Agents That Actually Do the Work Not chatbots. Not assistants. Real agentic systems that take an objective and run with it.
They can:
- Detect the issue the moment it surfaces
- Diagnose the root cause across distributed systems
- Execute the fix without waiting for approval on routine actions
- Verify the resolution end to end
- Document the entire incident automatically
The engineer reviews the outcome instead of doing the work.
3. Self-Healing Infrastructure, For Real This Time "Self-healing infrastructure" used to sound like marketing language. It has been circulating in the industry for years, mostly as aspiration.
"We used to talk about self-healing systems the way people talk about flying cars. Now they are running in our production stack, and nobody flinches."- Platform Engineering Lead at a Fortune 500 fintech
The difference now is that it is real. It is running quietly. Reliably. Often without the rest of the company even realizing it.
4. The Engineer's Job Is Quietly Being Redefined Look a few years ahead and the shape of the IT engineering role starts to shift:
- Less time firefighting
- Less time doing the same incident review for the fifth time this quarter
- More time on architecture decisions
- More time on resilience strategy
- More time on the long-term thinking that gets pushed aside every time a system goes down
"My team used to spend 70 percent of their week reacting. Today it is closer to 20 percent. That 50 percent has gone straight back into building things that matter."- Director of SRE at a global SaaS company
Key Takeaways
• AIOps combines AI, ML, big data, and automation to make IT operations proactive rather than reactive.
• It addresses the core pain points of modern IT: alert fatigue, data overload, slow MTTR, and multi-cloud complexity.
• Benefits include faster incident resolution, reduced downtime, leaner operations, and better customer experience.
• Leading platforms include Dynatrace, Datadog, Splunk, IBM Watson AIOps, ServiceNow, and New Relic.
• The future points toward autonomous operations, generative AI, and genuinely self-healing infrastructure.
The Bigger Picture
Modern IT infrastructure has outgrown the tools built to manage it. Systems that once lived in a single data center now stretch across clouds, edges, containers, and third-party APIs. The complexity has compounded faster than most management tooling has been able to adapt. AIOps closes that gap. Not by replacing the engineers who keep these systems alive, but by handing them sharper instruments to work with.
"You cannot run a 2026 infrastructure on 2010 operational thinking. The math simply does not work anymore."
The organizations getting the most out of AIOps are not the ones with the biggest budgets or the flashiest platforms. They are the ones treating it as an operational transformation, not a technology purchase.
The pattern is consistent across mature deployments:
- They start with clean data, not clever tools
- They align AIOps adoption with how teams actually work, not how vendors imagine they work
- They invest in trust and transparency so engineers lean into the system instead of around it
- They measure outcomes in time recovered and incidents prevented, not dashboards built
"The companies winning with AIOps are not the ones who deployed the most. They are the ones who deployed thoughtfully and stayed patient through the messy middle."-IT Operations Lead at a global logistics enterprise
The tools matter. But the work of aligning them with reality matters more.
What is becoming impossible to ignore is this: an intelligent operations layer is no longer optional infrastructure for any company running at scale. It is quickly moving from competitive advantage to baseline expectation.
"In five years, running enterprise IT without an AIOps layer will look the same as running a business without a CRM today. Technically possible. Practically unthinkable."
The systems we depend on are only getting more complex. The teams running them are only getting leaner. Something has to absorb that pressure, and the organizations that recognized this early are already pulling ahead.
In the years ahead, AIOps will be as foundational as the infrastructure it monitors. The only real question left is whether your organization builds that capability now, while it is still a differentiator, or later, when it is simply the cost of staying in the game.
The future of IT operations is not about humans versus machines. It is about humans finally having machines worthy of the systems they have built.