Önceki yazılarımızda konfigürasyon dosyalarını ve veri manipülasyonunu öğrenmiştik. Peki ya işler yolunda gitmezse? Bu yazıda, düzgün çalışmayan bir Splunk uygulamasını adım adım nasıl ayağa kaldıracağımızı göreceğiz.
Öncelikle cihazımızı başlatalım ve bağlanalım.
Soru1: FIXIT uygulamasının dizininin tam yolu nedir? Cevap: /opt/splunk/etc/apps/fixit
Uygulamalar /opt/splunk/etc/apps klasöründe bulunur. Kontrol edelim: gerçekten orada mı?
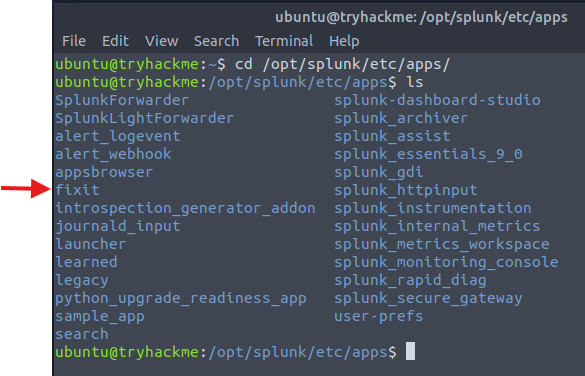
İşte burada sorunun cevabını buluyoruz.
Soru2: Bu çok satırlı olay durumunda olay sınırını tanımlamak için hangi kıtayı kullanacağız? Cevap: BREAK_ONLY_BEFORE
Bunun cevabını Splunk: Data Manipulation odasında Görev4 te bulabiliriz. Zaten bu odadan hemen önce o odaları çözdüğümüz için aklımızda kalmıştır.

Soru3: inputs.conf dosyasında network-logs komut dosyasının tam yolu nedir? Cevap: /opt/splunk/etc/apps/fixit/bin/network-logs
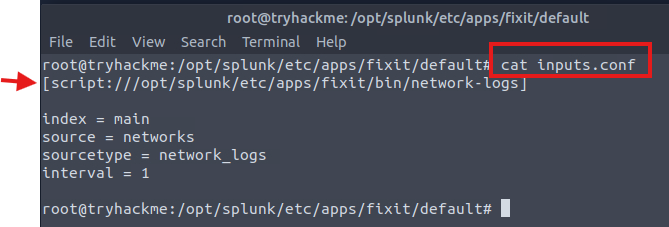
İşte burada sorunun cevabını buluyoruz.
Soru4: Etkinliğin başlangıcını belirlememize yardımcı olacak regex deseni hangisi olacak? Cevap: \[Network-log\]

bu bilgiye göre yazacağımız regex yapısı ise \[Network-log\] olmalıdır.
Soru5: Ele geçirilen etki alanı nedir? Cevap: Cybertees.THM
Burada Splunk arayüzüne girerek logları incelemeye başlıyoruz. Loglardaki domain bilgisini doğrudan görebiliyoruz, bu da doğru sonuca ulaşmamızı sağlar.
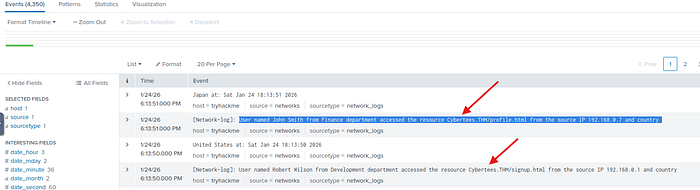
Soru6: Kayıtlarda kaç ülke yer alıyor? Cevap: 12
Bu noktadan sonra Splunk arayüzü üzerinden field extraction yaparak ilerliyoruz.
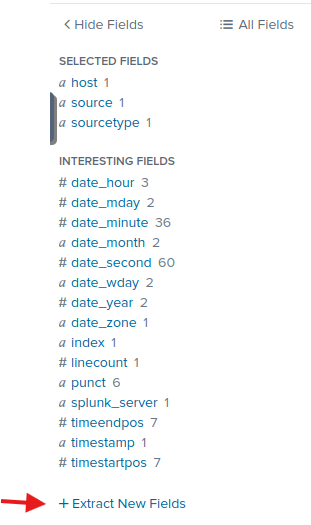
Şimdi fark ettiyseniz loglar parçalanmış durumda. Country den hemen sonra gelen kısım farklı bir log olarak kaydedilmiş durumda ama hepsi sıralı o yüzden sorun olmayacak.
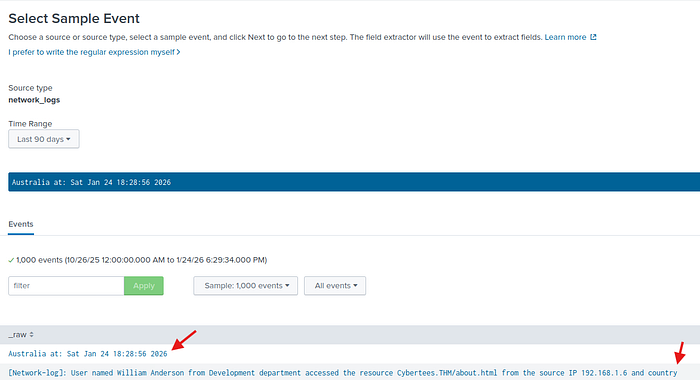
Eğer loglardaki ülkeleri direkt seçersek ne olur?
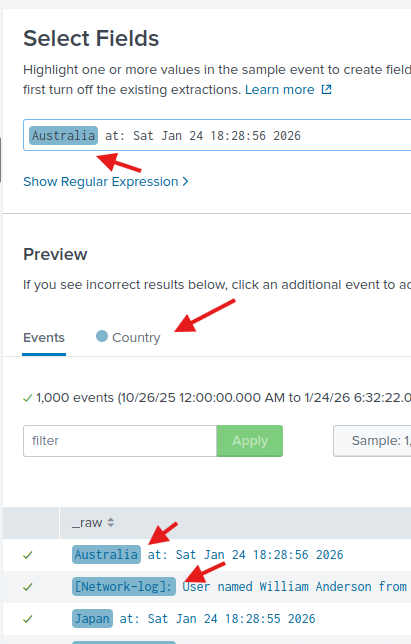
Görüldüğü gibi diğer loglardaki [Network-log] kısımlarını da alıyor. Normalde bunu regex kısmından düzenleme ile çıkartabiliriz ama sonucu etkilemeyeceği için gerek yok.
Devam edelim. Bir sonraki sayfada şunu fark ettim ki [network-logs] kısmını çıkartabiliyor muşuz ne güzel.

Yanlarında ki X e basınca istenmeyenleri çıkartabiliyoruz. Böylelikle [Network-log] olanların tamamını kaldırdım ve temiz bir fields ile devam ettim. Varsayılan regex yalnızca ilk kelimeyi alıyordu. Örneğin United States yerine sadece United geçiyordu. Bu yüzden United States ile United Kingdom birbirine karışıyordu. Bu yüzden sonunda gelen at: yapısına uygun olan farklı bir regex yapısı kullandım ve işte sonuç.
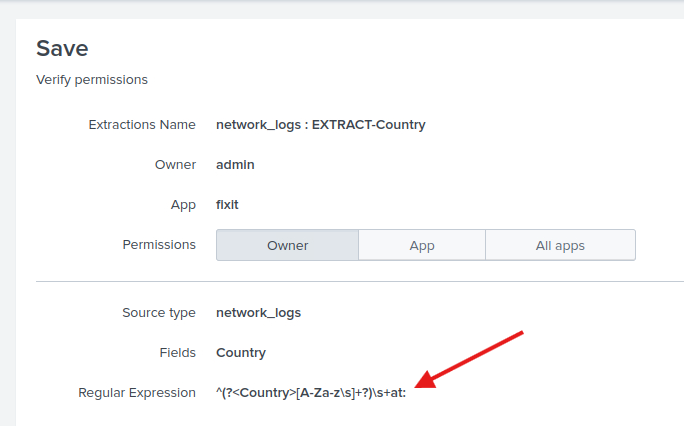
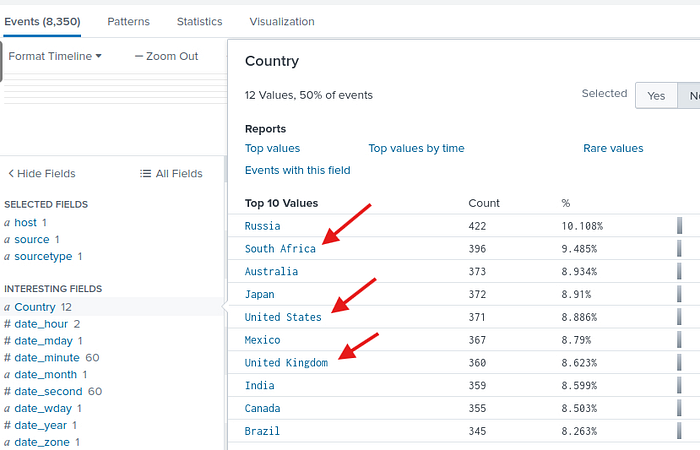
Karşımızda 12 farklı ülke.
Soru7: Kayıtlarda kaç departman yer alıyor? Cevap: 6
Hadi bunu da önceki gibi fields ile yapalım. Önceki soru için yaptığımız adımları aynen terkar ederek ilerleyelim.
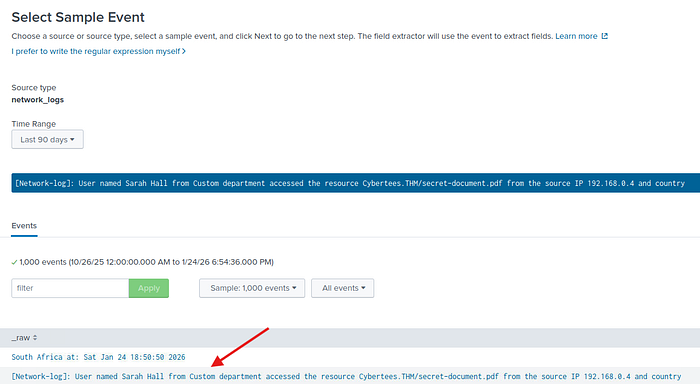
İstediğimiz veri total logun bu sefer bu tarafında. Seçip devam edelim.
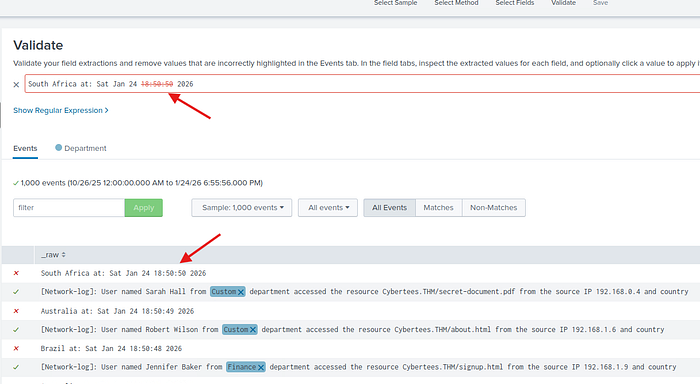
Diğer logun gereksiz kısmını da seçtiğimiz için onları kaldırıyoruz ve gerekli kısımla devam ediyoruz.
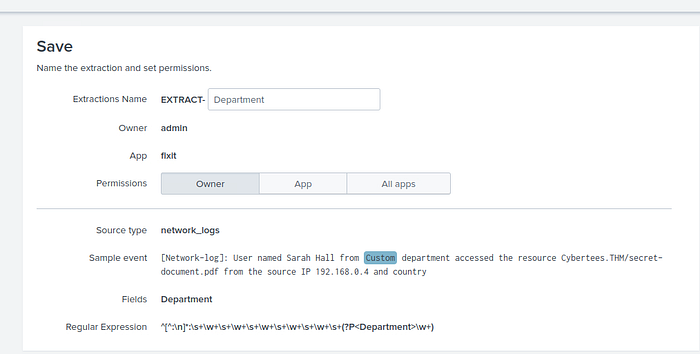
Sonuç olarak kullanılan regex yapısı bu oluyor ve istenilen cevap tam karşımızda. 6 farklı departman.
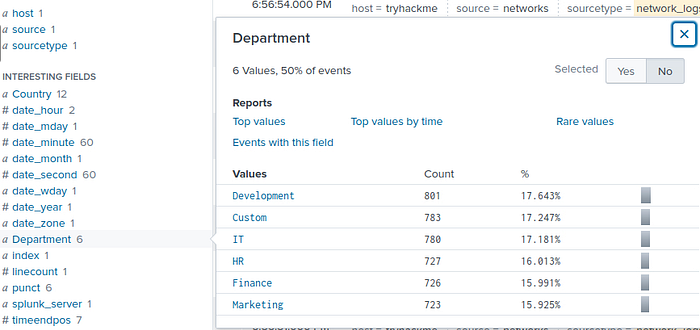
Soru8: Kayıtlarda kaç kullanıcı adı yakalanıyor? Cevap: 2
Şimdi de kullanıcı adı için yapıyoruz. Önceki adımlarla aynı adımları takip ederek alanları çıkarttım.
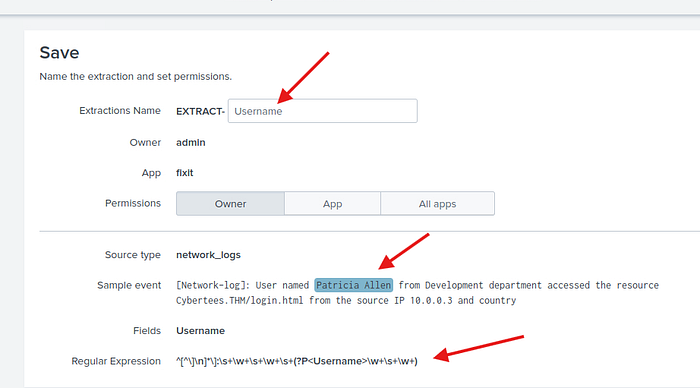
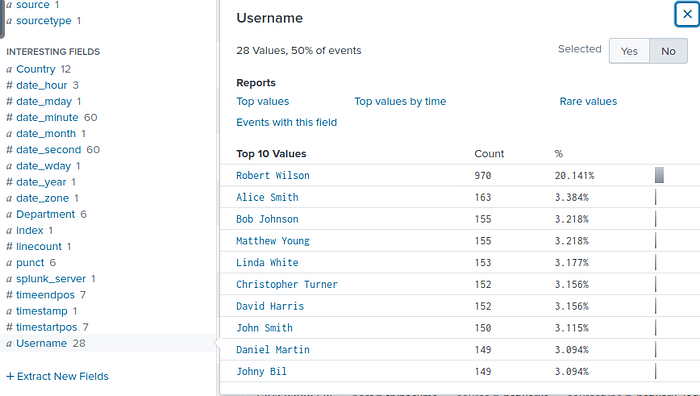
İşte karşımızda 28 farklı kullanıcı. Dikkatli olun username kısmı isim ve soyisim olarak kayıtlı bu yüzden iki kısmı birden alıyoruz. Eğer karma olsaydı ve kiminde sadece isim kiminde hem isim hem soyisim olsaydı regex yapısını çok daha farklı kurmamız gerekirdi.
Soru9: Kayıtlarda kaç adet kaynak IP adresi yakalanıyor? Cevap: 52
Bunun cevabına ulaşırken sistemin bana default olarak verdiği regex yapısının kimi ip yi aldığını kimi ip yi ise almadığını fark ettim bu yüzden regex yapısını değiştirmem gerektiği sonucuna ulaştım.
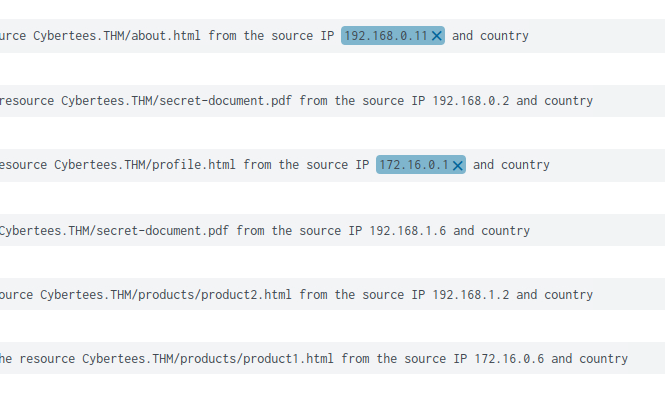
Yapıyı source ip ve and arasını alacak şekilde düzenledim ve işte sonuç.
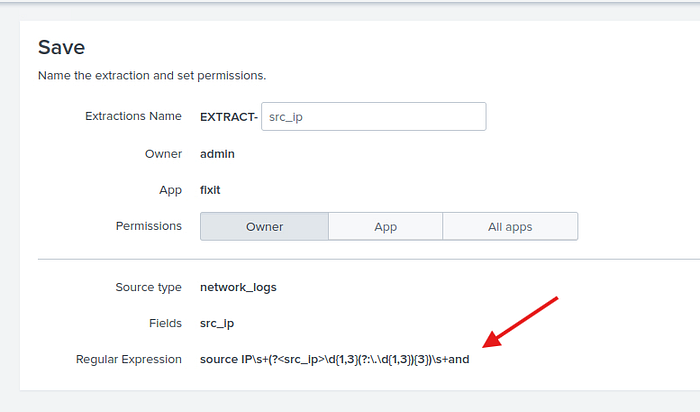
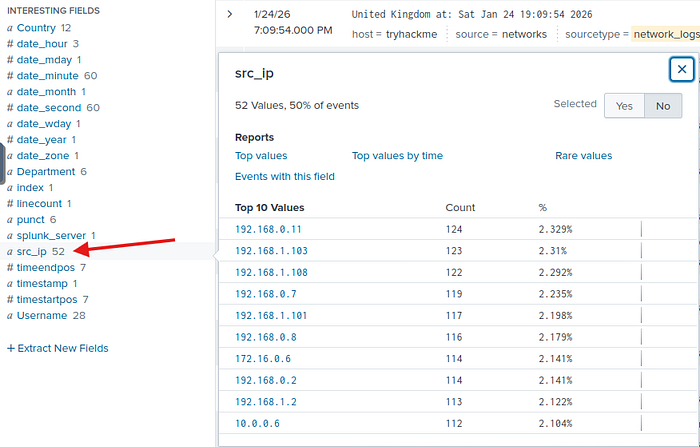
Karşımızda 52 farklı SourceIp adresi.
Soru10: Sorunumuzu çözmek için hangi yapılandırma dosyaları kullanıldı? [Alfabetik sıra: Dosya1, Dosya2, Dosya3] Cevap: fields.conf, props.conf, transforms.conf
Bu soruda trick var. Biz hiç yapılandırma dosyası kullanmadan bu soruların cevaplarına ulaştık. Mı acaba? Açıkçası bunları fields üzerinden oluşturduğumuz için elimizde direkt olarak bir .conf dosyası yok ama bunların zaten kullanım amacı bellidir. transforms.conf Regex ifadelerinin tanımlandığı dosyadır. Arayüz üzerinden yazılan regex'ler arka planda bu dosyaya karşılık gelecek şekilde işlenir. props.conf Hangi sourcetype veya source için hangi extraction kuralının çalışacağını belirler. Field extraction'ların loglara uygulanmasını sağlar. fields.conf Oluşturulan alanların Splunk tarafından tanınmasını ve arayüzde "Interesting Fields" olarak görünmesini sağlar.
Bu sorular benim tarafımdan fields ile çözülmüş olup bu .conf dosyaları kullanılmamıştır ama eğer kullanmak isteseydik. Bu 3 dosyayı oluşturup regex yapılarımızı gerekli konfigürasyon dosyasına yazarak çözüme ulaşabilirdik. Biz UI'dan yaptık ama Splunk aslında bunu böyle yapar.
Soru11: Kullanıcı Robert'ın alan adına erişmeye çalıştığı en yaygın iki ülke hangileridir? [Cevabı virgülle ayırarak ve alfabetik sırayla verin. [Format: Ülke1, Ülke2] Cevap: Canada, United States
İşte şimdi bu soruda takılıyoruz.
Bu noktada işler biraz karışıyor. Önceki sorularda, logların ikiye ayrılmış olmasına rağmen gerekli cevaplara logları birleştirmeden ulaşabiliyorduk. Ancak bu soru için aynı yaklaşım işe yaramıyor.
Neden mi?
Splunk'ta username alanından "robert" kullanıcısını filtrelediğimizde, ülke bilgisini içeren loglar tamamen devre dışı kalıyor. Yani:
- Kullanıcı bilgisi bir logta
- Ülke bilgisi başka bir logta
- Filtre uygulandığında bu iki bilgi artık aynı olayda buluşmuyor
Dolayısıyla Robert'ın erişmeye çalıştığı ülkeleri doğru şekilde analiz edemiyoruz.
Peki ne yapmalıyız?
Bu problemi çözebilmek için, ikiye ayrılmış logları tekrar tek bir event haline getirmemiz gerekiyor. Bunun yolu da Splunk'ta props.conf dosyasını kullanmaktan geçiyor.
Burada devreye şu yapı giriyor:
BREAK_ONLY_BEFORE
Bu yapı sayesinde, logların nereden bölüneceğini net bir şekilde tanımlayıp, yanlış parçalanmış event'leri tekrar birleştirebiliyoruz.
Yapılacaklar
props.confdosyasını oluştur- Gerekli
BREAK_ONLY_BEFOREkuralını ekle - Splunk servisini yeniden başlat
Bu adımlardan sonra:
- Robert kullanıcısı için filtreleme düzgün çalışır
- Ülke bilgileri kaybolmaz
- En sık erişilen ülkeler doğru şekilde analiz edilebilir
Ve böylece Soru 11'in cevabına sorunsuz şekilde ulaşırız.
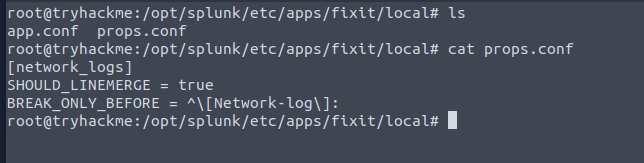

Göründüğü gibi artık loglarımız ayrı değil birleşmiş durumda. Username üzerinden Robert i seçtiğimizde Country verisine yine ulaşamıyoruz? Nedeni daha önceden regex yapısını ayrık bir log üzeirnden yaptığımız için ve o loglara ulaşamadığı için yine bize verileri vermiyor. bu yüzden country regex yapısını yeniden yazacağız. Bunun için fields ekleme üzerinden mevcut fieldsleri düzenleyelim.
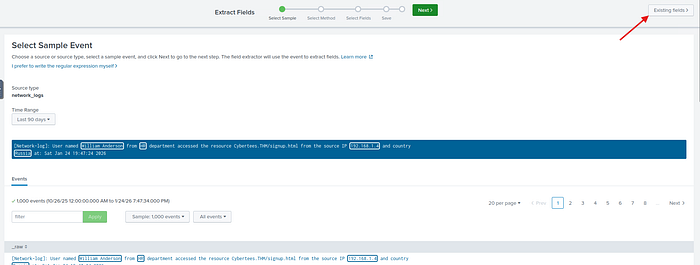
Burada normalde kutucuğu boş göreceksiniz çünkü eski regex sistemi aktif olduğu için sistem kabul etmiyor.
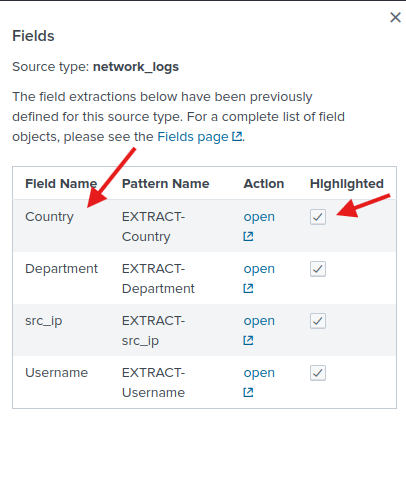
Open diyip regex i değiştirelim.
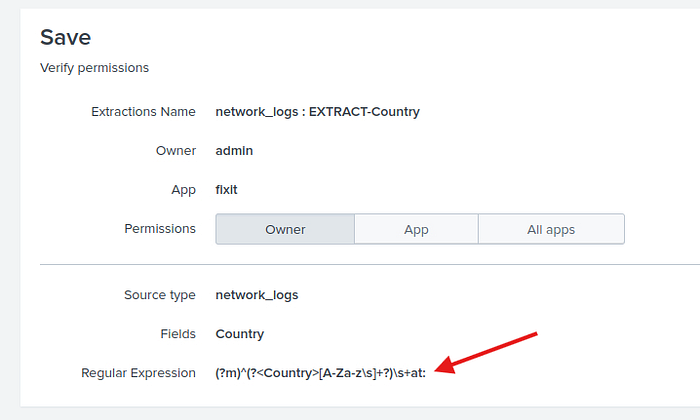
Yeni regex yapımızı seçip sonuçlara bakalım.
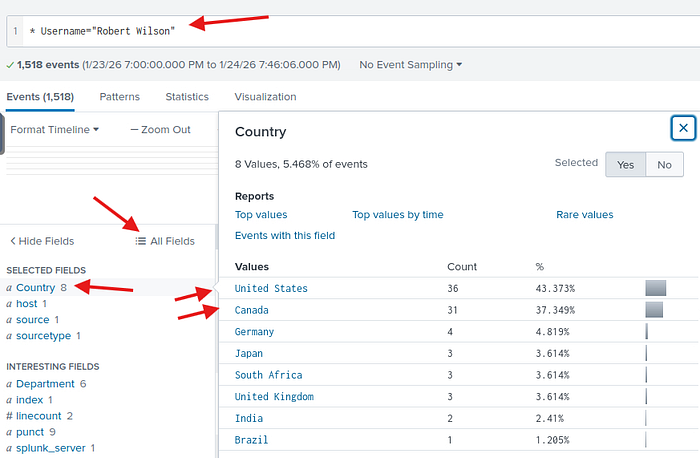
İşte karşımızda robert kullanıcısının erişmeye çalıştığı en yaygın ülkelerdeki ilk iki ülke. Canada ve United States
Soru12: Web sitesindeki secret-document.pdf dosyasına hangi kullanıcı erişti? Cevap: Sarah Hall
Direkt arayalım ve bakalım kimmiş.
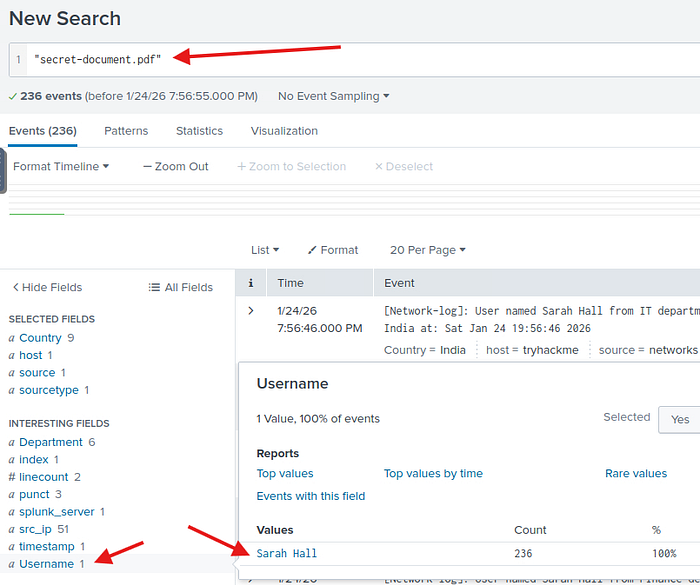
Böylelikle tüm soruların cevaplarına ulaşmış oluyoruz.
Bu bölümde, Splunk ile çalışırken karşılaşılan bozuk logların nasıl tamir edileceğini öğrendik. Standart log parsing mekanizması bazı logları yanlış parçalayabiliyor, bu da özellikle kullanıcı ve alan adı gibi kritik alanlara ulaşmayı engelliyor. Biz de:
- Parsingle ilgili temel kavramları hatırladık,
props.confiçindeBREAK_ONLY_BEFOREkullanarak logların doğru şekilde birleştirilmesini sağladık,- Parsinglemeden kaynaklı filtrenin yani Robert kullanıcısı için erişim loglarının eksik bilgilerini düzelttik,
- Böylece doğru country bilgisine ulaşarak sorunun cevabını bulduk.
Sonuç olarak, log yapısının doğru analiz edilmesi, sadece doğru regex veya Splunk araması yazmakla kalmıyor, aynı zamanda event'lerin doğru bölünüp birleştirilmesine de bağlı olduğunu öğrendik. Bu da Splunk'ta daha yüksek doğrulukla ve daha güçlü sorgularla çalışma olanağı sağlıyor.