
This post shares a real-world SSRF discovery, focusing on methodology and lessons learned, with all sensitive details intentionally removed.
The Initial Observation
At first, this didn't look exploitable:
- Arbitrary external URLs were blocked
- Common SSRF payloads failed
- Strict URL restrictions were in place
But the server's responses suggested something important: the header was influencing backend behavior.
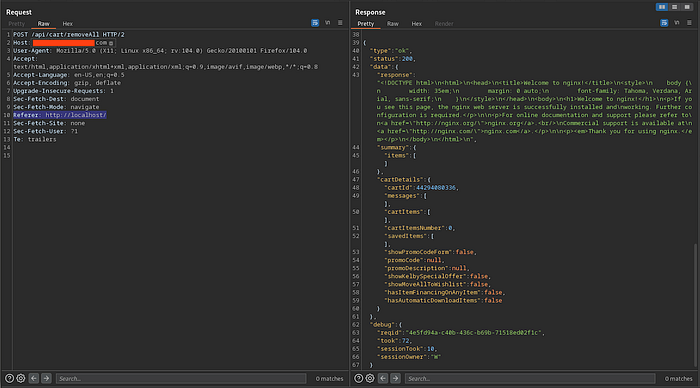
Confirming SSRF Behavior
To test this safely, I used loopback addresses:
Each resulted in a valid HTTP response code returned by the server. This confirmed that the backend was making server-side requests based on user-controlled input.
Even though external access was restricted, internal access was not.
Internal Exploration
Further testing showed that:
- Only port 80 was reachable over HTTP (default NGNIX page)
- Other ports did not respond
- An internal path (
/source) appeared to exist, but consistently returned a 500 Internal Server Error
This indicated internal endpoint exposure, even if the response itself was not readable.
Why This Still Matters
This was not a full SSRF with internet access, but it was still impactful:
- Internal services became reachable
- Application behavior was exposed
- Internal structure could be inferred
SSRF does not need immediate data leakage to be dangerous. Many high-impact vulnerabilities start with limited internal access and become critical later as systems evolve.
Root Cause & Takeaway
The core issue was simple:
The application trusted the
Refererheader.
Headers are user input. User input should never control backend requests without strict validation and isolation.
Key takeaway: If the server makes a request because of something the user controls — that's SSRF territory.