
- Part 1 of "The Missing Layer" — a series on architectural security for AI agents*
In the past three months, the evidence has become overwhelming — and consistent.
Researchers from OpenAI, Anthropic, and Google DeepMind tested 12 published AI defenses. Every defense claimed near-zero attack success rates. Under adaptive attacks, bypass rates exceeded 90% for most. Prompting-based defenses: 95–99%. Training-based: 96–100%. Filtering models: 71–94%.
Meanwhile, Microsoft's Copilot ignored sensitivity labels and DLP policies for four weeks, reading and summarizing confidential NHS emails while every security tool stayed silent. This was the second time in eight months.
OpenAI publicly acknowledged that prompt injection is "unlikely to ever be fully solved." Anthropic's Opus 4.6 shows 0% attack success rate in constrained environments — but 78.6% at 200 attempts in autonomous settings.
OpenClaw hit 180,000 GitHub stars in a week. Security researchers found 1,800+ exposed MCP servers with zero authentication. Infostealers added it to target lists within 48 hours.
These are not isolated incidents. They are the same pattern.
The Pattern
Every failure shares a structural cause: AI agents process trusted and untrusted data in the same cognitive space, with unmediated access to tools, memory, and external communication.
Aim Security described it precisely after the Copilot attack: agents process trusted and untrusted data in the same thought process, making them structurally vulnerable to manipulation.
Simon Willison calls it the "lethal trifecta": private data access + untrusted content exposure + external communication capability. When all three combine, exploitation becomes a matter of technique, not possibility.
The attack pattern is always the same. Raw input enters the agent's perception unmediated. The agent processes it as instruction. The agent acts on external systems. Damage is done before detection.
Copilot read confidential emails because data entered its retrieval pipeline. OpenClaw agents leaked SSH keys because emails were processed as instructions. MCP servers were weaponized because tools connected directly to agents without policy enforcement.
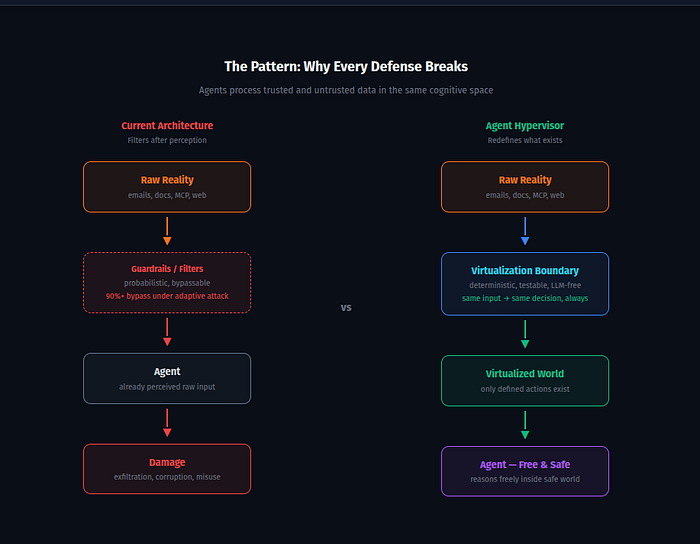
Every current defense — guardrails, prompt filters, output classifiers — operates *after* the agent has already perceived dangerous input. They ask: "Can agent X perform action Y?" and answer with a probabilistic runtime check.
The 12-defense study proved this question is architecturally insufficient. Given enough attempts, adaptive attackers bypass any probabilistic filter.
The Wrong Question and the Right One

The industry responds predictably: more detection, more monitoring, more filtering layers. The "AI Firewall" architecture — normalization, vector search, intent classification, PII redaction, context tracking on input; hallucination checks, canary tokens, schema validation on output — represents the current state of the art.
It's better than nothing. It's also fundamentally limited: every component is a probabilistic filter that an adaptive attacker can learn to bypass.
The question the industry keeps asking: "Can agent X perform action Y?"
The question that changes the architecture: "Does action Y exist in agent X's universe?"
This is the difference between permission security and ontological security. Between prohibiting an action by rule and removing it from existence by construction. Between a guard who might miss the intruder and a building where the room the intruder wants simply doesn't exist.
Classical hypervisors proved this distinction decades ago. A virtual machine cannot access physical memory — not because a rule forbids it, but because the MMU makes physical memory invisible. The VM is free inside its world. The world is safe by construction.
What This Means for Agent Security
If we apply this principle to AI agents:
**Instead of filtering inputs**, virtualize perception. The agent never receives raw text. It receives structured semantic events: source, trust level, capabilities, and sanitized payload. For the agent, "just text" does not exist.
**Instead of detecting malicious actions**, define the world. The agent can only propose intents — structured requests that the environment evaluates. Actions not in the world definition cannot be proposed.
**Instead of probabilistic enforcement**, use deterministic physics. Same input, same decision, always. No LLM on the critical security path. Unit-testable. Reproducible.
**Instead of hoping tainted data doesn't escape**, make exfiltration physically impossible. Data carries its origin as a property. Tainted data cannot cross external boundaries — not by rule, but by construction.
Microsoft's own Restricted Content Discovery already works this way for SharePoint: remove sensitive sites from Copilot's retrieval pipeline entirely, so the data never enters the context window. It works regardless of whether the violation comes from a code bug or a prompt injection — because the data doesn't exist in the agent's world.
RCD is a primitive version of what I'm calling Input Virtualization — applied ad hoc to one data source. The principle generalizes.
The Honest Weakness
There's a fundamental tension in this approach, and it must be stated plainly.
To create a structured semantic event from raw input, someone must understand that input. Understanding unstructured text is exactly what LLMs do. But LLMs are stochastic. The boundary layer needs intelligence, but intelligence is probabilistic.
Three specific problems follow. Parsing the boundary requires understanding semantic ambiguity. Taint propagation breaks on transformations — if an agent summarizes a tainted document, is the summary tainted? And defining the "world" is ultimately a design problem — someone must decide what actions exist.
The honest claim is not "ontologically impossible" but **bounded, measurable security** — deterministic within explicitly defined boundaries, with the boundaries themselves subject to human judgment and iteration.
This honesty matters. But the paradox has a resolution — and the resolution is a pattern the entire software industry already practices daily without naming it.
Next: AI Aikido: The Pattern Every Developer Uses Daily — Applied to Agent Security
I'm exploring these ideas in an open-source proof of concept: Agent Hypervisor
Personal analysis. Does not represent Radware's position.