
Hello hackers, Today I want to share a recent discovery that led to a critical Account Takeover (ATO) vulnerability on a popular platform. The bug required absolutely no user interaction and bypassed all authentication barriers.
A classic case of inconsistent Email Normalization, also known as Unicode Collision. Here is how a simple accent mark over a letter gave me a
What is Unicode Collision?
In simple terms, computers sometimes try to be "too smart." When you enter a character like ó (with an accent), the backend might apply a normalization process and downcast it to its closest ASCII equivalent, which is the normal English letter o.
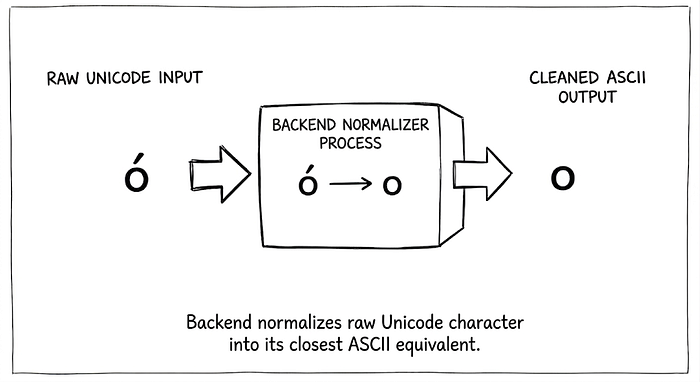
This sounds harmless, right? But what happens when the authentication logic normalizes the email for a database lookup, but the email delivery system does not? That's where the magic happens.
The target application X relies entirely on a passwordless login flow. You simply enter your email, grab the OTP sent to your inbox, and you are logged in.
Knowing this, I started wondering how their backend processes Internationalized Domain Names (IDNs) during this flow.
To test my theory, I set up a scenario targeting a user who is registered with the email victim@example.com. Instead of trying to bypass the OTP directly, I went to a domain registrar and bought a visually identical domain using a Unicode character. I registered exámple.com—notice the accent mark on the 'a'.
Under the hood, the internet sees this domain as a Punycode string (like xn--exmple-qta.com), but to the naked eye, it looks like the perfect trap.
With my malicious domain ready, I went to the target's login with OTP page and entered my spoofed email address: victim@exámple.com.
What happened next behind the scenes is exactly what makes this bug so dangerous.
First, the application's session logic took my input and passed it through its normalization function. It stripped the accent mark, turning my input into the legitimate victim@example.com. It then searched the database, successfully found the victim's account, and happily generated a valid OTP.
But here is the fatal flaw: the email delivery service did not use that normalized version. It grabbed the raw input I originally provided. So, instead of sending the login code to the victim, the system dispatched the OTP straight to victim@exámple.com—which forwarded right into my attacker inbox.
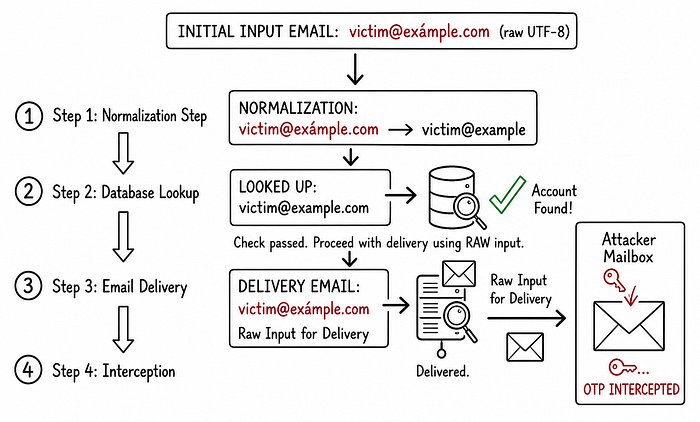
Once I received the OTP in my inbox, I entered it on the login page and was instantly logged into the victim's account. I had full access to all their private data. Since the app only relied on OTP, I could also change their primary email and lock them out permanently.
But it gets worse.
The target company also has connected assets (like a secondary app) that use a "Log in with X" Single Sign-On (SSO) feature.
Because I had full control over the main account, I simply clicked "Log in" on the secondary app and gained access there too. The most critical part is The secondary app allowed immediate, permanent deletion of the account with just two clicks, without asking for any further email verification.
Like most hunters, my default setup is Firefox routed through Burp Suite. In this environment, sending the raw UTF-8 payload (ó) happens naturally, and the exploit worked perfectly.
However, I tried reproducing the flow in Chrome and noticed the attack failed. Because Chromium-based browsers automatically convert IDN characters to Punycode (xn--...) client-side before the request even leaves the browser. If the server receives Punycode instead of the raw Unicode character, the normalization step never occurs.
I made sure to highlight this caveat in my report so the triager wouldn't get a false negative.
