June 6, 2026
Case Study: TARmageddon — CVE-2025–62518 and the Supply Chain Nightmare in Rust’s Async TAR…
Rust is memory-safe. Your supply chain may not be.

Ajay Kumar
10 min read
Rust is memory-safe. Your supply chain may not be.
Rust has built a strong reputation around memory safety. It eliminates entire categories of bugs that are common in C and C++: use-after-free, double free, buffer overflows, and many forms of undefined behavior.
But CVE-2025–62518, also known as TARmageddon, is a painful reminder that not every serious vulnerability is a memory-safety vulnerability.
This bug was not about unsafe pointers. It was not about heap corruption. It was not about a classic buffer overflow.
It was a parser logic bug.
And in modern backend systems, package managers, container tools, build pipelines, and CI/CD workflows, parser logic bugs can become supply chain vulnerabilities.
TARmageddon affected Rust's async TAR ecosystem, especially libraries descended from async-tar and tokio-tar. The issue was publicly disclosed in October 2025 and tracked as CVE-2025-62518. The GitHub advisory gives it a CVSS 3.1 score of 8.1 High, with network attack vector, low attack complexity, no privileges required, and user interaction required.
What happened?
TARmageddon is a vulnerability in TAR archive parsing. Specifically, affected parsers handled PAX extended headers and ustar headers inconsistently.
The short version:
A TAR archive can contain metadata in a PAX extended header. One of those metadata fields can override the file size. In vulnerable async Rust TAR parsers, the parser could read the PAX size correctly in one part of the code but still calculate the next archive boundary using the old ustar size field, often 0. That caused the parser to move to the wrong place in the stream and interpret file content as if it were another TAR header.
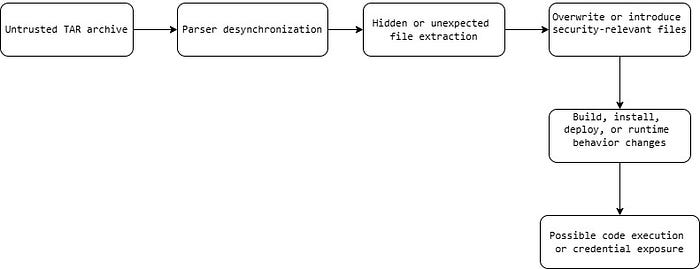
That means one TAR parser could see a harmless archive, while the vulnerable parser could extract extra hidden entries.
This is the dangerous part: security tools, package scanners, or validation systems may approve what they think is inside the archive, while the vulnerable extraction path may unpack something different.
That is the core nightmare.
Why this matters for supply chain security
TAR archives are everywhere.
They appear in source distributions, package managers, container layers, backup systems, build artifacts, deployment bundles, and test frameworks. A backend engineer may not think about TAR parsing daily, but many developer tools process archives silently in the background.
Edera's disclosure described possible impact scenarios such as file overwriting attacks, build backend hijacking, container image poisoning, and bill-of-materials bypasses. The same disclosure mentioned downstream projects such as uv, testcontainers, and wasmCloud as examples of affected ecosystem exposure.
This does not mean every project using one of these libraries was automatically exploitable. Real exploitability depends on how the library is used. The risk becomes serious when an application extracts untrusted TAR files into a filesystem location that can influence builds, configuration, credentials, dependencies, or runtime behavior.
In other words, TARmageddon is not "Rust is insecure."
It is:
Rust can prevent memory corruption, but it cannot automatically prevent semantic confusion in complex file formats.
Affected ecosystem
The official NVD entry focuses on astral-tokio-tar versions before 0.5.6, describing the bug as a boundary parsing vulnerability involving inconsistent PAX/ustar header handling. The issue is patched in astral-tokio-tar version 0.5.6.
RustSec also tracks this as RUSTSEC-2025–0110 for astral-tokio-tar, marking versions before 0.5.6 as vulnerable.
The broader ecosystem concern comes from the lineage of related crates. RustSec separately tracks RUSTSEC-2025–0111 for tokio-tar, explaining that tokio-tar incorrectly parses PAX extended headers and can present different content compared with other TAR readers. RustSec states that tokio-tar has no patched versions and recommends switching to an alternative such as astral-tokio-tar.
A simplified affected-family view:

The important engineering lesson is not only "upgrade one crate." It is that forks, abandoned dependencies, and transitive dependencies can keep vulnerable parser logic alive long after the original code stops receiving attention.
The technical root cause
To understand TARmageddon, we need to understand a TAR archive at a high level.
A TAR file is a sequence of records. Each file entry normally has:
Header -> File content -> Padding -> Next headerHeader -> File content -> Padding -> Next headerThe parser reads the header, determines the file size, skips the file content and padding, then expects the next header.
But TAR has extensions. One important extension is the PAX extended header, which can carry metadata that overrides fields from the normal ustar header.
Correct behavior should look like this:
PAX header says: size = N
ustar header says: size = 0
Parser should use effective size = N
Parser should skip N bytes of content
Parser should read the next real header after N bytesPAX header says: size = N
ustar header says: size = 0
Parser should use effective size = N
Parser should skip N bytes of content
Parser should read the next real header after N bytesThe vulnerable behavior looked conceptually like this:
PAX header says: size = N
ustar header says: size = 0
Parser uses ustar size = 0 for stream position
Parser skips 0 bytes
Parser starts reading inside file content
File content is misinterpreted as TAR headersPAX header says: size = N
ustar header says: size = 0
Parser uses ustar size = 0 for stream position
Parser skips 0 bytes
Parser starts reading inside file content
File content is misinterpreted as TAR headersThe GitHub advisory describes exactly this kind of mismatch: the PAX header specifies a non-zero size, the ustar header incorrectly specifies zero, and the parser advances using the ustar value, causing inner content to be interpreted as legitimate outer archive entries.
This is a desynchronization bug.
The parser loses agreement with the actual structure of the archive. Once that happens, the attacker-controlled file body can be treated as metadata.
That is how "data" becomes "structure."
And when data becomes structure, security boundaries often collapse.
Vulnerable logic, simplified
A vulnerable implementation pattern can be represented like this:
// Simplified vulnerable logic
let file_size = header.size()?; // reads size from ustar header
let next_header_position =
current_position + 512 + pad_to_512(file_size);
// Problem:
// If a PAX header already overrode the real size,
// but this calculation still uses the ustar size,
// the parser advances to the wrong location.// Simplified vulnerable logic
let file_size = header.size()?; // reads size from ustar header
let next_header_position =
current_position + 512 + pad_to_512(file_size);
// Problem:
// If a PAX header already overrode the real size,
// but this calculation still uses the ustar size,
// the parser advances to the wrong location.The bug is not that this code is memory unsafe.
The bug is that it trusts the wrong source of truth.
In formats with multiple metadata layers, there must be one canonical "effective value" used everywhere. If one part of the parser uses PAX metadata, while another part uses stale ustar metadata, the parser becomes internally inconsistent.
A safer pattern is:
// Simplified fixed logic
let mut effective_size = header.size()?;
// Apply PAX override before any boundary calculation
if let Some(pax_size) = pending_pax.get("size") {
effective_size = parse_and_validate_size(pax_size)?;
}
// Use the same effective size consistently
let next_header_position =
current_position + 512 + pad_to_512(effective_size);// Simplified fixed logic
let mut effective_size = header.size()?;
// Apply PAX override before any boundary calculation
if let Some(pax_size) = pending_pax.get("size") {
effective_size = parse_and_validate_size(pax_size)?;
}
// Use the same effective size consistently
let next_header_position =
current_position + 512 + pad_to_512(effective_size);The key fix is not merely "parse PAX." The key fix is:
Apply PAX overrides before calculating archive boundaries, and validate that the parser's view of the stream remains consistent.
The official advisory describes the fixed logic as applying PAX overrides before position calculation.
Why this can become RCE
A parser differential alone is not always remote code execution.
But it becomes dangerous when extracted files influence execution.
For example:
A package manager downloads a source archive. A scanner sees a safe pyproject.toml. But a vulnerable extraction path unpacks a different or overwritten build configuration. Now the build system may execute attacker-controlled build logic.
Or a CI system downloads a TAR artifact. A validation step sees one set of files. The extraction step writes another set. If those files include scripts, config files, credentials, hooks, or build definitions, the attacker may influence execution.
Or a container-related tool processes image layers. A parser confusion bug causes unexpected files to appear in the extraction result. If those files affect later scanning, testing, or execution, the result may be container poisoning or policy bypass.
Edera's write-up explicitly describes scenarios including Python build backend hijacking, container image poisoning, and BOM/manifest bypass.
That is why TARmageddon is best understood as a supply chain parser differential vulnerability.
The RCE is not magic. The chain looks like this:
Why uv impact was considered lower
One interesting part of this case is that the downstream impact can vary.
The uv advisory says versions 0.9.4 and earlier did not properly handle TAR archives containing PAX size overrides, and that an attacker could craft a source distribution that extracts differently with uv than with other Python package installers. However, the advisory rates the practical impact as low because Python source distributions can already execute arbitrary code at build or installation time by design. uv patched the issue in version 0.9.5.
This is an important nuance.
A vulnerability can be severe in a library, but lower impact in a specific downstream application if the application already has a broader trust boundary.
For backend engineers, this is a valuable lesson:
CVE severity is not the same as your application severity.
You must evaluate where the vulnerable code runs, what input it processes, what files it writes, and whether extracted content can influence execution.
Safe local reproduction idea
For a defensive security article, you do not need to teach readers how to weaponize the bug. The safer approach is to reproduce the parser differential in a controlled environment.
A good educational reproduction should only prove this:
A correct TAR parser sees:
normal.txt
blob.bin
marker.txt
A vulnerable TAR parser sees:
normal.txt
blob.bin
INNER_FILE
marker.txtA correct TAR parser sees:
normal.txt
blob.bin
marker.txt
A vulnerable TAR parser sees:
normal.txt
blob.bin
INNER_FILE
marker.txtThe official reproduction repository explains that correct libraries such as GNU tar and the synchronous Rust tar crate see the expected file list, while buggy libraries such as tokio-tar may incorrectly expose an extra inner file.
A safe regression test can be written around the invariant:
#[tokio::test]
async fn pax_size_override_must_not_expose_inner_entries() {
let entries = list_entries_with_parser("fixtures/pax_size_desync.tar")
.await
.expect("archive should parse");
assert!(entries.contains(&"normal.txt".to_string()));
assert!(entries.contains(&"blob.bin".to_string()));
assert!(entries.contains(&"marker.txt".to_string()));
// Defensive invariant:
// file content must never be treated as archive structure
assert!(!entries.contains(&"INNER_FILE".to_string()));
}#[tokio::test]
async fn pax_size_override_must_not_expose_inner_entries() {
let entries = list_entries_with_parser("fixtures/pax_size_desync.tar")
.await
.expect("archive should parse");
assert!(entries.contains(&"normal.txt".to_string()));
assert!(entries.contains(&"blob.bin".to_string()));
assert!(entries.contains(&"marker.txt".to_string()));
// Defensive invariant:
// file content must never be treated as archive structure
assert!(!entries.contains(&"INNER_FILE".to_string()));
}The purpose of this test is not to exploit anything.
The purpose is to guarantee that parser state remains synchronized with the real archive boundary.
What should Rust backend engineers do?
First, audit your dependency tree.
cargo tree -i tokio-tar
cargo tree -i astral-tokio-tar
cargo tree -i async-tarcargo tree -i tokio-tar
cargo tree -i astral-tokio-tar
cargo tree -i async-tarThen run security advisory checks:
cargo auditcargo auditFor stricter policy enforcement, use cargo-deny:
cargo deny check advisoriescargo deny check advisoriesIn CI/CD, make advisory checks mandatory. A GitHub Actions job can fail the build if a vulnerable crate appears in the dependency graph.
Example:
name: Rust Security Checks
on:
pull_request:
push:
branches: [ main ]
jobs:
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install cargo-audit
run: cargo install cargo-audit
- name: Run cargo audit
run: cargo audit
- name: Install cargo-deny
run: cargo install cargo-deny
- name: Run cargo deny
run: cargo deny check advisoriesname: Rust Security Checks
on:
pull_request:
push:
branches: [ main ]
jobs:
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install cargo-audit
run: cargo install cargo-audit
- name: Run cargo audit
run: cargo audit
- name: Install cargo-deny
run: cargo install cargo-deny
- name: Run cargo deny
run: cargo deny check advisoriesFor tokio-tar, RustSec says there are no patched versions and recommends switching to an alternative such as astral-tokio-tar. For astral-tokio-tar, upgrade to 0.5.6 or newer.
Production-grade mitigation strategy
Upgrading is necessary, but it should not be your only control.
A production-grade system should treat archive extraction as dangerous, especially when input is untrusted.
A strong mitigation strategy includes:
Never extract untrusted archives directly into important directories
Do not extract into your workspace root, deployment directory, $HOME, /etc, /usr/local/bin, or any location that influences execution.
Use a temporary isolated directory.
Use path normalization and path traversal protection
Reject entries containing:
../
absolute paths
Windows drive paths
symlinks escaping the extraction root
hard links escaping the extraction root../
absolute paths
Windows drive paths
symlinks escaping the extraction root
hard links escaping the extraction rootScan after extraction, not only before extraction
TARmageddon shows why pre-extraction scanning can be insufficient. If the extraction parser sees different content from the scanner, your control is bypassed.
A safer flow:
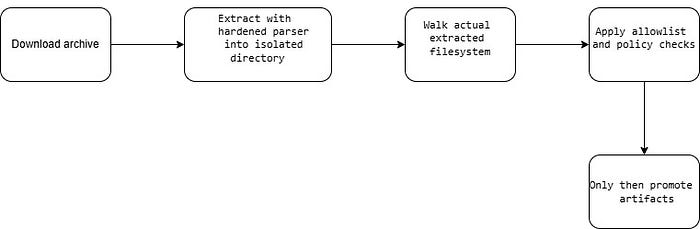
For high-risk environments, run archive extraction inside a container, VM, seccomp profile, or restricted user namespace.
Avoid abandoned parser dependencies
A parser library is security-sensitive infrastructure. If the crate is unmaintained, archived, or has no security contact, treat that as a risk signal.
Add parser differential tests
Compare your chosen parser against a mature reference parser for edge cases:
PAX headers
long file names
large files
zero-size fields
nested archive-like content
symlinks
hard links
sparse files
weird paddingPAX headers
long file names
large files
zero-size fields
nested archive-like content
symlinks
hard links
sparse files
weird paddingPin and review transitive dependencies
Many teams only review direct dependencies. TARmageddon is a reminder that transitive dependencies can be the real blast radius.
Why this bug is important for Rust interviews
This case study is excellent for senior Rust/backend interviews because it tests real engineering judgment.
A strong candidate should not merely say:
Rust is memory-safe, so this should not happen.
A strong candidate should say:
Rust prevents many memory safety vulnerabilities, but parser logic, file format ambiguity, trust boundaries, supply chain workflows, and unmaintained dependencies still require explicit security design.
Interview discussion questions:
1. Why did Rust not prevent this vulnerability?
Because the bug was a semantic parser bug, not memory corruption. The code could be memory-safe but still logically wrong.
2. What is a parser differential?
A parser differential happens when two parsers interpret the same input differently. In security-sensitive workflows, this can allow attackers to pass validation in one parser and trigger dangerous behavior in another.
3. Why are archives dangerous?
Archives can write many files, preserve paths, include metadata, contain symlinks or hard links, and influence build or runtime behavior after extraction.
4. Why can file overwrite lead to RCE?
If an attacker can overwrite build files, package metadata, scripts, config files, or plugin definitions, the system may execute attacker-controlled code during build, install, test, or startup.
5. What is the best mitigation?
Upgrade vulnerable crates, remove unmaintained dependencies, sandbox extraction, validate actual extracted output, and enforce advisory checks in CI.
Backend engineering lesson
The biggest lesson from TARmageddon is this:
Safe languages reduce memory bugs. They do not remove the need for secure design.
Rust gives us ownership, lifetimes, type safety, and fearless concurrency. But it cannot decide which metadata field should be authoritative in a complex archive format.
That is still the engineer's responsibility.
A production backend engineer must think beyond code compilation:
Where does this input come from?
Who controls it?
What parser processes it?
Can different parsers disagree?
Where do extracted files go?
Can extracted files influence execution?
Is the dependency maintained?
Will CI catch vulnerable transitive crates?Where does this input come from?
Who controls it?
What parser processes it?
Can different parsers disagree?
Where do extracted files go?
Can extracted files influence execution?
Is the dependency maintained?
Will CI catch vulnerable transitive crates?This is the difference between writing Rust code and engineering secure Rust systems.
Production checklist
Before using any TAR library in a Rust backend, ask:
[ ] Do we process untrusted TAR files?
[ ] Do we extract archives or only list entries?
[ ] Are we using tokio-tar, async-tar, astral-tokio-tar, or a fork?
[ ] Is the crate actively maintained?
[ ] Have we run cargo audit?
[ ] Have we run cargo deny?
[ ] Do we reject path traversal entries?
[ ] Do we handle symlinks and hard links safely?
[ ] Do we extract into an isolated temporary directory?
[ ] Do we scan the actual extracted result?
[ ] Do we compare parser behavior against a reference parser?
[ ] Do we have regression tests for PAX headers?
[ ] Do we sandbox archive extraction?
[ ] Do we fail CI on vulnerable dependencies?[ ] Do we process untrusted TAR files?
[ ] Do we extract archives or only list entries?
[ ] Are we using tokio-tar, async-tar, astral-tokio-tar, or a fork?
[ ] Is the crate actively maintained?
[ ] Have we run cargo audit?
[ ] Have we run cargo deny?
[ ] Do we reject path traversal entries?
[ ] Do we handle symlinks and hard links safely?
[ ] Do we extract into an isolated temporary directory?
[ ] Do we scan the actual extracted result?
[ ] Do we compare parser behavior against a reference parser?
[ ] Do we have regression tests for PAX headers?
[ ] Do we sandbox archive extraction?
[ ] Do we fail CI on vulnerable dependencies?For TARmageddon specifically:
[ ] Upgrade astral-tokio-tar to >= 0.5.6
[ ] Upgrade uv to >= 0.9.5 if relevant
[ ] Remove or replace tokio-tar where possible
[ ] Investigate transitive dependencies using cargo tree
[ ] Add regression tests for PAX size override behavior[ ] Upgrade astral-tokio-tar to >= 0.5.6
[ ] Upgrade uv to >= 0.9.5 if relevant
[ ] Remove or replace tokio-tar where possible
[ ] Investigate transitive dependencies using cargo tree
[ ] Add regression tests for PAX size override behaviorFinal takeaway
TARmageddon is one of those vulnerabilities that looks small at first:
The parser used the wrong size field.
But that small mistake changes the security meaning of an archive.
One parser sees safe files.
Another parser extracts hidden files.
A scanner approves one reality.
The build system executes another.
That is why CVE-2025–62518 matters.
It teaches Rust engineers that secure backend engineering is not only about avoiding unsafe. It is about understanding formats, trust boundaries, supply chains, abandoned dependencies, parser differentials, and CI/CD enforcement.
Rust is a powerful tool.
But secure systems still require paranoid engineering.
Want to Learn Production Rust with Real Projects and CVE Case Studies?
I have created a complete Rust Backend Engineering Learning Material for developers who want to master Rust for real backend systems.
It includes production-grade Rust projects, Axum, Tokio, PostgreSQL, Docker, testing, deployment, and deep Rust CVE case studies like this one.
You can check it here:
👉 Get the Complete Rust Backend Engineering Bundle here: https://tobiweissmann.gumroad.com/l/gnuvxu