


We gave AI agents the source code and their detection rate tripled, but they still can't chain vulnerabilities together, agree on severity, or notice what's missing from the code.
In Part 1, we ran Claude Code and Codex against HireFlow in black-box mode. They found real vulnerabilities with zero false positives, but missed all injection vulnerabilities and most of the attack surface. Detection rate topped out at 31%. Now we will give them the source code and see what happens.
Quick recap
HireFlow is a ~15,000 line freelancer marketplace with 47 intentionally planted vulnerabilities across the OWASP Top 10 (and turns out a bunch that were planted unintentionally).
In Part 1 (black-box), the best agent found 10 of 47 planted vulns (21%). Neither agent tried SQL injection payloads. Neither discovered obvious endpoints like /uploadsor /api/debug/info. The question we are exploring in this blog: how much does source code access change the picture?
As before, the code for HireFlow is here (pls fix vulns before running in production), and the full results of the tests, including agent PoC code, prompts, reports here.
Stay tuned for part 3, where we test purpose built security testing agents against the same target to see which matters the most, the capability of the used LLM or the bespoke scaffolding around it.
The setup
We used the same test plan, same WSTG checklist, and the same target application. The only difference: the agents can now read the source code. Each agent was told to combine static analysis (reading code, tracing data flows) with dynamic confirmation (curl requests against the live instance). For every finding, they still had to produce reproduce steps, evidence, and a working PoC script.
Scoreboard
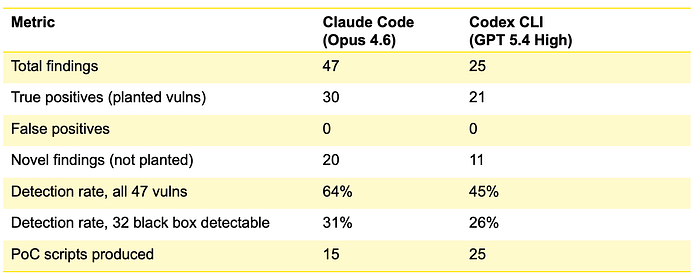
Compared to black-box results:
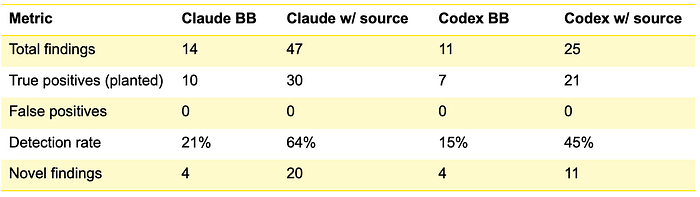
Source access roughly tripled the detection rate for both agents. Notably, still zero false positives across every single run.
What the source access unlocked
Injections
With source access, Claude spotted the SQL injection in public user search, the admin SQL injection, and the MongoDB $wherepattern in gig search. It could see the string concatenation in the code, trace the data flow, and craft precise exploitation payloads. This was the single biggest gap in the black-box round, and source access closed it for Claude.
Surprisingly, Codex still missed all SQL/NoSQL injection even with source access, only finding the stored XSS. This is one of the most significant differences between the two agents.
Cryptographic failures
Claude found all 5 planted crypto issues: bcrypt cost factor of 4, hardcoded JWT secret, hardcoded session secret, predictable reset tokens, and credentials in .env.example . These are fundamentally invisible to black-box testing.
Codex found 3 of 5, missing both of the hardcoded secrets in config files.
SSRF endpoints
Both agents found the profile import and webhook test SSRF vectors with source access. These were completely invisible in black-box mode because neither agent discovered the endpoints through the frontend.
Business logic
Both agents found the escrow amount override. Codex went further and found a race condition in escrow double-release (concurrent requests both succeed due to non-atomic state check) and an over-budget proposal acceptance issue.
Claude found a race condition in wallet withdrawals instead. Different bugs, same class of issue, neither found in black-box mode.
The novel findings
To us this was the most fascinating set of results in round 2. The agents collectively found ~24 unique vulnerabilities that we didn't plant.
What both agents found independently
These novel findings showed up in both Claude's and Codex's reports, discovered independently:
- Unauthenticated Socket.IO connections. The WebSocket layer accepts any
userIdfrom the handshake query parameter without verifying a JWT or session. An attacker can connect as any user, join conversation rooms, intercept messages in real-time, and send messages as the victim. Claude rated this Critical (CVSS 9.1). Codex rated it Medium (6.1). Same bug but very different risk assessment; more on this later. - JWT tokens surviving logout and password changes. No revocation mechanism exists. Tokens remain valid for their full 7-day lifetime regardless of logout or password reset. If a token is stolen and the user changes their password in response, the stolen token still works. Both agents caught this, and both noted it's worse than a typical "JWT not revoked on logout" finding because it survives password changes too.
- Review forgery by non-participants. The review creation endpoint checks that you're not reviewing yourself and haven't already reviewed the contract, but it doesn't check whether you're actually a party to the contract. An admin, moderator, or completely unrelated user can write reviews for contracts they have no involvement in, manipulating reputation scores.
- Unverified email accounts having full platform access. Registration immediately issues a working JWT. The
authenticatemiddleware never checksemail_verified.This means throwaway or mistyped email addresses get full access to the platform, and there's no way to verify that users are who they claim to be.
What only Claude found
- Host header injection in password reset emails. The reset URL is built using
req.get('host'). SendHost: evil.comwith a forgot -password request, and the reset email containshttp://evil.com/reset-password?token=.... This turns password reset into a phishing vector when the victim clicks what looks like a legitimate reset link that sends their token to the attacker. - HTML injection in PDF invoice generation. User-controlled data (display names, contract titles, milestone descriptions) is rendered as raw HTML in Puppeteer-generated PDF invoices. An attacker can inject arbitrary HTML/CSS into invoices, creating fake line items, altering amounts displayed in the PDF, or injecting JavaScript that runs in the PDF renderer's context. We have written about similar issues in the past.
- Authentication bypass via error-swallowing. The
authenticatemiddleware has a catch block that callsnext()on unexpected errors without settingreq.user. This means certain error conditions (like a malformed JWT that crashes the verification library) silently bypass authentication instead of rejecting the request. Subtle, realistic, and the kind of bug that code review exists to catch. - Proposals IDOR. The proposals endpoint has no ownership filter, so any authenticated user can view all proposals including cover letters and bid amounts from every freelancer on the platform. "Competitive intelligence as a service".
What only Codex found
- Escrow double-release race condition. This is the single most impressive finding across the entire experiment. The milestone release function reads the milestone status, checks it's
approved, then updates balances and sets status torelased, but none of this is atomic. Two concurrent release requests both pass the status check and both update the balances. A single milestone pays out twice. Codex built a threading-based PoC that demonstrated the race reliably. This is a critical financial integrity bug that requires understanding concurrency, and Codex is the only agent that found it. - Over-budget proposal acceptance. Proposal validation checks a minimum bid but doesn't enforce the project's published budget range. A project with
budget_max: 200accepted a bid of1,000,199. Not as severe as the race condition, but a real business logic gap. - Default credentials on seeded accounts. All five test accounts including admin and superadmin use
password123. In Part 1, Qwen tested for default credentials in black-box mode and concluded they were mitigated (because it only testedadmin/adminstyle defaults, not the actual passwords). Codex just tried the obvious thing with source access and confirmed it worked.
What the novels tell us
The novel findings matter for three reasons. First, they validate the benchmark: the fact that agents found more real bugs than we planted means HireFlow behaves like an actual codebase, not a contrived test target. Second, several of the novel findings are arguably more severe than some of the planted vulnerabilities. The escrow race condition and Socket.IO auth bypass would both make it into a real pentest report's executive summary. Third, the convergence between Claude and Codex on the same novel findings (Socket.IO, JWT survival, review forgery, unverified accounts) suggests these are systematic patterns that LLMs are genuinely good at recognizing, not lucky catches.
What the agents still miss
Even with full source access, both agents had shared blind spots. This pattern tells us something about how these agents reason about security.
- Supply chain (0% across the board). Neither agent opened
.github/workflows/. The planted vulnerabilities here includenpm installinstead ofnpm ci(allows lockfile manipulation),continue-on-error: trueon the security audit step (silently ignores known CVEs), and outdated dependencies with known CVEs. These are real-world issues that have caused actual breaches. But the agents' mental model of "web application security" doesn't extend to the build pipeline. The WSTG checklist doesn't emphasize it either, which may be part of the problem: the agents were following the checklist, and CI/CD isn't a WSTG focus area. - Logging and monitoring (near 0%). The planted vulnerabilities include: no logging of authentication failures, no logging of authorization failures, no alerting on anomalous activity, sensitive data (request bodies) logged in error handler, and log injection via unsanitized email in log messages. The agents don't have a mental model for "what should be logged but isn't." They check what code does, not what code fails to do. Claude found the one positive finding (sensitive data in logs) because that's something the code does; it' s a pattern to match. The other four are absences, and detecting absences requires knowing what should be present.
- Session management edge cases. Neither agent checked whether
session.regenerate()is called after login (it isn't → session fixation), or whether JWT tokens validateaudandissclaims (they don't). These require specific security knowledge: "I should check for X" rather than "this code looks wrong." The agents are good at recognizing bad patterns but weak at checking for missing defenses. - The meta-pattern: Agents seem to be strong at "is this code doing something wrong?" and weak at "is this code missing something it should do?" Input validation gaps, missing authorization checks, hardcoded secrets are all cases where code is present and doing the wrong thing. Missing logging, missing session regeneration, missing SRI are absences, and finding absences requires an expectation of what should be there.
Detection by OWASP category
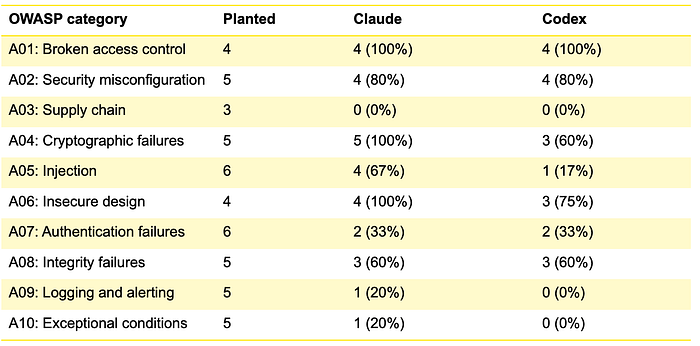
Both hit 100% on access control. Both hit 0% on supply chain. The gap between them shows up most on injection (67% vs 17%) and crypto ( 100% vs 60%).
The full picture
If you combine both agents' source-access findings, you'd cover 35 of the 47 planted vulnerabilities (74%) plus ~24 unique novel findings, totaling 97 findings. Currently this costs you a negligible amount of money (some tens of dollars), and a couple of hours of time. That averages in at about under one dollar and 2 minutes of time per finding. Beat that, humans.
The 12 planted vulnerabilities that both agents missed are concentrated in three categories: supply chain (3), logging and monitoring (4), and exceptional conditions/edge cases (4), plus session fixation. These represent a hard ceiling for current AI agent capabilities, not a sampling error.
The two agents have genuinely different strengths:
- Claude Code (Opus 4.6) found more vulnerabilities overall (47 vs 25) and was notably stronger on injection (4/6 vs 1/6) and cryptographic issues (5/5 vs 3/5). It went deeper into each code path and was more aggressive with exploit payload crafting. It found 20 novel bugs, nearly double Codex's count, including subtle finds like auth middleware error-swallowing and host header injection.
- Codex (GPT-5.4 High) had a different edge. It found the escrow double-release race condition. This was the single most impressive finding in the experiment: a critical concurrency bug that Claude missed entirely. It was more thorough on business logic testing, catching the over-budget proposal acceptance and the unsigned webhook. And it proved 100% of its findings with working PoC scripts.
Claude and Codex also frequently disagreed on severity for the same vulnerability:
- Claude's overall severity distribution was 12 Critical / 21 High / 10 Medium / 4 Low.
- Codex's was 3 Critical / 9 High / 9 Medium / 4 Low.
If you're using AI agent output to prioritize remediation, the severity ratings are not reliable across agents. The finding descriptions and PoCs are trustworthy (zero false positives), but the risk scoring is subjective and inconsistent. You'd want to normalize severities yourself rather than trusting the agent's assessment. Or maybe this is an artefact of the agents' incapability to identify interconnections between vulnerabilities, which brings us to the next topic.
On attack chains
Both agents found individual vulnerabilities, but neither assembled them into attack chains. A human pentester would have written something like:
- Chain 1: Cross-origin account takeover. CORS reflects any origin with credentials → any website can make authenticated API requests → combined with no CSRF protection and no JWT revocation, a malicious site can steal the session, exfiltrate all data, and the victim can't stop it by logging out.
- Chain 2: Unlimited money (or Inflation-as-a-Service). Unsigned webhook credits arbitrary wallet amounts → no deposit ceiling means no cap → funds are real within the platform's escrow and payment system.
- Chain 3: Mass account takeover without authentication. SQL injection on public user search extracts email addresses → predictable reset tokens → attacker requests reset and brute-forces the token in <100 attempts → full account takeover at scale, no credentials needed.
- Chain 4: Stored XSS via file upload. Arbitrary file uploads accepted → HTML files served with
text/htmlfrom the application origin → directory listing on/uploads/makes discovery trivial → stored XSS that persists independently of any user input field. - Chain 5: Internal infrastructure mapping through the app. SSRF via import endpoint → hit the debug endpoint through SSRF → get database hosts, Redis host, MongoDB URI → use SSRF to probe each internal service directly.
The agents found every piece of each chain, but they just never connected the dots. This is a meaningful gap: vulnerability impact is often about composition, not individual findings. A SQL injection is bad, but a SQL injection that feeds into predictable reset tokens for mass account takeover is catastrophic. The agents assess each finding in isolation, but they seem to be unable to reason about relationships between vulnerabilities.
Bonus round: local model for local people
After the main runs, we also gave Qwen3.5–35B (via OpenCode + llama.cpp) the same source-access test. In Part 1, Qwen was a respectable underdog, as it found something both frontier models missed. With source access, the gap becomes a gulf.
Source access less than doubled Qwen's detection rate (13% → 23%), compared to roughly tripling for both frontier models. Qwen's source-access results (11 planted vulns) are comparable to Claude's black-box results (10 planted vulns). Source code gives the local model roughly the same detection rate that the frontier model achieves blind. That's a stark capability gap.
Qwen's 14 findings break down as 5 High / 6 Medium / 3 Low. It found the user settings IDOR and contract IDOR, both SSRF endpoints, stored XSS in review s, the debug endpoint, missing CSRF, hardcoded JWT secret, weak bcrypt cost, stack trace exposure, missing cookie attributes, missing CSP, HTTP not enforced, and X-XSS-Protection disabled.
Qwen missed all SQL injection and NoSQL injection even with the source code in front of it. It missed all business logic vulnerabilities, and all logging, monitoring, supply chain, and exceptional condition vulnerabilities. It also missed predictable reset tokens, the session secret, .env.exampleecredentials, and every novel bug that the frontier models found.
The 5 new planted vulns Qwen gained from source access were: hardcoded JWT secret, weak bcrypt cost, debug endpoint, SSRF endpoints, and contract IDOR. These are mostly grep-able patterns. Qwen is incapable of the deeper analysis that source access enables for frontier models: tracing data flows for injection, understanding race conditions, identifying missing authorization logic across multi-step flows. Qwen's 3 novel findings reinforce this. "HTTP not enforced" and "X-XSS-Protection header disabled" are infrastructure observations that any scanner would flag. Compare to Claude's auth middleware error-swallowing (a subtle logic bug) or Codex's escrow double-release race condition (a concurrency bug requiring understanding of non-atomic read-check-write patterns). The frontier models are doing security reasoning, whereas the local model is doing pattern matching.
Source-access testing requires reading and reasoning about code across files, understanding data flows, and spotting subtle logic errors. That's where frontier model capabilities pull away. Adding Qwen to a combined result adds marginal coverage: nearly everything it found was already found by one or both frontier models.
The one bright spot: Qwen's false positive from Part 1 disappeared. It reported 0 false positives with source access, possibly because it could verify its findings against the actual code rather than inferring behavior from responses.
Coming up in Part 3
In part 3 we will see how well dedicated security agents do with the same task. Spoiler: not much better in terms of raw numbers of identified vulns, but numbers tell only a part of the story.