
AI Workforce magazine — Data Center Basics
Understand the entire data center ecosystem well enough to diagnose incidents, and make decisions quickly.
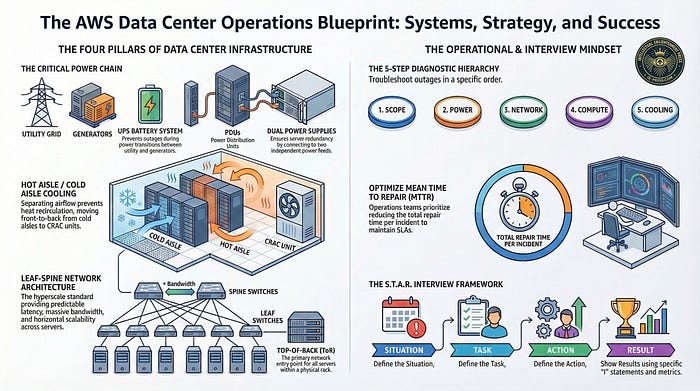
Below is a structured knowledge outline that reflects what Data Center operations managers are expected to understand.
1. Data Center Infrastructure Fundamentals
You must understand the four physical systems that keep a data center running.
Power Infrastructure
Key concepts:
- utility power feeds
- generators
- UPS (Uninterruptible Power Supply)
- PDUs (Power Distribution Units)
- rack-level PDUs
- A/B power redundancy
Typical power path:
Utility → UPS → PDU → Rack PDU → Servers
What you must know:
- how redundancy works
- what happens when power fails
- how racks draw power (kW per rack)
- basic electrical safety
Cooling Systems
Key components:
- CRAC / CRAH units
- chilled water loops
- cooling towers
- airflow management
- hot aisle / cold aisle containment
What you must know:
- how heat is removed
- what happens during cooling failure
- temperature monitoring
- airflow problems
Cooling failure can shut down entire server rows.
Rack and Hardware Infrastructure
Understand the hardware inside racks.
Typical rack contents:
- rack-mounted servers
- storage arrays
- top-of-rack switches
- rack PDUs
Hardware components:
- CPU
- RAM
- SSD / HDD
- NIC (network interface card)
- power supplies
- fans
Common hardware failures:
- disk failure
- PSU failure
- memory errors
- NIC failure
2. Networking Fundamentals
You must understand how traffic moves inside the data center.
Basic Networking Concepts
Important knowledge areas:
- IP addressing
- subnets
- VLANs
- DNS
- routing basics
Example concept:
192.168.1.0/24 supports 254 hosts.
Data Center Network Architecture
Modern data centers use leaf–spine architecture.
Structure:
Servers → Leaf switch → Spine switch → Other racks
What you must know:
- east–west vs north–south traffic
- top-of-rack switches
- spine switches
- network fabric
Network Failure Scenarios
You should be able to reason through issues like:
- rack switch failure
- fiber cable break
- VLAN misconfiguration
- DNS failure
- routing errors
3. Linux and Systems Awareness
Most infrastructure runs on Linux.
You don't need deep administration skills, but you should recognize basic diagnostics.
Important commands:
- top
- df
- iostat
- netstat
- journalctl
You should understand:
- CPU usage
- disk IO
- memory usage
- network connections
4. Storage Systems
You should understand basic storage redundancy concepts.
Important knowledge:
- RAID types
- distributed storage
- disk failure response
Example:
RAID-5 rebuilds data using parity if one disk fails.
5. Monitoring and Operational Metrics
AWS operations are extremely metric-driven.
Key metrics include:
- uptime
- incident frequency
- repair time
- hardware failure rates
- queue backlog
One important metric is MTTR.
Managers work constantly to reduce MTTR.
6. Incident Management
This role often leads Large Scale Events (LSEs).
Typical outage response process:
- detect alert
- determine scope
- isolate root cause
- coordinate engineers
- restore service
- perform postmortem
You must stay calm and organized during incidents.
7. Operational Process Management
Daily operational responsibilities include:
- ticket prioritization
- technician task assignment
- repair workflow management
- hardware logistics
- shift scheduling
Operations run 24/7.
8. Automation and Process Improvement
AWS values automation heavily.
Managers should identify opportunities to automate tasks using tools like:
- Python
- Ansible
- infrastructure monitoring tools
Automation improves:
- repair efficiency
- deployment speed
- reliability
9. People Leadership
This role is heavily focused on team leadership.
Responsibilities include:
- hiring technicians
- mentoring engineers
- performance reviews
- career development
- team motivation
You must manage teams across multiple shifts.
10. Project Management
You will lead mid-size infrastructure projects such as:
- new rack deployments
- hardware refresh cycles
- process improvements
- automation initiatives
Important skills:
- task prioritization
- cross-team coordination
- documentation
11. Documentation and Runbooks
AWS relies heavily on documentation.
You must write:
- SOPs (Standard Operating Procedures)
- incident reports
- troubleshooting guides
- operational runbooks
This ensures consistent operations across global sites.
12. AWS Leadership Principles
Interviews heavily test alignment with Amazon leadership principles.
Important ones include:
- Customer Obsession
- Ownership
- Dive Deep
- Bias for Action
- Invent and Simplify
- Deliver Results
Your answers must show real examples demonstrating these behaviors.
The Mental Model You Should Have
Every data center issue usually falls into one of four categories:
Power Network Compute Cooling
When something breaks, experienced operators ask:
- Did power fail?
- Did networking fail?
- Did hardware fail?
- Did cooling fail?
The Real Job
This role is essentially running the physical backbone of the cloud.
You must be able to:
- understand infrastructure
- lead technicians
- manage incidents
- improve operations
The job is to ensure the cloud never stops running.