
The early excitement around autonomous agent frameworks showed something important: AI agents can execute real workflows. Developers quickly began running agents locally to automate inboxes, analyze documents, and coordinate tasks across tools.
But what works for experimentation does not translate directly to production.
As organizations move from prototypes to deployment, they are discovering a structural gap between agent capability and enterprise readiness. Closing that gap requires more than running agents on better hardware or safer containers. It requires a governed knowledge infrastructure layer.
The problem with running agents like software
Early agent deployments often assume the agent behaves like deterministic software. It does not.
Agents operate with:
- probabilistic reasoning
- evolving context windows
- dynamic tool usage
- persistent instruction state
Giving such systems broad access to files, APIs, and internal workflows introduces a large operational risk surface.
Typical experimental deployments:
- inherit developer permissions
- run on local machines
- access multiple data systems simultaneously
- execute actions without traceable provenance
This creates a mismatch with enterprise security expectations.
Enterprises do not just need agents that work. They need agents that can be trusted.
Why scaling agents breaks traditional enterprise architecture
Traditional enterprise systems assume:
- permissions are predictable
- execution paths are auditable
- actions are attributable
- data access is bounded
Autonomous agents challenge each of these assumptions.
An agent interacting with documents, spreadsheets, APIs, and messaging systems becomes a distributed execution layer across the organization's knowledge surface.
Without infrastructure controls:
- instructions can drift
- context can be compressed or lost
- permissions can unintentionally expand
- audit trails become incomplete
- sensitive data exposure risk increases
This is not simply a tooling issue. It is an architecture issue.
The missing layer: governed knowledge execution
Most organizations initially try to solve agent deployment risk using one of three approaches:
- Local execution environments
- Cloud VM isolation
- sandboxed agent containers
These approaches help with infrastructure security.
They do not solve knowledge security.
Knowledge Stack introduces a structured execution environment where agents operate on governed knowledge, not raw file systems.
This shifts the deployment model from: agent + filesystem access
to: agent + structured knowledge graph + versioned documents + controlled connectors
From file access to knowledge access
Instead of granting agents direct access to internal systems, Knowledge Stack introduces:
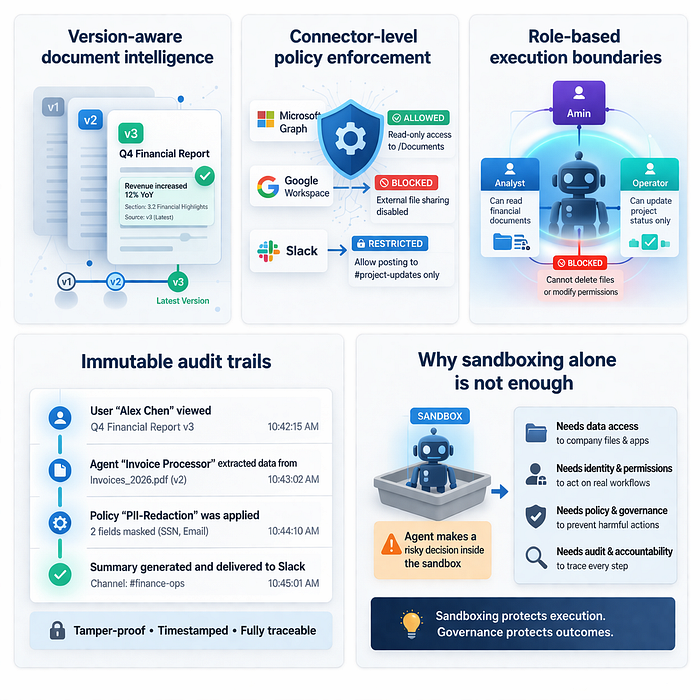
Version-aware document intelligence
Agents operate on:
- document versions
- structured sections
- chunk-level references
- provenance-linked knowledge units
This prevents silent context drift and supports verification during execution.
Connector-level policy enforcement
Agents interact through controlled integrations such as:
- Microsoft Graph
- Google Workspace
- Slack
- Box
- internal storage systems
Access inherits enterprise identity policies instead of bypassing them.
Role-based execution boundaries
Agents receive:
- scoped datasets
- scoped permissions
- scoped execution surfaces
This prevents the "confused deputy" problem where an agent retains privileges after losing constraints.
Immutable audit trails
Every agent interaction can be traced through:
- source references
- version lineage
- connector context
- execution history
This transforms agents from opaque operators into auditable collaborators.
Why sandboxing alone is not enough
Sandboxing protects infrastructure.
It does not protect decision-making workflows.
Enterprises require:
- provenance-aware execution
- access-aligned reasoning
- version-consistent responses
- connector-respecting data boundaries
- traceable outputs
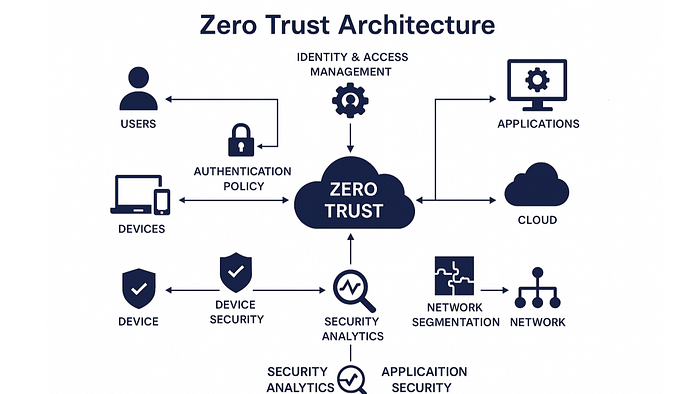
Enterprise agents require a zero-trust knowledge layer
Security teams increasingly treat agents as untrusted execution layers that must operate inside constrained environments.
A production-ready agent system therefore requires:
- isolated execution surfaces
- scoped credentials
- role-based connector access
- verified extension pipelines
- structured document ingestion
- lineage-aware reasoning
Moving from experimental agents to operational intelligence
Agent frameworks proved something important:
AI can execute workflows.
But production systems require more than execution capability.
They require:
- governance
- provenance
- versioning
- connector alignment
- policy inheritance
- enterprise deployment flexibility
Companies needs to enable organizations to deploy agents safely across their existing knowledge environment without exposing internal systems to uncontrolled execution risk.
This marks the transition from:
experimental agents running tasks
to
enterprise agents operating on trusted knowledge infrastructure.
Reference Article: https://www.ovaledge.com/blog/data-lineage-explained-with-examples?utm_source=chatgpt.com
Next Article: Why is data lineage necessary for business ?