
From Node.js + MongoDB to Java Spring Boot + PostgreSQL: a developer's honest retrospective on why I rebuilt the whole thing, what I learned, and why the architecture stayed the same.
Uploading files sounds simple until it isn't. The moment your app needs to handle anything beyond a profile picture documents, reports, mediayou hit a wall. Your server starts choking on 10 MB payloads, your storage costs creep up, and you realize you've been doing it wrong.
I built the same system twice. The first time with Node.js and MongoDB. The second time, I tore it down and rewrote it in Java Spring Boot with PostgreSQL. Same architecture, different tech. That experience taught me more about what actually matters in a backend system than any tutorial ever did.
TL;DR
- Pre-signed S3 URLs let clients upload directly — your server never touches the bytes.
- Node.js was fast to build but felt fragile at scale.
- Spring Boot brought structure, type safety, and predictability.
- The two-phase upload pattern works in any language.
The Problem With Naive File Uploads
Most beginners handle file uploads the obvious way: the client sends the file to the backend, and the backend saves it somewhere. Simple, right? It works — until it doesn't.
When a user uploads a 50 MB video, your Express or Spring server has to receive all 50 MB into memory or disk, then push it to S3. You've just doubled your data transfer costs. Your server is blocked. And your AWS credentials are being used on the server to proxy every upload.
The insight that changed everything: the backend doesn't need to see the file. It just needs to authorize the upload.
Pre-signed S3 URLs let you hand the client a time-limited, one-use URL that allows them to PUT a file directly to S3 — without ever exposing your AWS credentials. The backend stays lean. The client talks directly to S3. Your server just orchestrates the handshake.
Version 1: Node.js + MongoDB
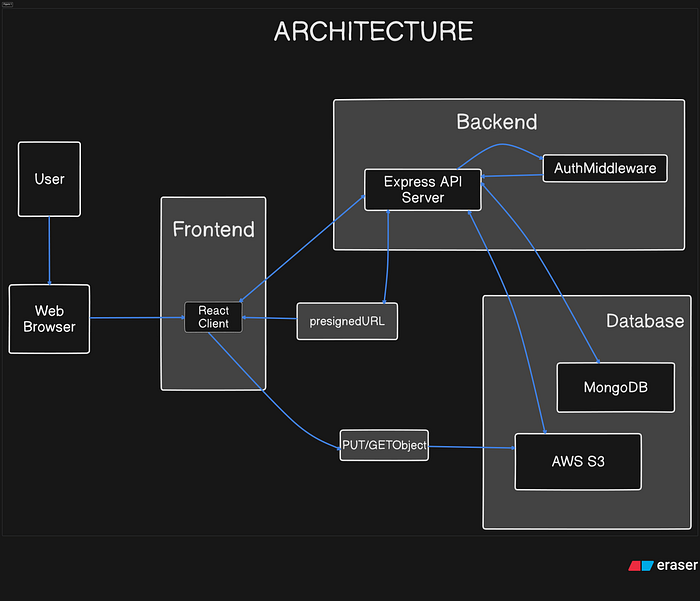
I started with the stack I knew best: Node + Express for the API, Mongoose for data modeling, JWT for auth, and the AWS SDK v3 for S3 operations.
WHAT I BUILT: Express.js | MongoDB + Mongoose | JWT | AWS SDK v3 | React + Vite
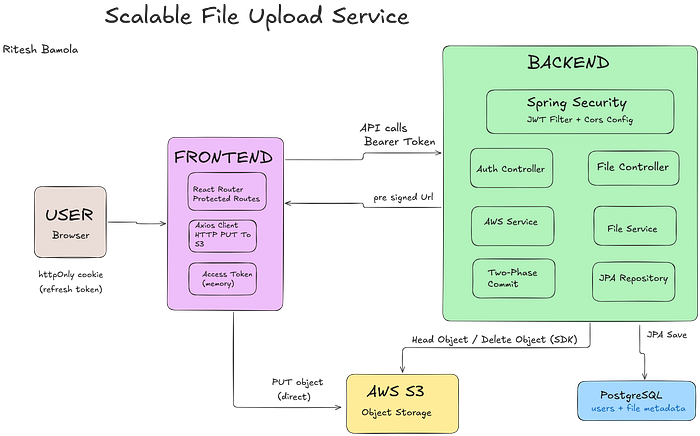
The architecture was clean. A /files/request-upload endpoint validated the filename, MIME type, and size, then issued a pre-signed URL. After the client uploaded directly to S3, it called /files/confirm-upload to mark the record as complete.
// Node.js – generate pre-signed upload URL
const command = new PutObjectCommand({
Bucket: process.env.S3_BUCKET,
Key: `uploads/${userId}/${fileId}/${fileName}`,
ContentType: mimeType,
});
const uploadURL = await getSignedUrl(s3Client, command, {
expiresIn: 300 // 5 minutes
});MongoDB was perfect for the metadata schema. Flexible enough to evolve without migrations, and querying by userId was instant with the right index. The whole backend came together in a weekend.
Where it got uncomfortable: JavaScript's dynamic typing started to feel like a liability in the auth layer. I had multiple subtle bugs where a missing field silently passed validation instead of throwing. The lack of compile-time checks meant every edge case had to be caught by tests — and I wasn't writing enough of them.
The Node version worked, but I never felt fully confident in it. Every deploy had a "I hope I didn't miss anything" feeling baked in.
Version 2: Java Spring Boot + PostgreSQL
A few months later, I decided to rebuild the backend from scratch. Not because Node.js was wrong — but because I wanted to understand what the same architecture felt like with stronger guardrails.
WHAT CHANGED: Spring Boot 3 | PostgreSQL + JPA | jjwt 0.12.5 | AWS SDK v2 | Spring Security
Java forced me to be explicit about everything. The JWT filter, the security config, the entity relationships — nothing was implicit. Setting up Spring Security alone took longer than the entire Node auth layer. But when it worked, it really worked.
// Java – S3Presigner as a @Bean
@Bean
public S3Presigner s3Presigner() {
return S3Presigner.builder()
.region(Region.of(awsRegion))
.credentialsProvider(DefaultCredentialsProvider.create())
.build();
}PostgreSQL replaced MongoDB for metadata storage. The schema was simple — users and files — so the relational model was a natural fit. JPA handled the boilerplate, and Hibernate's schema validation caught mismatches before the app even started.
Spring Boot's compile-time safety caught entire categories of bugs that had slipped through in the Node version. The verbosity was worth it
The Architecture That Survived Both Versions
The most interesting thing I learned from rebuilding this system? The core design didn't change at all. The two-phase upload pattern is language-agnostic — it lives at the architectural level, not the code level.
- Request: Client sends filename and size. Backend validates and creates a pending metadata record, then returns a pre-signed URL.
- Upload: Client PUTs the file directly to S3 using the URL. No backend involved. AWS handles everything.
- Confirm: Client calls the confirm endpoint. Backend verifies the S3 object exists.
- Done: File appears in dashboard. Download links are generated on demand as fresh pre-signed GET URLs — never stored.
Java Architecture:
Nodejs Architecture :
The Honest Comparison
If I had to choose again, I'd pick Spring Boot for anything production-bound. The type safety, the structured security model, and the maturity of the ecosystem are genuinely worth the extra ceremony. Node.js got me to a working prototype faster but the Spring version is the one I'd trust at 2 AM when something breaks.
Nodejs — https://github.com/riteshbamola/Scalable-FIle-Upload-Service
Java — https://github.com/riteshbamola/File-Upload-Service
Sometimes the best way to learn an architecture is to build it twice.
Both versions are public on my GitHub. Feel free to steal the pattern the two-phase upload approach is one of those ideas that once you see it, you can't unsee it.
If you found this useful, the best thing you can do is try building it yourself. Start with the Node version — get it working in a day. Then come back and rebuild it in whatever backend language you want to get better at.