
Every codebase has bugs nobody knows about yet. Not the ones in your backlog. The ones sitting quietly in production, waiting for exactly the right conditions to surface.
ClawPatch finds them. I ran it on a real repo and found 6 issues in minutes — including a deadlock bug that could have caused real production issues.
Here's what it is, and how to use it.
What ClawPatch does
clawpatch.ai is an AI-powered code audit tool that runs against your repository and produces structured findings — real bugs, test gaps, and maintenance issues, triaged by severity.
The workflow is six steps:
review → run the audit against your codebase
↓
report → generate a structured findings report
↓
next/show → queue up findings (sequentially or by ID)
↓
triage → mark each finding: real bug / false positive / already covered
↓
fix → attempt an automated patch on one finding
↓
revalidate → recheck if the fix actually resolved the issueIt integrates with Codex, so once findings are queued, you can let Codex work through them automatically.
Findings from a repo
Run 1: Small Swift CLI repo
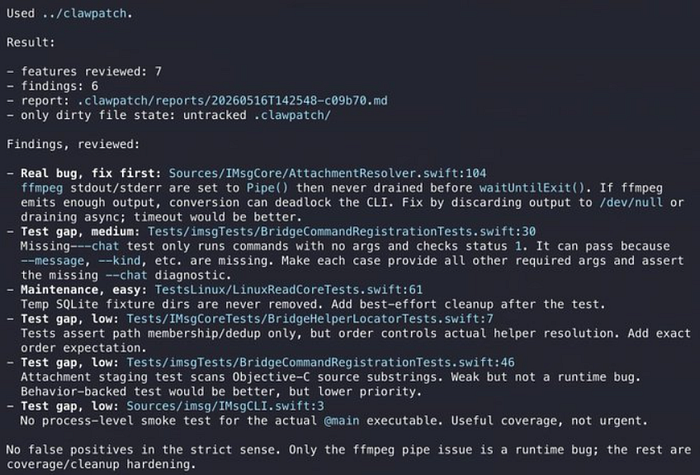
Features reviewed: 7
Findings: 6
Report: .clawpatch/reports/20260516T142548-c09b70.md
Only dirty file state: untracked clawpatch/Six findings from seven features reviewed. Here's what it found:
Finding 1: Real deadlock bug (fix first)
File: Sources/IMsgCore/AttachmentResolver.swift:104
Severity: Real bug
// The problem:
let process = Process()
process.standardOutput = Pipe() // stdout piped
process.standardError = Pipe() // stderr piped
// ... configure process ...
process.waitUntilExit() // blocks here
// Never drains the pipes before waitingIf ffmpeg emits enough output to fill the pipe buffer, waitUntilExit() blocks forever waiting for the process to finish — but the process is waiting for the pipe buffer to be drained. Classic deadlock.
The fix: either discard output to /dev/null or drain async:
// Option A: discard output entirely
process.standardOutput = FileHandle.nullDevice
process.standardError = FileHandle.nullDevice
process.waitUntilExit()
// Option B: drain async before waiting
let outputPipe = Pipe()
process.standardOutput = outputPipe
var outputData = Data()
// Read in background to prevent buffer deadlock
let outputHandle = outputPipe.fileHandleForReading
outputHandle.readabilityHandler = { handle in
outputData.append(handle.availableData)
}
process.waitUntilExit()
outputHandle.readabilityHandler = nilThis is the kind of bug that only manifests when ffmpeg produces significant output — silent in testing, potentially breaking in production.
Finding 2: Test gap, medium priority
File: Tests/imsgTests/BridgeCommandRegistrationTests.swift:30
// Current test — passes for the wrong reason:
func testMissingChat() {
let result = runCommand(["missing-chat-command"])
XCTAssertEqual(result.status, 1) // exits with error
}
// Problem: exits with status 1 because -message, kind, etc.
// are ALL missing, not because of the specific missing-chat conditionThe test passes but doesn't verify what it claims to verify. Fix: provide all required args except the one being tested:
func testMissingChat() {
let result = runCommand([
"missing-chat-command",
"--message", "test",
"--kind", "text"
// deliberately omit --chat
])
XCTAssertEqual(result.status, 1)
XCTAssertTrue(result.stderr.contains("missing-chat diagnostic"))
}Finding 3: Maintenance issue, easy
File: TestsLinux/LinuxReadCoreTests.swift:61Temp SQLite fixture directories created during tests are never cleaned up. Easy fix:
// Add after test completion:
defer {
try? FileManager.default.removeItem(at: tempDir)
}Findings 4–6: Lower priority test gaps
BridgeHelperLocatorTests.swift:7 → Tests membership/dedup but not order
(order controls actual resolution)
BridgeCommandRegistrationTests.swift:46 → Scans Objective-C source substrings
(fragile, not a runtime bug)
IMsgCLI.swift:3 → No process-level smoke test for @main executableClawPatch's summary: "No false positives in the strict sense. Only the ffmpeg pipe issue is a runtime bug; the rest are coverage/cleanup hardening."
That's the right framing. The tool isn't crying wolf — it's giving you one real bug and five legitimate improvements, clearly ranked.
Run 2: Full repository audit
Someone ran it on their entire codebase:
High severity: 6
Medium severity: 46
Low severity: 35
Total findings: 8787 findings from one audit run. The split matters — 6 highs that need immediate attention, 46 mediums worth scheduling, 35 lows to address when convenient. That's a real prioritization signal, not just a raw count.
How to run it
# Install and run on your current repo
../clawpatchThat's the basic command. ClawPatch creates a .clawpatch/ directory in your repo (untracked — it doesn't touch your git history) and generates a report at:
.clawpatch/reports/TIMESTAMP-HASH.mdWork through findings with the queue commands:
# Show next finding in queue
clawpatch next
# Show specific finding by ID
clawpatch show <finding-id>
# Triage a finding
clawpatch triage <finding-id> --status real-bug
clawpatch triage <finding-id> --status false-positive
clawpatch triage <finding-id> --status already-covered
# Attempt automated fix
clawpatch fix <finding-id>
# Revalidate after fixing
clawpatch revalidate <finding-id>What makes this different from linters
Standard linters catch known bad patterns. They're fast, they're deterministic, and they're excellent at what they do.
ClawPatch catches different things:
Linters find:
- Style violations
- Type errors
- Known antipatterns
- Obvious bugs (null dereference, etc.)
ClawPatch finds:
- Logic bugs that depend on runtime behavior
- Tests that pass for the wrong reasons
- Missing coverage for specific edge cases
- Resource cleanup issues
- Concurrency problems (like the pipe deadlock)The ffmpeg deadlock is a good example. No linter would catch that. It's not a syntax issue or a known antipattern. It's a subtle interaction between pipe buffer limits and blocking process API — the kind of thing that requires understanding what the code is trying to do, not just what it's literally written.
The Codex integration
Once ClawPatch surfaces findings, Codex can work through them:
ClawPatch report → Codex reads findings → patches queued findings
→ you review diffs
→ revalidate with ClawPatchThe combination is useful because ClawPatch finds issues Codex wouldn't proactively look for, and Codex fixes them faster than manual patching. The revalidation step closes the loop — ClawPatch confirms the fix actually resolved the finding, not just changed the code.
What to expect
Based on the runs above, expect:
Small repo (7 features): ~6 findings, 1-2 real bugs
Large repo (full audit): 50-100 findings across severity levels
False positive rate: Low — ClawPatch self-describes findings carefully
Time to first report: MinutesThe findings are clearly categorized:
Real bug → runtime impact, fix immediately
Test gap → coverage missing, schedule it
Maintenance → cleanup/hardening, fix when convenientNo tool finds everything. ClawPatch is explicit that the severity ratings are signals, not guarantees, and that human review is required before applying any automated fix.
Try it
../clawpatchRun it on a repo you know well. The interesting part isn't the findings you expect — it's the ones you don't.