June 6, 2026
A Startup Lost a $3.2 Million Contract Because Nobody Had Ever Checked If Their Servers Were Secure
A story about compliance drift, automated remediation, and why “we’ll do the audit next quarter” is a business risk

Ubani Obiajulum Emmanuel
6 min read
Before I became a Cloud and DevOps Engineer, I managed a beauty and cosmetics store in Lagos for three years. One of the things that kept me up at night was inventory drift. Products would disappear from shelves. Stock counts would become inaccurate. Suppliers would deliver wrong quantities. Without a daily count and a system for catching discrepancies early, you would discover the problem only when a customer asked for something you thought you had but did not.
Infrastructure compliance works exactly the same way.
Every day something changes on your servers. A package gets updated. A configuration file gets modified. A new engineer provisions a new instance without following the hardening checklist. Without a system that continuously measures the security state and alerts when it drifts, you discover the problem only when an auditor asks a question you cannot answer.
By the end of this article you will understand what CIS compliance means in practice, why it matters for businesses that sign enterprise contracts, and how I built a pipeline that scans servers automatically, fixes what is broken, and blocks deployments when the compliance score drops below 85%.
The $3.2 Million Audit Failure
In 2022, a fintech startup in Berlin was three weeks from signing one of the biggest contracts in their history.
The enterprise client required a SOC2 Type II compliance report as a condition of signing. Standard requirement. The startup engaged an external audit firm. The auditors spent two weeks reviewing their AWS infrastructure. What they found was not an active breach. It was not a sophisticated attack. It was years of infrastructure growth without anyone checking the security baseline.
Root login was enabled over SSH on 34 of their 41 production servers. Not because anyone decided to enable it. Because nobody had ever explicitly disabled it.
Audit logging was not configured on any instance. Password policies allowed passwords that never expired. World-writable directories existed in production. None of these were intentional decisions. They were the default state of servers that were never hardened.
The contract was delayed. The compliance remediation took four months of manual work. During those four months, the enterprise client signed with a competitor who could show clean compliance on demand.
The lost contract was worth $3.2 million.
What CIS Compliance Actually Means
Let me explain CIS benchmarks the way I wish someone had explained them to me when I was starting out.
CIS stands for Center for Internet Security. They publish detailed benchmark documents for every major operating system. Each benchmark contains hundreds of specific, testable security controls organized by category.
Think of it like the Lagos State fire safety inspection checklist. An inspector walks into your building and checks specific things. Fire extinguishers on every floor. Clearly marked emergency exits. Smoke detectors in every room. Working sprinkler system. Each item is either compliant or not. Your overall compliance score tells you what percentage of the required controls you have in place.
- CIS benchmark → The Lagos State fire safety checklist
- OpenSCAP → The inspector who walks through and checks every item
- Compliance score → The percentage of items that pass inspection
- CIS Level 1 → The basic fire safety requirements every building must meet
- CIS Level 2 → The enhanced requirements for buildings that house critical infrastructure
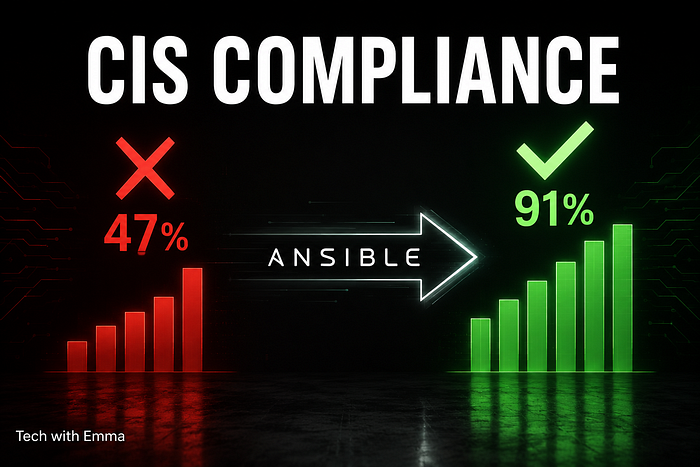
A fresh Amazon Linux 2023 server out of the box scores about 47% on CIS Level 2. That means 53% of the security controls that CIS considers essential are not configured by default. Some are minor. Some are the kind of gap that makes lateral movement trivial for an attacker who gets inside your network.
What the Pipeline Does
I built a pipeline that takes a server from 47% to above 85% compliance in a single automated run.
Step 1 — Scanning. An Ansible playbook runs OpenSCAP against both Amazon Linux 2023 and Ubuntu 22.04 servers. OpenSCAP evaluates every CIS rule and produces a score. The score is extracted from the XML results file and saved as JSON.
Step 2 — Remediation. Another Ansible playbook reads the results and applies fixes for every automatically remediable finding. SSH hardening. Kernel network parameter tuning. Audit logging configuration. Password policy enforcement. File permission corrections. Each fix is idempotent — running it multiple times produces the same result.
Step 3 — Re-scanning. The same scan runs again after remediation to confirm the improvement. The before and after scores are the proof of value.
Step 4 — The compliance gate. A Python script reads all the JSON results, checks whether every instance is above 85% on CIS Level 2, and exits with code 1 if anything fails. In GitHub Actions, an exit code of 1 blocks every downstream job. The deployment cannot happen until the compliance gate passes.
The Motor Park Analogy for the Compliance Gate
Here is how I explained the compliance gate to a non-technical friend using the Oshodi motor park.
Imagine a motor park where buses must pass a roadworthiness check before they are allowed to load passengers. The mechanic checks the brakes, the tyres, the lights, and the engine. If anything fails, the bus cannot load. It cannot leave. It goes to the repair bay first.
- The compliance gate → The roadworthiness check at the park gate
- The CI/CD pipeline → The bus trying to leave the park
- The compliance score → The brake condition, tyre depth, and light functionality
- The 85% threshold → The minimum standard the mechanic accepts
- Deployment blocked → Bus cannot load passengers until repairs are done
- Ansible remediation → The repair bay that fixes what failed
A bus that fails the check does not get waved through with a note saying we will fix it next week. It goes to the repair bay. Only after the mechanic confirms the repairs does the bus get clearance to load passengers.
That is exactly what happens in this pipeline. An instance that scores below 85% does not get deployed to. It gets remediated. Only after the re-scan confirms improvement does the pipeline proceed.
The Mistake That Almost Locked Me Out
I need to tell you about the mistake I made that could have ended this project early.
I was testing the SSH hardening role and added a line to the sshd_config template that said AllowUsers ec2-user. This is a CIS recommendation for restricting SSH access to specific users. The playbook ran. The handler restarted SSH. The new sshd_config loaded.
I lost my connection.
I opened a new terminal and tried to SSH back in. Connection refused. I checked the instance — it was running. I checked the security group — port 22 was open. The problem was that I was connecting to an Ubuntu instance where the default user is ubuntu, not ec2-user. The AllowUsers directive was blocking ubuntu. Only ec2-user was allowed. And ec2-user does not exist on Ubuntu.
There was no way back in via SSH. I had to terminate the instance and provision a new one.
The lesson lives permanently in my remediation role now:
AllowUsers→ Set per OS:ec2-userfor Amazon Linux,ubuntufor Ubuntu- Test on throwaway instances first → Never run untested remediation on anything you cannot rebuild
- Handlers fire after all tasks complete → If a task fails mid-playbook, the handler may not fire, leaving you with a modified config that was never applied
The Real Lesson
Here is what compliance automation actually teaches you that the documentation never says.
The Berlin startup did not fail their audit because they were incompetent. They failed because compliance state decays automatically and invisibly unless something is watching it.
Every day that passes without a compliance scan, your infrastructure drifts a little further from the baseline. A developer changes a configuration for a legitimate reason. A package update modifies a default setting. A new instance is provisioned in a hurry without following the hardening checklist. None of these are malicious. All of them move the needle in the wrong direction.
Without a system that catches drift as it happens, you only know about it when an auditor asks. And by then, the drift has been accumulating for months.
The real lesson of this project is not that compliance automation is technically clever. It is that treating compliance as a continuously measured infrastructure property — rather than a periodic manual review — eliminates an entire category of business risk that engineering teams carry without realizing it.
The auditor who walks in unannounced and asks for your CIS compliance posture should get a CloudWatch dashboard, not a stressed engineer and a four-month delay.
What Comes Next
The next project in this series is the Privileged Access Management platform, where I replace every bastion host in the architecture with HashiCorp Boundary, issue just-in-time SSH certificates that expire after 3 minutes via Vault SSH CA, and record every session for full auditability.
Want to see the actual code, all Ansible roles, the Python compliance gate script, and the full GitHub Actions pipeline?
The complete technical breakdown is here: https://emmanuelubani.hashnode.dev/i-built-an-automated-cis-compliance-pipeline-that-saved-a-company-from-a-3-2-million-contract-loss-here-is-how-it-works
The full code is on GitHub: github.com/Eaglewings966/openscap-ansible-compliance
Emmanuel Ubani is a Cloud and DevOps Engineer based in Lagos, Nigeria. He writes about real infrastructure builds, career transitions into tech, and lessons learned the hard way.