Rule management, issue remediation workflows, and the metrics framework that keeps your SAST program honest — because tools are only as good as the processes around them.
Part 1 covered the vision, tool selection, and architecture. Now we get into the operational machinery — the three lifecycles that make a SAST program sustainable: how rules are managed, how issues flow from detection to resolution, and how you measure everything to keep the system calibrated.
The Rule Management Lifecycle
Rules are the heart of any SAST program. A great tool with bad rules is worse than a mediocre tool with well-tuned rules, because bad rules generate noise that kills developer trust. You need a formal lifecycle for how rules enter the system, get tested, pass quality gates, and eventually get promoted or retired.
The lifecycle I implemented has four stages, each with clear ownership and measurable exit criteria.
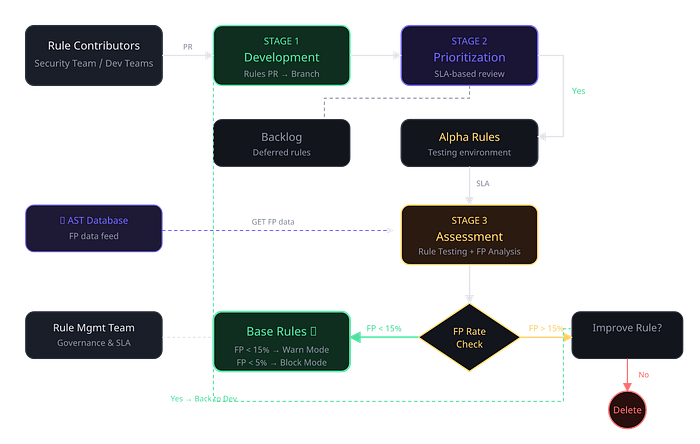
The Four Assessment Cases When a rule arrives for assessment, there are four possible outcomes that the rule management team needs to handle:
- Meets thresholds: It gets merged into the base rules folder (warn mode if FP < 15%, block mode if < 5%).
- Falls short but shows promise: Goes back to development for improvement with specific feedback.
- Completely inapplicable: PR is rejected (e.g., targets an unused framework).
- Pre-existing modification: Disabling outdated rules, enabling for new codebases, or uplifting degraded rules.
False Positive Thresholds For high-confidence rules (those that block PRs): FP rate must be below 5%. For medium-confidence rules (warn mode): FP rate must be below 15%. These aren't arbitrary — they're calibrated to the point where developer trust starts to erode. Above 15% FP, developers begin ignoring all findings, even legitimate ones.
The Issue Remediation Lifecycle
When a SAST scan surfaces a finding in a developer's PR, what happens next? This is where most SAST programs fall apart. Without a clear remediation workflow, findings pile up, developers get confused about what to do, and the security team loses visibility into whether issues are actually being resolved.
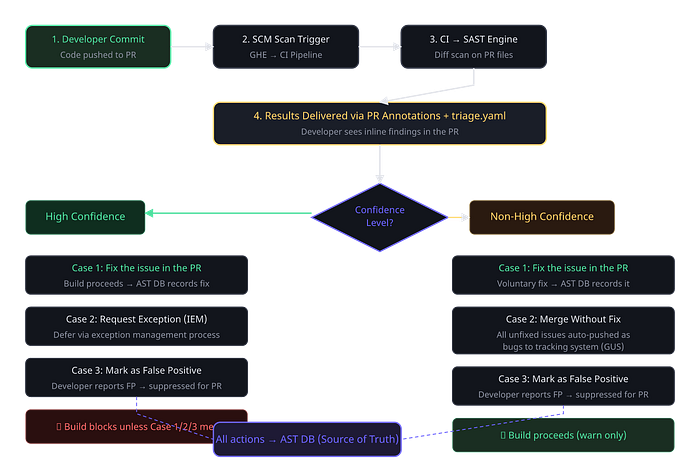
The critical distinction is between high-confidence and non-high-confidence rules. High-confidence rules are your gatekeepers — they block the build. If a high-confidence rule fires, the developer must either fix the issue, request a formal exception through the exception management process, or mark it as a false positive. The build cannot proceed until one of these actions is taken.
For non-high-confidence rules, the system operates in warn mode. Developers see the findings as annotations on their PR, but the build is not blocked. If they merge without addressing the issue, the finding automatically gets pushed as a bug to the tracking system. This creates accountability without blocking velocity — the issue still gets tracked, just through a different workflow.
Critical Design Decision Every action — fix, exception, false positive report, merge-without-fix — must be recorded in the AST database as the single source of truth. Without this, you lose the ability to calculate your key metrics accurately. This is non-negotiable.
The Metrics Framework
You can't improve what you can't measure. The number of findings is vanity. The metrics that matter are the ones that tell you about the health of your program.
Vulnerability Finding Metrics These tell you whether the program is actually finding and fixing real vulnerabilities:
- Fix Rate: Percentage of identified issues successfully resolved.
- False Positive Rate (FPR): From full repo triage, developer feedback, and PR scans.
- Not Exploitable Rate: Issues determined to pose no significant risk after analysis.
- No Action Rate: Warnings completely ignored by the developer.
- Avg Time to Remediate (TTR): Time from detection to fix.
- True Positive Rate: Real security threats correctly identified.
Each of these metrics should be sliceable at multiple dimensions: per business unit, per rule, per vulnerability category, per repository, per team, and per developer.
Threshold-Based Alerting Raw metrics are useful for analysis, but you also need automated alerts when metrics cross boundaries:
- FPR > 15% (min 10 findings) → Alert rule management team.
- Fix Rate >= 50% (min 10 findings) → Investigate rule quality / dev experience.
- Not Exploitable Rate > 15% (min 10 findings) → Review rule precision.
- No Action Rate >= 50% (min 10 findings) → Assess developer engagement.
Rule Quality & Operational Metrics The rule management team needs metrics focused on rule health: impact classification, confidence levels, severity distributions, and CWE mapping. The platform team needs operational metrics: scan execution time, scan coverage (what percentage of eligible repos are enrolled), and PR counts with zero reported files scanned.
Priority Ranking: The P-Rating Strategy
Not all vulnerability categories are equal. I developed a priority ranking (P-rating) strategy that combines historical data from the bug tracking system with industry standards to assign each vulnerability category a baseline priority.
- Analyze historical data for distribution/severity of reported vulnerabilities.
- Calculate the frequency of P1/P2/P3/P4 classifications for each category.
- Compare against industry standards (CWE, OWASP).
- Assign a final reporting rating based on the comparison.
If XXE historically shows high likelihood, high impact, and consistently lands as P1 — and CWE confirms this — then your SAST rules for XXE should report findings as P1.
Why This Matters Without priority ranking, all SAST findings look the same to developers. When everything is urgent, nothing is urgent. P-ranking lets developers focus on the highest actual risk, increasing fix rates and reducing the perceived burden of the program.
What's in Part 3
With the operational lifecycle and metrics framework in place, Part 3 covers the human side: scaling adoption across business units, building the governance model, measuring program success at the organizational level, and the long-term vision for integrating FAST SAST and DEEP SAST into a holistic security posture view. It's the part that turns a technical implementation into a sustainable program.