
Evolved Scanning based on LLM technologies — From .env to /llms.txt: The New Age of Web Reconnaissance
What 30 Days of Internet Noise Reveals: A TTP Analysis of Automated Web Scanning
Introduction
Even a small public-facing service attracts continuous scanning activity.
Over the past month, I analyzed ~3,500 suspicious HTTP requests hitting a web service I manage, focusing on attacker Tactics, Techniques, and Procedures (TTPs) rather than raw traffic volume.
Dataset Overview
The dataset consisted of:
- Cloud Run request logs
- Requests filtered to:
GETtraffic andseverity >= WARNING - ~3,560 total suspicious requests
From this, several categories of behavior emerged.
1. Most Traffic Is Noise
Roughly 78% of requests came from obvious automation:
curlpython-requests
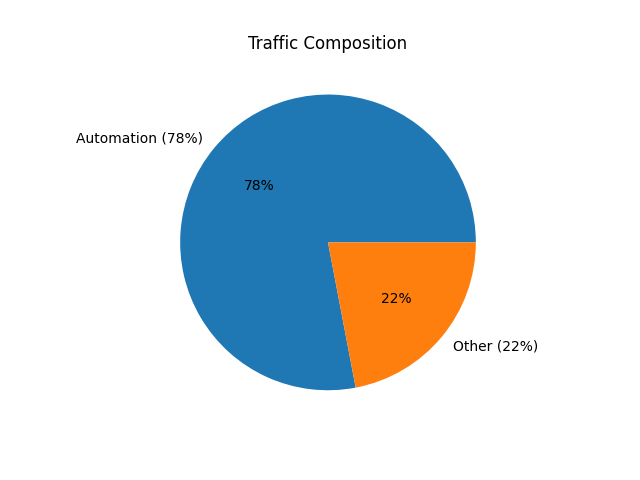
These requests were:
- High volume
- Low diversity
- Easy to detect
This aligns with what most practitioners already suspect:
The majority of internet scanning is low-effort, opportunistic noise.
2. Not All Surfaces Are Equal
Two broad target categories stood out:
AWS / Storage-style probing
- ~240 requests
- ~9% browser-like user agents
PHP-related probing
- ~721 requests
- ~15% browser-like user agents
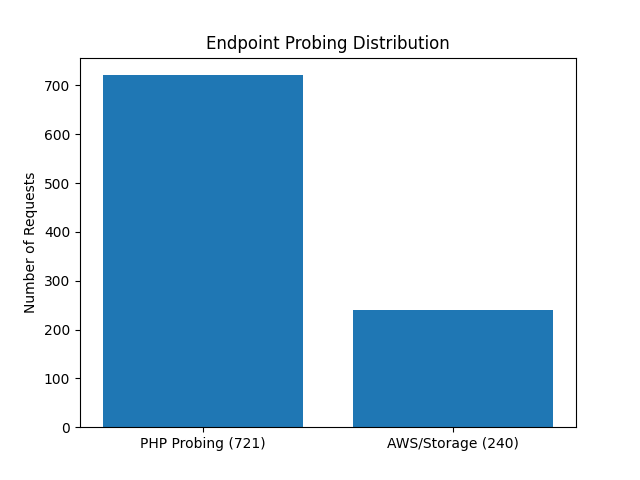
This is a meaningful difference.
PHP-related endpoints were probed ~3× more often and with greater use of stealth.
This suggests attackers prioritize:
- Legacy web stacks
- High-probability vulnerability surfaces
3. High-Value Endpoints Are Targeted (Selectively)
Even though they were low in volume, the following endpoints stood out:
/.env/.git/config/xmlrpc.php
These are classic high-impact exposure points:
- Secrets
- Source code
- CMS interfaces
The most interesting finding:
~95% of
/xmlrpc.phprequests used browser-like or malformed multi-agent headers.
This indicates:
- Not random scanning
- But selective evasion applied to higher-value targets
4. Blended Reconnaissance Is the Real Signal
When filtering out obvious automation, a second layer appears:
- Browser-like user agents (Chrome, Firefox, Safari)
- Requests for clearly non-human paths (
.env,.git,/xmlrpc.php) - Multi-agent header anomalies (~379 events)
This behavior reflects:
Blended reconnaissance — malicious traffic designed to look legitimate
Key techniques:
- User-agent spoofing
- Multi-agent header injection
- Referer manipulation
5. Emerging Targets: /llms.txt
One unexpected finding was probing for:/llms.txt
This is not a traditional web attack surface, but is associated with emerging conventions around AI/LLM systems.
This suggests:
Scanning wordlists are evolving to include newer, non-traditional endpoints.
Key Insights
- Most traffic is noise, but not all noise is equal The majority of requests are low-value automation.
- Higher-value targets attract stealth Evasion techniques are selectively applied.
- User-agent is not a reliable signal Browser-like requests can still be malicious.
- Attack surfaces are evolving
New endpoints like
/llms.txtare entering scan patterns. - Exposure, not targeting, drives attacks Your service doesn't need to be "important" to be scanned.
Conclusion
The most important takeaway is this:
The meaningful part of attacker behavior is not in the volume — it's in the intent.
Even in a small dataset:
- You can see prioritization
- You can see adaptation
- You can see evolution
And in this case:
- No exposure
- No escalation
- Just continuous probing
Which is exactly what a well-hardened system should look like.