

Aslam O Alaikum ! I hope you all are doing well. Today, I will share one of my favourite DoS findings and walk you through the idea behind it. I hope you find it useful and learn something from the process.
English is not my first language, so parts of this write-up were refined using AI and may contain minor wording and explanation issues.
Starting :
I came across a self Hosted BugBounty program (very popular) that allows hunting for Denial-of-Service (DoS) vulnerabilities, with the following constraint:
Only DoS issues that can be triggered by a single user with a single request are considered.
Under this restriction, there are multiple ways to identify a valid Denial-of-Service (DoS) condition. In this case, I focused on locating an endpoint where the amount of data processed and returned by the server can be influenced by user-supplied input.
During testing, I identified a User Activity section that displays login and security-related events. This functionality uses pagination and, by default, returns 10 records per request. The corresponding request structure is shown below:
{
"currentPage": 1,
"limit": 10,
"clientTime": "1990-01-08 21:21:37",
"authPayload": "{\"createdAt\":\"1990-01-08 21:21:37\",\"context\":{}}"
}The limit parameter directly controls the number of activity records processed and included in the response.
To verify the presence of server-side limits, I increased the limit parameter from 10 to 10000. The request was processed successfully without any validation or constraint, and the server returned a 200 OK response containing all 13 existing records.
GOAL
After confirming that no server-side limit was enforced on the number of activity records returned, the next objective was to generate a sufficiently large dataset to demonstrate meaningful backend resource exhaustion (targeting approximately 500 MB–1 GB of response data).
To estimate feasibility, I calculated the size contribution of each activity record. Each login or security activity entry was approximately 690 bytes in size. Based on this, generating a response of roughly 1 GB would require approximately 1,454,750 activity records.
At this stage, the primary challenge was generating this volume of activity records. Direct automation of the login process was not feasible due to the presence of CAPTCHA protections, which effectively prevented repeated scripted logins.
I paused testing and started again the next day on another subdomain of the same application. During this testing, I identified a "Switch to App" feature, which proved to be a critical missing component of the exploit . This feature allows a user to switch from the subdomain to the main application without re-authenticating. Each switch action is recorded by the backend as a successful login event and appears in the user activity log.
The switching flow operates as follows:
- The user click on "Switch to Main Button" (
sub.example.com/switch/main) - The server generates a redirect URL containing an authentication token
- A subsequent GET request to this URL completes the switch and is logged as a login activity
Because this process does not require CAPTCHA interaction and relies solely on following server-generated redirects, it is trivial to automate. By repeatedly cycling through this switch flow, it is possible to rapidly inflate the number of stored activity records, enabling the generation of an extremely large dataset that can later be retrieved using an unbounded limit parameter.
Final Exploit
For the final step, I needed to repeat the switching process very quickly. At this point, I noticed that rate limiting was in place, but it was applied only per IP address, not per user.
To continue testing, I used "IP Rotate Extension" to Bypass IP based Rate Limit here. I then configured Burp Intruder (Burp Pro) to send batches of 20 parallel requests and repeatedly trigger the switch flow.
Each successful switch was recorded as a login activity and added more than 600 bytes of data to the activity log. I let this process run for days, and eventually it resulted in over 1,400,000+ login activity records being stored for a single user account.
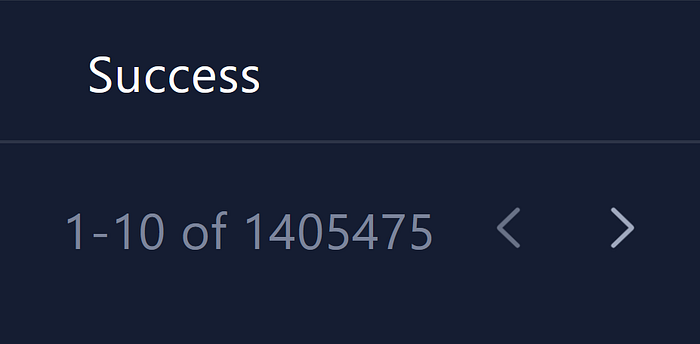
After generating a large number of activity records, I submitted the following request to retrieve them in a single response:
{
"currentPage": 1,
"limit": 1400000,
"clientTime": "1990-01-08 21:21:37",
"authPayload": "{\"createdAt\":\"1990-01-08 21:21:37\",\"context\":{}}"
}As expected, the server attempted to process the unbounded request and responded after approximately 60 seconds with an HTTP 504 Gateway Timeout. At this point, the application appeared to recover normally.
However, after sending the same request three additional times, the main application began consistently returning 504 errors across different user accounts. To confirm the impact, I tested access from virtual browsers and different IP addresses. During these tests, the application was globally unavailable for approximately 20 seconds following each request.
This behaviour was reproducible: each time the same request was sent, the back-end became temporarily unavailable for all users. The issue could therefore be repeatedly triggered by a single user using a single request, resulting in a reliable Denial-of-Service condition.
Testing was stopped at this point, and the issue was responsibly reported to the security team. The vulnerability was confirmed and accepted with a High severity rating (7.5).
I hope you learned something from this write-up. I will be sharing more interesting and critical DoS findings in future posts, including some that I have never shared before.