
As AI agents become more capable, they are increasingly integrated into real-world systems — querying data, triggering workflows, and interacting with production infrastructure. But this power comes with a fundamental security challenge:
AI agents are not trustworthy execution environments.
They can be influenced, manipulated, or coerced through prompt injection, tool chaining, or indirect data exposure. If we treat them like traditional application clients, we risk exposing credentials, expanding access unintentionally, and enabling lateral movement.
To address this, we designed a security-first framework for MCP (Model Context Protocol) connectors — a hardened bridge between AI agents and sensitive backend systems.
This article walks through the core principles, architecture, and controls that make MCP connectors secure by design.
The Core Insight: The Agent Is Not the User
The most important design decision is simple but often overlooked:
The AI agent operates on behalf of the user — but it is not the user.
Anything exposed to the agent:
- Maybe logged
- Maybe persisted
- Maybe reused across tool calls
- Maybe influenced by malicious prompts
So we treat the agent as a non-confidential channel.
This single assumption drives the entire security model.
Architecture: The Connector as the Trust Boundary
The MCP connector sits between three entities:
- User — authenticated via enterprise SSO
- AI Agent — orchestrates tool calls (untrusted)
- Backend Systems — APIs, databases, storage, etc.
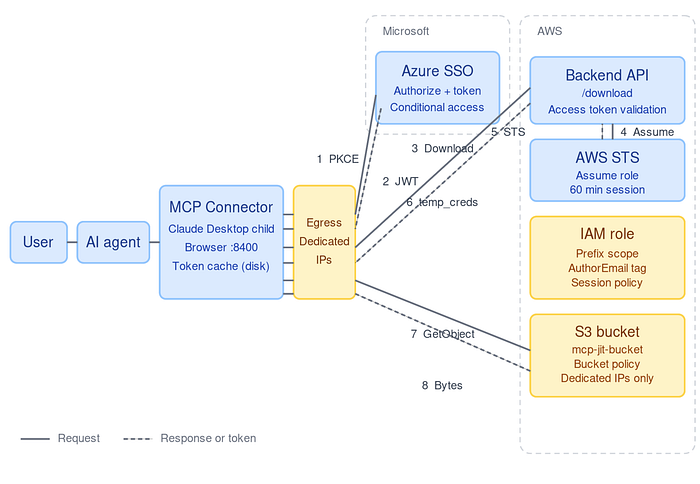
The connector becomes the credential boundary:
- It authenticates the user via OAuth (Authorization Code + PKCE)
- It holds tokens strictly in memory (never exposed to the agent)
- It brokers short-lived credentials for downstream systems
- It executes sensitive operations internally
- It returns only minimal, sanitized results to the agent
The agent never sees:
- Access tokens
- Refresh tokens
- API keys
- STS credentials
Identity and Authentication: Strong by Default
We enforce:
- OAuth2 Authorization Code + PKCE
- Conditional Access policies (MFA + trusted network)
- Memory-only token storage
- No refresh tokens on disk
- Forced re-authentication on connector restart
This eliminates:
- Token leakage via disk or backups
- Long-lived credential exposure
- Silent persistence across sessions
Authorization: Derived, Not Trusted
One of the most common mistakes in AI integrations is trusting tool input.
We explicitly reject that.
Authorization is derived from identity — not from agent-provided arguments.
Controls include:
- Scope derived from validated identity tokens
- Enforcement at the resource layer (IAM, DB policies, API ACLs)
- Strict validation of tool inputs
- Fast-fail guards for invalid or out-of-scope requests
The connector does not decide what a user is allowed to do — it ensures the request is executed within the constraints defined by backend systems.
Credential Model: Short-Lived and Just-in-Time
We adopt a Just-In-Time credential model:
- Backend broker exchanges identity tokens for scoped credentials
- Credentials are:
- Short-lived (≤ 60 minutes)
- User-scoped
- Never persisted
- Connector uses them in-memory only
This drastically reduces:
- Credential replay risk
- Blast radius of compromise
- Long-term exposure
Defense Against Prompt Injection
Prompt injection is not a theoretical risk — it is inevitable.
So we don't try to "detect" it. We design around it.
Key protections:
1. Tool Safety Layer
Every tool call passes through a policy enforcement layer that validates:
- Allowed operations
- Input schema
- Identity-derived scope
- Output constraints
2. Output Minimization
The connector returns:
- Summaries
- Aggregated results
- File references
Not:
- Raw secrets
- Full datasets (unless explicitly required)
3. Data Classification
Outputs are categorized (e.g., public, internal, sensitive), and tools enforce:
- Allowed data exposure levels
- Redaction rules
- Size limits
Even if the agent is manipulated, it cannot extract sensitive data beyond defined boundaries.
Process-Level Hardening: Protecting Memory
Even if tokens are not exposed to the agent, they still exist in memory.
We protect against local attacks using OS-level controls:
- Disable core dumps
- Block process memory inspection (ptrace, /proc/<pid>/mem)
- Apply hardened runtime on macOS
- Enforce system-level policies (AppArmor / SELinux)
This mitigates:
- Credential scraping
- Co-resident malware
- Debugger-based extraction
Network Controls: Containing Credential Usage
Outbound traffic from the MCP connector is governed through strict egress controls, enforced via a secure web proxy
- All traffic is routed through the proxy
- Destination allowlisting is enforced
- TLS is validated and inspected where applicable
- Requests are restricted to approved domains and APIs
This ensures:
Even if a credential is compromised, it cannot be used outside the controlled network boundary.
Isolation: No Shared Trust
We enforce strict isolation:
- Each connector runs in its own process
- No shared memory across connectors
- No mixing of trusted and untrusted components
This prevents:
- Cross-connector data leakage
- Supply chain attacks via co-resident tools
Logging and Detection: Identity-Centric Observability
Every action is traceable to a human identity:
- Logs include user identity (e.g., email/UPN)
- Resource logs link back to the same identity
- Credential fields are fully redacted
We also detect:
- Abnormal tool usage patterns
- Repeated authorization failures
- Off-hours access anomalies
- Excessive data access
Rate Limiting and Abuse Protection
To prevent misuse:
- Per-user rate limits
- Per-tool quotas
- Burst and sustained thresholds
This protects against:
- Enumeration attacks
- Resource exhaustion
- Agent misuse loops
Lifecycle Security: No Orphaned Access
We ensure clean access revocation:
- User disabled → access expires within policy window
- Optional Continuous Access Evaluation (CAE) for near real-time revocation
- Automated rotation of long-lived secrets (≤ 90 days)
From Guidelines to Enforcement: The Security Runtime
A key evolution in our approach was moving from documentation to enforcement.
We provide:
- A secure connector SDK
- Built-in middleware for:
- Authentication
- Token handling
- Logging and redaction
- Tool validation
- Policy enforcement
This ensures:
Security is not optional — it is the default.
Final Thoughts
AI agents are powerful — but they are also unpredictable.
Instead of trying to make agents "secure," we designed a system where:
- Secrets never reach the agent
- Authorization is enforced outside the agent
- All sensitive operations happen within a hardened boundary
- Even a compromised agent cannot escalate access
This is a shift in mindset:
From trusting intelligent systems → to containing them.
As AI continues to integrate deeper into production environments, this model — treating AI as an untrusted orchestrator — will be essential for building secure, scalable systems.