
A methodology writeup. No named targets, no live exploits — just how I think about who's allowed to touch what.
Most of the serious bugs I find aren't clever. They're just somebody forgot to check.
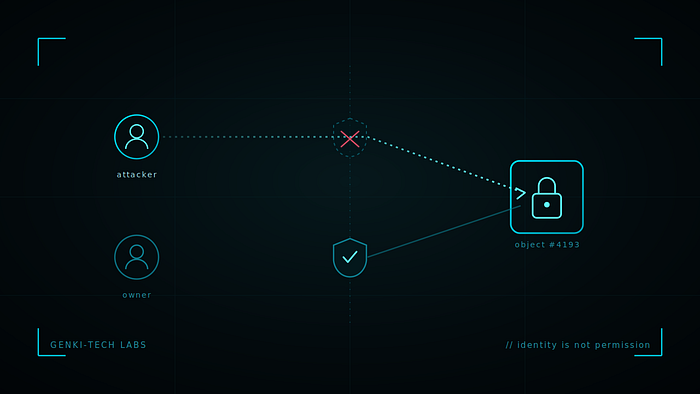
A request comes in. The server knows who you are — you're logged in, your session is valid. But it forgets to ask the second question: are you allowed to touch this specific thing? That gap, between authentication and authorization, is where broken access control lives. It's consistently one of the most common and most impactful bug classes in real applications, and it's almost never about breaking crypto or smashing a stack. It's about asking for something that isn't yours and watching the server hand it over.
This is a writeup about how I approach that hunt in general. No target, no product, no live chain — just the mindset and the loop. The toy examples are my own throwaway code, illustrating the class of mistake.
The mental model: identity is not permission
Every request that touches data is implicitly making two claims:
- "I am this user." — authentication
- "This user may perform this action on this object." — authorization
Frameworks make the first one easy. Logging in, session cookies, tokens — all solved problems, all handled by libraries everybody trusts. The second one is per-object, per-action, per-feature business logic that a human has to write correctly every single time, on every single endpoint. Nobody hands you that for free.
So the failure is structural, not exotic. The login works perfectly. The session is real. And then a handler does something like "fetch document #4193 and return it" without ever checking whether document #4193 belongs to you. The auth was real; the authz was missing.
Once you internalize that split, you stop looking for "vulnerabilities" and start looking for places where the second question wasn't asked.
The flavors of the bug
Broken access control wears a few different costumes. They're worth naming because each one suggests a different probe.
Object-level (IDOR). A request references an object by an identifier you can see and change — a numeric ID, a filename, a GUID. The server resolves the object but never checks ownership. Change the ID, get someone else's object. The classic.
Function-level. An action exists that your role shouldn't be able to perform — a delete, an export, an admin toggle — but the only thing stopping you is that the UI doesn't show you the button. The endpoint itself doesn't enforce the role. Hide the button, forget the guard.
Field-level / mass assignment. You're allowed to update an object, but the handler trustingly accepts every field you send — including ones you were never meant to set, like a role flag, an owner ID, or a quota. You update your profile and quietly include "role": "admin".
Context / state. An action is legitimate in one state but not another — approving something you also created, accessing a resource before you've been granted it, replaying a step out of order. The permission check exists but doesn't account for when or in what sequence.
The reason this taxonomy matters: when you find one endpoint with a missing check, the flavor tells you where else to look. A team that forgot ownership on one object reference very often forgot it on the neighbors too. Bugs travel in families.
The research loop
The discipline is the same as any hunt: boring, repeatable, and far more effective than cleverness.
1. Map the roles before the requests. A good access-control program gives you multiple accounts and multiple privilege tiers on purpose — a standard user, a restricted one, a recipient, a custom role. Before throwing a single malicious request, I build a mental matrix: which role can see what, do what, reach what. You can't find a missing boundary until you know where the boundary is supposed to be.
2. Establish two identities and a target object. The cleanest access-control proof needs three things: an attacker account, a victim account, and an object that demonstrably belongs to the victim. Create a document, a folder, a record as the victim. Note its identifier. Now you have a known-private thing to go reaching for.
3. Watch how the app talks to itself. Drive the feature normally as each role and watch the traffic. How are objects referenced — sequential integers, GUIDs, slugs, paths? Where do identifiers appear — URL, body, header, a nested JSON field? What does a legitimate request look like? You're building a vocabulary of the app's own object references so your probes look exactly like real traffic, just pointed somewhere they shouldn't go.
4. Form one falsifiable hypothesis. Not "this app has IDORs." Something testable: "I bet the document-fetch endpoint resolves the ID without checking ownership." One claim you can kill in one request.
5. Test the smallest swap. Authenticate as the attacker. Take the legitimate request. Change one thing — the object ID to the victim's, nothing else. Send it. The whole experiment is: does the server return the victim's object to the attacker? Keep everything else identical so the result is unambiguous.
6. If it's blocked, loop back — change the flavor, not the payload. A 403 is information: this endpoint checks ownership. Good. Now ask a different question. Is the check on the read but not the write? On the parent object but not the child? On the ID in the URL but not the duplicate ID in the body? Does a different role tier skip it? Spraying the same endpoint with ID after ID is procrastination. Moving to a different flavor of the missing check is progress.
7. Escalate to impact, then stop and measure. Reading one victim record proves the bug. But triagers and defenders care about blast radius. Can you enumerate — is the ID sequential, so the whole dataset is reachable? Does the bug expose read, or read and write? What's the most sensitive object class behind the same broken pattern? You walk that out carefully, demonstrate it cleanly, and stop the moment impact is proven. You don't hoard data, you don't pivot into other tenants' real records for fun, and you don't keep pulling once the point is made. Proving the door is unlocked does not require robbing the house.
8. No working PoC, no finding. This is the rule that keeps the whole thing honest. "This endpoint looks like it might not check ownership" is not a finding. A theory is not a finding. You either have a reproducible request that demonstrably returns or modifies something that isn't yours, or you have a hypothesis you haven't finished testing. Most programs will explicitly reject anything without an exploitable proof — and they're right to.
A toy example you can actually reason about
Here's a deliberately broken handler. Not modeled on any product — it just shows the shape of the mistake.
# The author's endpoint: fetch a document by ID.
@app.route("/api/documents/<int:doc_id>")
@login_required # <-- authentication: handled
def get_document(doc_id):
doc = db.documents.find(doc_id) # <-- resolves ANY id, for ANYONE
return jsonify(doc.to_dict()) # <-- no ownership checkWalk the author's reasoning. @login_required is right there — you can't hit this endpoint without a valid session. Feels guarded. And in a sense it is: the authentication is airtight. But the handler answers "I am a valid user" and never asks "is doc_id mine?" Any logged-in user can iterate doc_id and read every document in the system.
The legitimate request and the malicious one are byte-for-byte identical except the number. That's the signature of object-level access control failure — the attack doesn't look like an attack. It looks like normal use, aimed one inch to the left.
The fix is one line, and its plainness is the whole lesson:
@app.route("/api/documents/<int:doc_id>")
@login_required
def get_document(doc_id):
doc = db.documents.find(doc_id)
if doc.owner_id != current_user.id: # <-- the question that was missing
abort(403)
return jsonify(doc.to_dict())No new technology. No cryptography. Just asking the second question. And the reason the bug is so common is that this line has to be written correctly on every endpoint that touches an object — get it wrong, or forget it, in one place out of two hundred, and that one place is the bug.
That's also why bugs travel in families. If the author forgot the ownership check on get_document, there's a strong chance the same author, in the same sprint, forgot it on update_document, delete_document, and /api/documents/<id>/share. Find one, check the neighbors.
What I tell myself when it's not working
A 403 is a map pin. Every blocked request marks exactly where a real boundary lives. After enough of them you've drawn the perimeter — and the gap is almost always somewhere you assumed was fine and never actually tested.
The boring endpoints are the honest ones. Everyone hammers the obvious admin panel. The bug is more often in the sleepy little "download attachment" or "get notification" endpoint that nobody thought was interesting enough to guard.
Change the question, not the payload. Two requests blocked for the same reason means the third will be too. Don't try a hundred IDs against a checked endpoint — find an unchecked one, or a different flavor of check on the same one.
That's the whole method. Map the roles, hold two identities, learn the app's own object references, change one thing, and never call it a finding until the server actually hands you something that was never yours. The identifiers and the frameworks change every year. The missing second question doesn't.