

Discover the blueprint for slashing database snapshot times from days to hours using intelligent partitioning and AWS Aurora Fast Database Cloning.
Authors: Chandy Gnanasambandam (Staff Software Engineer, Tech Lead), Bhumika Bayani (Software Engineer), Sushil Thasale (Senior Software Engineer), Akashkiran Shivakumar (Software Engineer)
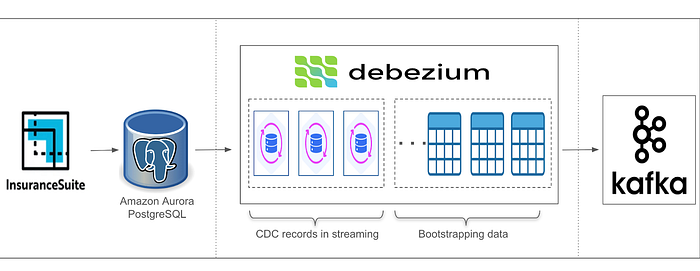
Modern data engineering enables real-time analytics, allowing global enterprises to instantly track every policy update and claim. Yet, real-time streaming often stalls due to the need for a complete, consistent historical data snapshot.
To trust a real-time stream, you must first reconcile it with the past, which requires migrating huge volumes of historical data from Aurora PostgreSQL. Traditionally, this snapshot is a multi-day ordeal that threatens production performance. In recent tests, we broke through this bottleneck: by re-engineering our bootstrap process, we cut snapshot time for a 7TB database from 68.5 to just 20 hours — a 70% reduction — with no performance impact on production. Here's how we did it.
The Dead Tuple Crisis: Why Scale Breaks Snapshots
To understand the solution, one must first understand why traditional extraction fails at the terabyte scale. In PostgreSQL, the primary antagonist is the Dead Tuple. Because of the Multi-Version Concurrency Control (MVCC) architecture, PostgreSQL does not immediately overwrite data when an UPDATE or DELETE occurs; instead, it creates a new version and marks the old one as "dead".
Normally, the VACUUM process scans and cleans them up, reclaiming space and maintaining index health. However, a long-running Debezium snapshot is considered a long-running transaction by the database. It holds a replication slot and pins the xmin horizon — the oldest transaction ID that the database must keep visible. As long as that snapshot is running, PostgreSQL cannot vacuum any dead tuples created after the snapshot started.
If a snapshot takes three days, you are effectively forbidding the database from cleaning itself for three days. This leads to three major issues:
- Table Bloat: Tables and indexes swell in size.
- Performance Degradation: Queries that used to take milliseconds now crawl as they navigate through mountains of dead rows.
- Resource Contention: The system begins to choke on its own history.
To solve this, we moved the "heavy lifting" entirely away from the primary instance.
The Solution: A Multi-Layered Architecture
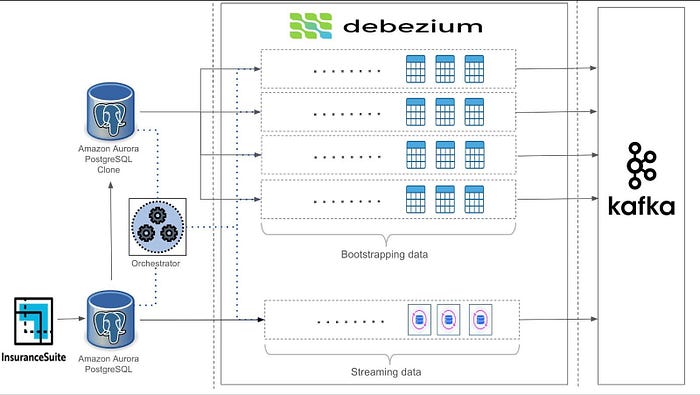
Our approach moves away from a single-threaded, primary-dependent snapshot. Instead, we combine database cloning, intelligent load balancing, and parallel execution orchestrated by a constraint-satisfaction engine.
While Lambda and Kappa architectures each have their pros and cons, we adopt a hybrid approach. Specifically, we use a custom, fine-tuned KafkaConnect platform to bootstrap the historical data. Once the initial load is complete, the same platform is reconfigured and optimized for streaming, ensuring continuous updates with minimal disruption.
1. Isolation via AWS Aurora Fast Database Cloning
To protect the primary database, we leverage AWS Aurora's Fast Database Cloning. Unlike traditional backups, this uses a Copy-on-Write (COW) mechanism to create an instantaneous clone of the production database that shares the same underlying storage.
By running the snapshot against the clone, we gain critical advantages:
- The long-running snapshot transaction is completely isolated.
- The primary database's xmin horizon remains mobile, allowing
VACUUMto work normally. - We create a "frozen" environment that guarantees data immutability during the bootstrap.
2. Overcoming Debezium's Parallelism Bottlenecks
While Debezium now supports parallel snapshotting threads, increasing thread count for a connector soon hits diminishing returns. This is mainly because Debezium uses a singleton queue and, in the PostgreSQL connector, only one task per instance is allowed.
To bypass these native constraints, we implemented Logical Partitioning. Instead of having a single connector handle everything, we split the database into N logical buckets and run a separate PostgreSQL connector for each.
3. AI-Powered Load Balancing with Timefold
Not all tables are created equal. If you have 100 tables and split them evenly across four connectors, you'll likely end up with one connector stuck on a massive 2TB "claims" table while the others finish in minutes.
To solve this, we integrated Timefold, an open-source AI-powered constraint-solving engine. By feeding Timefold metadata such as table sizes and row counts, we enable the engine to calculate an optimal data distribution. This results in each bucket holding approximately the same data volume, minimizing skew, balancing processing loads, and ensuring that all four connectors complete their tasks efficiently and in sync.
Precision Cutover: Preserving Data Integrity
The biggest risk of snapshotting a clone is the gap between when the clone is created and when you start streaming from production. How do you ensure no data is lost or duplicated?
Step 1: Capture the LSN
Before we even create the clone, we establish a replication slot on the production system. AWS provides the Log Sequence Number (LSN) at the exact moment the clone is created. This LSN is our source of truth; it tells us exactly where the snapshot ends and where the real-time stream must begin. You can retrieve this start LSN for the cloned database using the following query:
SELECT aurora_volume_logical_start_lsn();Step 2: Offset-Topic Seeding
To achieve a seamless handover, we use a technique called Offset Seeding. We manually update the Kafka offset topic for the Debezium connector. By pre-loading the LSN into the offset topic, we tell the connector that we already have everything up to this specific point in the transaction log, and it should start its capture from there. We push a message to the Debezium offset topic in the following format:
{
"transaction_id": null,
"lsn_proc": null,
"messageType": null,
"lsn_commit": null,
"lsn": "<numeric_representation_of_start_lsn>",
"txId": null,
"ts_usec": 1754012581660
}This approach ensures two primary benefits: seamless continuity between the snapshot and real-time capture, and strict preservation of data accuracy and consistency throughout the transition.
The Results: 70% Faster, 0% Slower
The impact of this architecture was immediate and transformative.
- Speed: By using 4 parallel connectors on a cloned instance, we reduced the boot time of a 7TB database from several days to just 20 hours. This acceleration enabled the team to quickly onboard new data pipelines in a single weekend, significantly improving project timelines.
- Cost Neutrality: Temporarily scaling up to four times the compute resources does not increase overall cost, thanks to a 70% shorter process duration. This makes the approach budget-friendly while accelerating delivery.
- Zero Production Impact: Offloading all intensive operations to the Aurora Clone ensures production workloads remain fully performant, eliminating the risk of business disruption.
The Road Ahead: Making it Resumable
Performance optimization is an iterative journey. We are now exploring Incremental Snapshots to make the bootstrapping process resumable. This ensures that even in a worst-case scenario, we don't lose the progress we've already made.
Furthermore, we are looking into Dynamic Scaling, building an orchestrator that analyzes the shape of the source database and automatically spins up the optimal number of connectors to maximize throughput.
How is your team handling massive CDC snapshots? Have you experimented with database cloning, or are you using a different workaround? Share your experiences in the comments below — let's optimize together.
If you are interested in joining our Engineering teams to develop innovative cloud-distributed systems and large-scale data platforms that enable a wide range of AI/ML SaaS applications, apply at Guidewire Careers.