


Apache Flink 2.2 delivers three major enhancements to Delta Join that transform it from a promising optimisation into a production-ready solution for real-world streaming pipelines. If you've been waiting for Delta Join to handle CDC sources, support caching or allow filter pushdowns: the wait is over.
This article covers what's new, why it matters, and how to put these capabilities into practice. If you're unfamiliar with Delta Join fundamentals, my previous article on Flink 2.1's Delta Join provides the architectural foundation.
Flink 2.2 addresses the most critical gaps in Delta Join's 2.1 implementation:
- CDC Upsert Support (FLINK-38511): Delta Join now accepts
UPDATE_AFTERrecords, making it usable with MySQL CDC, PostgreSQL CDC, and Debezium connectors - Built-in Caching (FLINK-38495): An integrated LRU cache reduces external storage lookups by 80–90% for typical workloads
- Filter and Projection Support (FLINK-38556): Deterministic filters and column projections can now be used by Delta Join, reducing data transfer and enabling new query patterns
Together, these changes enable Delta Join for the most common streaming use case.
Quick Recap
The core problem Delta Join solves is state explosion. In a traditional streaming join, Flink keeps both sides of the join in state, every customer record, every order, everything needed to match late-arriving data. A 10-million-row customer table with 30-day retention easily consumes gigabytes of state per TaskManager. Checkpoints slow down, recovery takes forever, and your cloud bill climbs.
Delta Join flips this model. Instead of storing data in Flink's state, it lives in external indexed store like Apache Incubating Fluss. When a stream record arrives, Flink performs an async lookup against Fluss rather than querying local state. The result? State drops by 99%+ for large dimensions.
CDC Upsert Support: The Game Changer
FLINK-38511 makes Delta Join usable for real-world database replication. This single enhancement transforms Delta Join from a niche optimization for INSERT-only tables into a practical solution for the most common streaming use case: bidirectional enrichment from CDC sources.
CDC sources define four types of row operations:
+I(INSERT) — New records added to the table-UB/+UA(UPDATE_BEFORE / UPDATE_AFTER) — Modifications to existing records-D(DELETE) — Records removed from the table
Flink 2.1's Delta Join could only handle INSERT operations from indexed lookup store like Fluss. Flink 2.2's code changes are deceptively simple but architecturally significant. In StreamingDeltaJoinOperator.java, the row kind validation evolved:
// Flink 2.1: INSERT-only
Preconditions.checkArgument(
RowKind.INSERT == element.getValue().getRowKind(),
"Delta join only supports INSERT records");
// Flink 2.2: INSERT + UPDATE_AFTER
Preconditions.checkArgument(
RowKind.INSERT == element.getValue().getRowKind() ||
RowKind.UPDATE_AFTER == element.getValue().getRowKind(),
"Currently, delta join only supports INSERT and UPDATE_AFTER records");What Delta Join now supports:
- ✅
INSERT (+I)— New dimension records - ✅
UPDATE_AFTER (+UA)— Updated dimension values - ❌
UPDATE_BEFORE (-UB)— Automatically dropped - ❌
DELETE (-D)— Not supported (by fundamental design)
Why UPDATE_BEFORE is Automatically Dropped
You might wonder: if Delta Join supports UPDATE_AFTER, why not UPDATE_BEFORE? The answer lies in the stateless design:
- No Join State to Retract: Delta Join doesn't maintain a table of join results in state. When an UPDATE arrives, there's no previous join result to retract , the operator simply performs a fresh lookup.
- UPDATE_AFTER is Sufficient: When a dimension record updates from
{id=1, name="Alice"}to{id=1, name="Alice2"}, the CDC stream produces-UB(id=1, name="Alice")followed by+UA(id=1, name="Alice2"). The+UAimplicitly replaces the old value in the dimension table's indexed storage. - Downstream Idempotency: The enriched results flow to an idempotent sink (typically with a primary key), which naturally handles the update by overwriting the previous row.
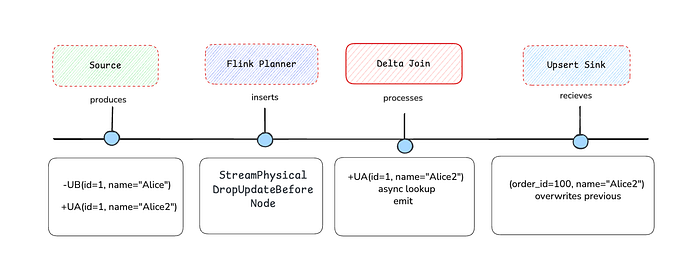
The StreamPhysicalDropUpdateBefore node is automatically inserted during query optimization, you never see it in your SQL, but it's there in the execution plan, silently removing unnecessary retractions.
Why DELETE Still Isn't Supported
This isn't a TODO item, it's a fundamental architectural constraint.
No State for Retraction: To properly handle DELETE, Delta Join would need to remember what it previously emitted so it can retract the correct join result. But maintaining this state defeats the entire purpose of Delta Join and we'd be back to a regular stateful join with all its memory overhead.
The code in DeltaJoinUtil.java makes this explicit:
private static boolean onlyProduceInsertOrUpdateAfter(StreamPhysicalRel node) {
ChangelogMode changelogMode = getChangelogMode(node);
Set<RowKind> allKinds = changelogMode.getContainedKinds();
return !allKinds.contains(RowKind.UPDATE_BEFORE)
&& !allKinds.contains(RowKind.DELETE);
}This validation isn't commented as "TODO: support DELETE.", it's a design invariant for now.
The standard workaround is soft deletes. When a customer is "deleted," CDC produces +UA(id=123, deleted=true), which Delta Join handles perfectly. Downstream analytics can filter on the deleted flag, and you maintain a complete audit trail.
CDC support makes Delta Join usable. But Flink 2.2 also makes it fast. Two complementary enhancements: built-in caching and filter/projection support combine to deliver speculatively 2-5x performance improvements over the 2.1 baseline.
Built-in Caching Layer (FLINK-38495)
Every external lookup has cost: network round-trip, storage I/O, serialization overhead. In Flink 2.1, every stream record triggered a lookup, even if the same dimension key was looked up milliseconds earlier. For skewed workloads (hot customers, popular products), this meant repeatedly fetching the same data.
Flink 2.2 introduces an integrated LRU cache that sits between the Delta Join operator and external storage. The implementation in DeltaJoinCache.java uses Guava Cache with a two-level structure:
// Dual-sided caching (one for left lookups, one for right)
private final Cache<RowData, LinkedHashMap<RowData, Object>> leftCache;
private final Cache<RowData, LinkedHashMap<RowData, Object>> rightCache;Why this structure?
- Outer Cache: Maps join key → inner map (O(1) lookup by join key)
- Inner LinkedHashMap: Maps upsert key → row data (handles multiple rows per join key)
- LRU Eviction: Automatically manages memory when cache reaches configured size
The inner map is crucial for handling dimension updates. When customer_id=123 updates, the cache upserts the new value in-place for that upsert key, ensuring lookups always see the latest data until LRU eviction.
Configuration:
table.exec.delta-join.cache-enabled: true # Default
table.exec.delta-join.left.cache-size: 10000 # Max cached join keys
table.exec.delta-join.right.cache-size: 10000Metrics to Monitor:
deltaJoin.leftCache.hitRate # Target: >80%
deltaJoin.leftCache.requestCount # Total lookups attempted
deltaJoin.leftCache.hitCount # Successful cache hits
deltaJoin.leftCache.keySize # Distinct join keys cached
deltaJoin.leftCache.totalNonEmptyValues # Total cached rowsWatch the hit rate. If it's below 70%, either increase cache size or investigate data skew (if lookups are uniformly distributed across millions of keys, even a large cache won't help and that's a sign Delta Join might not be the right fit).
Filter and Projection Support (FLINK-38556)
Projections genuinely reduce data transfer: Delta Join fetches only the columns you specify from Fluss. Filters work differently: they're applied in Flink after the lookup returns data. The rows still get fetched from Fluss; they just get filtered before joining.
Projection (the real win)
SELECT o.*, c.name, c.tier
FROM orders o
JOIN (
SELECT id, name, tier FROM customers -- 3 columns instead of 20
) c ON o.customer_id = c.id;The projectionOnTemporalTable field in DeltaJoinSpec specifies which columns to fetch. Fluss returns only the requested columns. For wide dimension tables, this cuts network I/O and cache memory by 50–80%.
Filters (applied post-lookup)
Flink 2.2 allows exactly one Calc node between the source scan and Delta Join. Filters extracted from this node are applied in Flink after the lookup via a generated FlatMapFunction in AsyncDeltaJoinRunner. Data still gets fetched from Fluss, filtering just reduces rows before joining.
For CDC sources, filters must reference only upsert key columns.
Why this restriction? Delta Join can emit duplicates because CDC updates on either side trigger fresh lookups against the opposite table and any in-flight async operations get replayed after checkpoint recovery. For upsert key columns (which determine record identity), values are stable, so filtering on them is safe. For non-upsert-key columns, values can change between duplicate emissions, leading to inconsistent results:

For INSERT-only sources, filter on any column as no updates means no inconsistency.
All filters must be deterministic. RAND(), NOW(), CURRENT_TIMESTAMP() are rejected because duplicate emissions would produce different results.
There's a separate concept that can cause confusion: some connectors support FilterPushDownSpec, which actually pushes filters to the storage layer. This is orthogonal to FLINK-38556. When a connector like Fluss supports this capability, Delta Join validates that those pushed filters also follow the upsert key restriction for CDC sources.
Correctness and changelog requirements on upstream data sources go beyond Delta Join and open up a larger conversation related to generic Join semantic. That's outside our scope here, but FLINK-38579 provides a good entry point.
Caching reduces lookup frequency by 80–90%. Projection reduces data transfer by 50–80%. Filters reduce rows processed in Flink (but don't reduce data fetched from Fluss unless the connector supports FilterPushDownSpec). Together, these make Delta Join significantly faster than 2.1.
Design Tradeoffs and Limitations
Delta Join's performance comes with constraints. Understanding these limitations and why they exist as it's critical for deciding when to use this optimization.
Indexing
Delta Join will not apply without proper indexing. The validation logic in DeltaJoinUtil.java checks that join keys completely cover at least one index or prefix of it defined in Fluss.
Delta Join performs thousands of lookups per second against external storage. Without indexes, each lookup becomes a full table scan turning an O(1) indexed lookup into an O(n) sequential scan. For a million-row dimension table, that's the difference between 1ms and 1000ms per lookup.
Only INNER JOIN
This isn't a limitation to be worked around as it's an architectural invariant. LEFT, RIGHT, and FULL OUTER joins are fundamentally incompatible with Delta Join's stateless design.
The problem with LEFT JOIN:
T0: Order for customer_id=999 arrives
→ Async lookup → customer 999 not found in dimension table
→ LEFT JOIN semantics: emit (order_data, NULL, NULL, NULL)
T5: Customer 999 is added to dimension table
→ Should we now emit (order_data, customer_name, customer_tier, ...)?
→ But how do we retract the previous (order_data, NULL, NULL, NULL)?
Fundamental issue: No state tracking what was emitted previouslyDelta Join doesn't maintain join results in state (that's the whole point inavoiding state!). For INNER JOIN, unmatched rows are simply skipped, so no NULL emission, no retraction needed. For LEFT JOIN, unmatched rows must be emitted with NULL padding, and if that dimension record appears later, we'd need to retract the NULL emission and emit the matched result. This requires state.
From DeltaJoinUtil.java:
public static boolean isJoinTypeSupported(FlinkJoinType flinkJoinType) {
return FlinkJoinType.INNER == flinkJoinType;
}If you need LEFT JOIN semantics, use a regular stateful join as the state cost is unavoidable for correctness.
The Idempotency
Perhaps the most critical constraint: downstream operators must handle duplicate records idempotently. I mentioned this in previous section.
If downstream can't handle seeing (order_id=100, customer_name='Alice') twice, the pipeline breaks.
Bad: Append-only sinks
CREATE TABLE kafka_results (
order_id INT,
customer_name STRING
) WITH ('connector' = 'kafka', 'format' = 'json');
-- Kafka consumers will see duplicate records!
INSERT INTO kafka_results
SELECT o.id, c.name FROM orders o
JOIN customers c ON o.customer_id = c.id;Good: Upsert sinks
CREATE TABLE kafka_results (
order_id INT PRIMARY KEY NOT ENFORCED,
customer_name STRING
) WITH (
'connector' = 'upsert-kafka',
'key.format' = 'json',
'value.format' = 'json'
);
-- Duplicates merged by primary key → idempotent
INSERT INTO kafka_results
SELECT o.id, c.name FROM orders o
JOIN customers c ON o.customer_id = c.id;What qualifies as idempotent:
- Upsert sinks (Fluss KV table, Kafka with upsert mode, JDBC with primary key, lake tables, StarRocks PK tables)
- Stateless transformations (map, flatMap without side effects)
- Any other sink that deduplicates by key
If your downstream processing is append-only or has side effects (incrementing counters, triggering alerts), Delta Join will cause correctness issues.
Filters limitations
We covered this in the filter section, but it's worth emphasizing: for CDC sources, filters must reference only upsert key columns, otherwise Flink falls back to a regular stateful join.
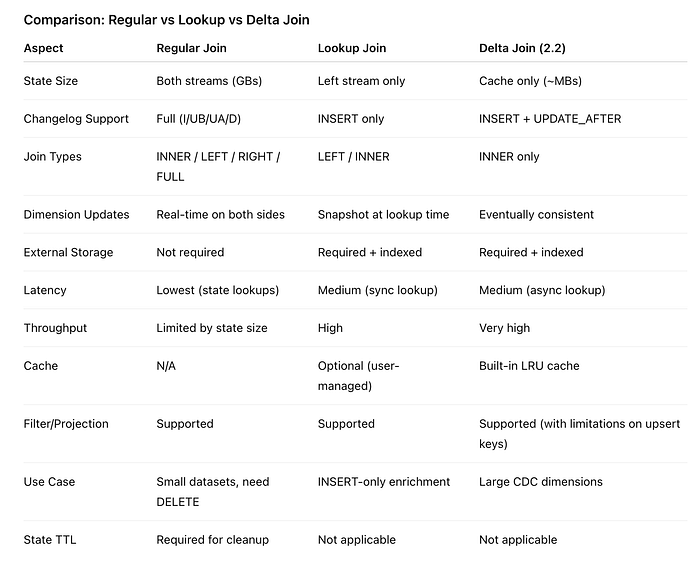
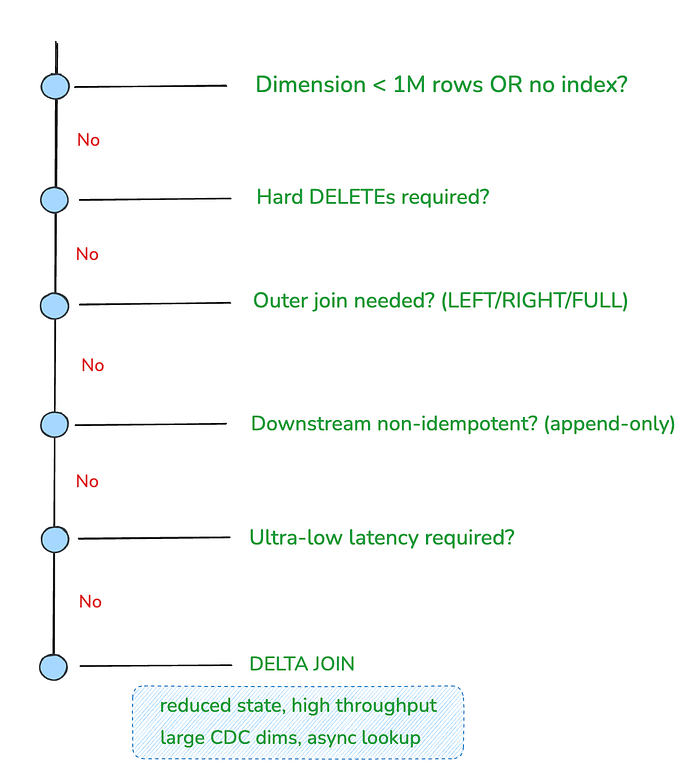
How to choose now?
Closing Thoughts
Apache Flink 2.2 transforms Delta Join from a promising optimization into a viable solution for real-world streaming pipelines.

Delta Join isn't universal. INNER JOIN only, no DELETE support, mandatory indexes and the downstream idempotency requirement aren't limitations to be worked around. They're fundamental architectural tradeoffs. The optimization trades flexibility (no outer joins, no hard deletes) for efficiency (99% state reduction, 10x throughput).
For organizations processing millions of streaming events against large reference data, Flink 2.2's Delta Join can reduce state by 99%, cut infrastructure costs significantly, and improve throughput by an order of magnitude, all while handling real-world CDC patterns that were impossible in 2.1.