


As analytics ecosystems grow more diverse, organisations increasingly need to query data across warehouses, data lakes, and operational systems without excessive data movement or duplication. Query federation has become essential by enabling unified SQL access and intelligent predicates pushdown into heterogeneous sources.
This article introduces the core principles of federation and why it matters for modern OLAP workloads. Using StarRocks as a model system, we highlight its vectorised execution engine, native connectors, and deep Apache Iceberg integration that together deliver high-performance lakehouse querying. We examine common lakehouse challenges — e.g. schema evolution, file fragmentation, and object-storage latency — and show how federation and hot/cold data separation help address them. Finally, we explore federating additional sources such as Elasticsearch, PostgreSQL, and Apache Paimon to build a unified analytical architecture.
High Level Overview
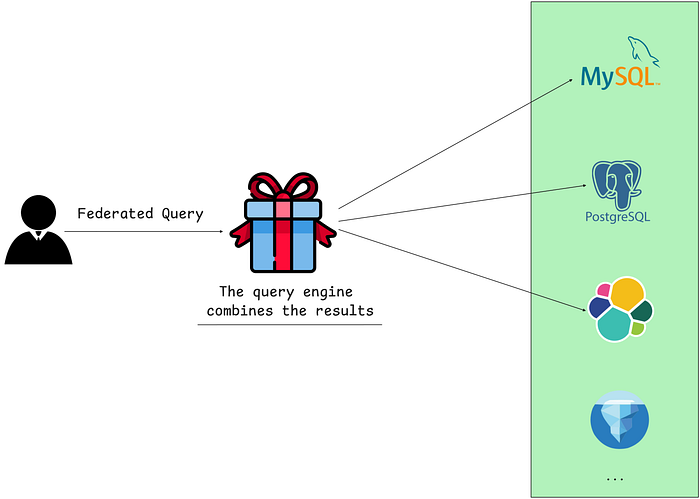
Query federation refers to the ability to query data across multiple, heterogeneous data sources as if they were a single, unified system, without needing to physically move or replicate the data. By reducing the need complicated ETL pipelines to consolidate the everything into a single data source, data architectures are vastly simplified, insights can be driven faster, and cloud costs are kept in check.
When executing a federated query, engines typically break it into sub-queries for each data source, determine what operations can be pushed down to the source systems (filters, aggregations, joins), execute these plans in parallel, and then combine the results locally. But all of this doesn't come without challenges: data access patterns, network limitations, security policies and performance that's difficult to predict.
Historically, query federation has evolved from the initial database "gateways" in the 1980s-90s, that only allowed direct access to remote tables, to the enterprise middlewares of the 2000s, and to the big-data era of 2010s when systems like Hadoop and Presto pioneered true federated query engines. In fact, it is the release of Presto at Facebook in 2013 that is considered the most important breakthrough that turned federation from an academic, niche idea into a proper, production-grade capability for OLAP workloads.
More recently, cloud platforms brought it into the mainstream by separating storage and compute. And today's lakehouse architectures with open table formats have finally made federation fast enough for real time analytics use-cases, allowing data to stay distributed while still being queryable as a unified system.
Two philosophies
Query federation engines tackle unified SQL access in different ways, depending on which trade-offs they prioritise. Some are designed as general-purpose federation layers, optimising for flexibility, predicates pushdown, and access to as many sources as possible, while others embed federation within a high-performance analytical database, prioritising low latency and predictable execution. To illustrate these contrasting approaches, let's focus on two engines — Presto/Trino and StarRocks — which implement query federation based on fundamentally different philosophies.
Trino: Federation as a First-Class, Global Query Layer
Trino is designed from the ground up as a general-purpose federated SQL engine, where querying external systems is the default rather than an exception. Its query planner and optimiser treat federation as a first-class concern, deciding not only how to execute a query, but where each part of it should run. Computation is aggressively pushed down into source systems when possible, and Trino stitches together partial results into a unified result set. This makes Trino particularly strong in heterogeneous environments, where data lives across many different systems with varying capabilities.

A key strength of Trino lies in its connector ecosystem and metadata model. With support for dozens of data sources — ranging from relational databases and data warehouses to object stores, NoSQL systems, and streaming platforms — Trino mirrors source metadata closely and remains capability-aware. Its optimiser operates with incomplete or approximate statistics sourced from remote systems and relies on heuristics to account for network transfer and remote execution costs. As a result, Trino emphasises flexibility and breadth of access, accepting some uncertainty in exchange for being able to federate across virtually anything.
At execution time, Trino behaves largely as a distributed query orchestrator. Stateless workers coordinate tasks, exchange intermediate results, and perform joins and aggregations across system boundaries. Data movement and shuffling are fundamental to its execution model, and performance is driven by parallelism and efficient coordination rather than locality. Trino does provide limited caching support, but it usually operates at the file or metadata level. It is typically connector-specific, node-local, and managed independently on each worker. This can lead to inconsistent cache hit rates. Trino also lacks a built-in query-result cache, so repeated analytical queries are often re-executed unless external caching layers or downstream systems are introduced.
StarRocks: Federation as an Extension to an Internal OLAP Engine
In contrast, StarRocks approaches query federation from a fundamentally different angle. Rather than acting as a universal query layer, StarRocks is first and foremost a high-performance OLAP database, where federation serves as a complementary capability. External data is integrated as another data source within the engine, normalised into StarRocks' internal metadata and execution model, so that it behaves as if it were local. This allows the same optimisations, management policies, and governance mechanisms to apply uniformly across both internal and external data.
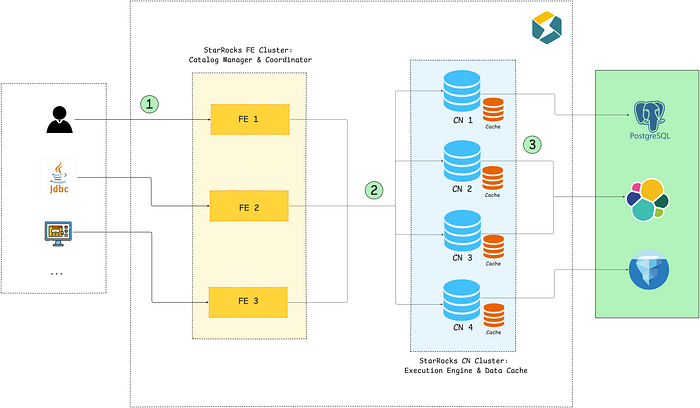
The diagram below highlights how a federated query gets executed in this model:
- The query reaches one of the FE nodes of the StarRocks cluster — this node will serve as the coordinator for the query. It will parse the SQL statement, analyse it for semantic correctness and then generate an execution plan using the built-in Cost Based Optimiser (CBO).
- The execution plan is distributed to backend/compute nodes (CN) for the actual execution.
- The CNs execute the received plan fragments in parallel, read data from internal or external storage and exchange results with other CNs if necessary. While reading the data, they populate their cache blocks.
In the end, the final results are collected by the coordinator FE node and returned to the client.
The optimiser in StarRocks is tightly coupled to this model. It builds and maintains detailed statistics over time, enabling precise decisions around join ordering, data distribution, and execution strategies. Instead of embracing uncertainty, StarRocks favours predictability and stability, prioritising plans that minimise remote reads, avoid unnecessary data movement, and deliver consistently low latency. Federation is therefore optimised around reducing external I/O and pulling only the minimum necessary data into the engine.
Execution in StarRocks is driven by a vectorised, MPP pipeline optimised for efficient resource usage and repeated analytical workloads. Techniques such as local execution, colocated joins, broadcasting small tables, caching, and materialised views are central to its design. Unlike Trino, StarRocks treats caching and pre-aggregation as core features, allowing it to shield users from variability in upstream systems while reducing cost and improving performance. From a user and governance perspective, external data is managed and secured as if it were internal, reinforcing the illusion of a single, coherent analytical system.
In a nutshell: Trino is a federation-native query orchestrator, which queries data where it lives, whereas StarRocks is an OLAP engine that treats federation as an extension of its execution pipeline.

Iceberg Federation
Now we talked a lot about query federation in general, from a philosophical perspective, but what does it all mean in practice? How does one compare and contrast the two approaches to query federation, in order to choose a suitable engine for their requirements? After all, real world architectures are not built on top of viewpoints only.
One of the most compelling use cases for query federation is querying data lakes built on open table formats. This is because the industry is shifting towards storage and compute separation. In such architectures, data is ingested once into low-cost cloud object storage and reused across many workloads, including analytics, reporting, and AI/ML pipelines. Storage and compute are deliberately decoupled: data lies in systems such as AWS S3 in an open table format, while compute is provisioned on demand to process it. This separation keeps storage costs low, allows compute to scale elastically with workload demands, and significantly simplifies the overall data architecture.
A data lake can be built on top of any open table format, but one that emerged as the widely adopted in the industry is Apache Iceberg, in part due to its open specification and wide adoption by big companies, such as Netflix, Snowflake, or Confluent. That is why query engines that integrate well with Iceberg are expected to also see a wide adoption in the future.
But Iceberg is just a series of manifest lists and manifest files that point to the actual data files. Metadata files do keep pointers to table and partition statistics (usually Puffin files) for enhanced performance, but readers (query engines) need to understand and use them.
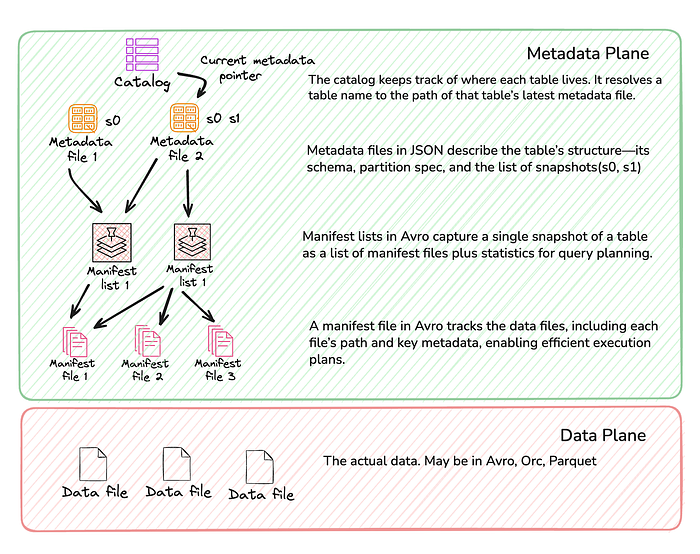
The performance of querying an Iceberg table is primarily driven by how efficiently a query engine can navigate table metadata to locate the relevant data files, how many of those files ultimately need to be opened, and how effectively predicates and partition pruning are applied to minimise that set. Efficient metadata access and caching are critical, as every query relies on metadata scans to avoid unnecessary file reads.
Moreover, as data gets ingested into Iceberg tables, the number of underlying files grows rapidly. When these files remain small and fragmented, each query pays the price by opening and scanning far more objects than necessary, increasing latency and storage overhead. This small files problem makes ongoing table maintenance — such as compaction — critical for keeping data lakes performant.
The small files problem affects all engines querying Iceberg tables, but it manifests differently in Trino vs. StarRocks. Trino typically scans Iceberg tables directly in object storage and must pay the cost of opening and reading many small files at query time, making performance highly sensitive to table maintenance. StarRocks, by contrast, mitigates this overhead through metadata caching, local execution, and optional materialisation and compaction strategies, reducing the impact of fragmented file layouts on query latency.
StarRocks also has another lever for alleviating this remote object storage cost — via strategies such as hot / cold data separation, where the most recent data is streamed into internal StarRocks tables in real time and older data gets tiered to Iceberg and only queried if needed. As a bonus, this technique also enables realtime analytics out of the box and a full streamhouse architecture backed by a single system — StarRocks. Since Iceberg itself is not yet optimised for realtime ingestion (as it only exacerbates the small files problem mentioned above), the newest data must be served from a separate source that is performant for streamed data loading. In contrast, with Trino, realtime analytics would only be viable if we were to also federate to Kafka or an OLTP data source.
Let's see how this would look like in practice, through experiments that we have tried out at Fresha. Integrating an external Iceberg catalog into our StarRocks cluster allowed us to:
- leverage existing models from Snowflake for use cases that allowed relaxed data freshness. We just exported tables from our warehouse in Iceberg, and read them in StarRocks, providing clients with a unified SQL access.
- improve query latency for our realtime reports and analytics via hot / cold data separation.
StarRocks Iceberg Integration
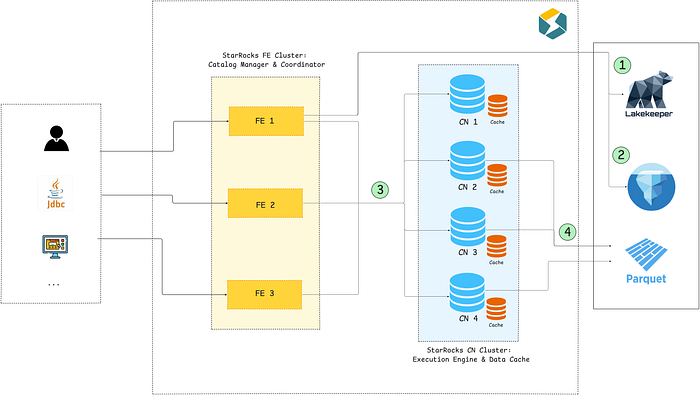
Let's dig deeper into StarRocks — Iceberg integration, which enables direct access to the data lake, treating Iceberg tables as if they were native. But before moving into queries and data modeling, it would be useful to take a step back and understand exactly how StarRocks queries Iceberg data in the first place. The process comprises of two steps:
Metadata Planning
- StarRocks reads the current snapshot ID, which points to the table's metadata location
- From there, it reads the manifest list, which references the manifest files
- Then it performs pruning based on metadata, ignoring the files that are not needed for the query
- The remaining data files are compiled into a query plan and the work is distributed to compute nodes (CN) for the actual execution
Distributed Execution
- Each node fetches the assigned data files from remote storage
- StarRocks' vectorised execution engine reads the data in a columnar fashion
- Filters that could not be evaluated during the metadata planning phase (such as filters on non-partition columns etc) are pushed down to storage, minimising data reads
- Finally, it handles position and equality delete files to ensure transactional correctness.
A series of optimisations were added to make queries as efficient as possible and reduce network I/O. Firstly, metadata is cached in both memory and disk, avoiding repeated fetches from remote storage. Both caches use a LRU (Least Recently Used) eviction policies, ensuring that the most relevant metadata remains available.
Secondly, StarRocks automatically chooses the best way to retrieve metadata depending on the size and complexity of the query, using a so-called adaptive metadata retrieval strategy. For large queries, it distributes the tasks of reading, decompressing and filtering manifest files across multiple CN nodes, speeding up execution via parallelism. For small volume of metadata files, StarRocks caches deserialised memory objects to bypass repeated decompression and parsing.
Lastly, metadata can be refreshed asynchronously, via a polling mechanism that checks the metastore for updates to Iceberg tables that are frequently accessed. These tasks only continue in the background for as long as the tables get accessed, preventing unnecessary polling for unused tables.
For a more in depth analysis of the StarRock I/O model, this article from StarRocks engineering explains the concepts quite intuitively. Also, my colleague Anton Borisov dived into the source code to resurface how StarRocks handles Iceberg's merge-on-read (MoR) and how it deals with deletes.
We were mentioning earlier how the query engines rely heavily on table statistics, and this is obviously applicable to StarRocks. One issue we had to deal with at Fresha in the beginning was sub-par performance when reading Iceberg tables in certain scenarios. In fact, we even managed to get segmentation faults on our CN nodes (see Github issue), affecting users and increasing the latency for all our queries 😢.
Upon investigation, we realised the following:
- The only affected tables were the ones we were exporting from Snowflake directly into Iceberg using an externally managed catalog-linked database.
- These tables were missing parquet page indexes, and null value count statistics (NVC).
- Since StarRocks relies on these statistics by default (configurable via
enable_parquet_reader_page_indexsystem variable), it would just crash when trying to dereference a null pointer. - To workaround this problem we decided to rely on Spark as Iceberg writer (which includes page indexes by default since version 3.x), rather than disabling page index optimization when reading parquet files. We didn't want to pay the performance penalty here.
We provided a fix for the issue and it will be available in the future StarRocks versions 🎉.
Iceberg Catalog setup
Setting up an external Iceberg catalog in StarRocks is as simple as executing a couple of SQL commands. We are using an Iceberg REST catalog — Lakekeeper in our case — but there are multiple examples in the official documentation for how to setup different types of Iceberg catalogs.
CREATE EXTERNAL CATALOG lakekeeper
PROPERTIES (
"type": "iceberg"
"aws.s3.region": "us-east-1"
"aws.s3.endpoint": "https://s3.us-east-1.amazonaws.com"
"aws.s3.path_style_access": "false"
"aws.s3.use_aws_sdk_default_behavior": "true"
-- Iceberg catalog configuration
-- REST Catalog with vended credentials
"iceberg.catalog.type": "rest"
"iceberg.catalog.uri": "{{ ssm_param.lakekeeper_endpoint }}"
"iceberg.catalog.security": "oauth2"
"iceberg.catalog.oauth2.scope": "lakekeeper"
"iceberg.catalog.oauth2.server-uri": "{{ ssm_param.keycloak_token_endpoint }}"
"iceberg.catalog.oauth2.credential": "{{ ssm_param.client_id }}:{{ ssm_param.client_secret }}"
"iceberg.catalog.rest.nested-namespace-enabled": "true"
"iceberg.catalog.warehouse": "{{ environment }}"
-- Metadata cache settings
"enable_iceberg_metadata_cache": "true"
"enable_iceberg_metadata_disk_cache": "true"
"iceberg_metadata_cache_expiration_seconds": "1800"
"iceberg_metadata_memory_cache_expiration_seconds": "1800"
);Once configured, you should be able to access the remote databases and tables. However, it goes without saying: privileges on external catalogs for users need to be granted just as for any other database object. Fortunately the documentation is also comprehensive here and includes best practices for customising role-based access for various scenarios.
mysql> show databases in lakekeeper;
+---------------------+
| Database |
+---------------------+
| information_schema |
| remote_iceberg_data |
+---------------------+
2 rows in set (0.120 sec)
mysql> show tables in lakekeeper.remote_iceberg_data;
+----------------------------------------------------------+
| Tables_in_remote_iceberg_data |
+----------------------------------------------------------+
| snowflake__partners_reporting__location_all_time_metrics |
| snowflake__partners_reporting__location_daily_metrics |
| snowflake__partners_reporting__occupancy_employee_recent |
| ... |Once setup, we can actually query the remove Iceberg data. The queries are quite fast.
SELECT count(*)
FROM snowflake__partners_reporting__location_all_time_metrics
WHERE provider_id = 604262;
+----------+
| count(*) |
+----------+
| 55 |
+----------+
1 row in set (0.317 sec)Inspecting the plan
As mentioned above, the external Iceberg catalog allowed us to leverage some of the models from Snowflake, which we just exported to Iceberg. This fit well into those use cases where the realtime constraints were not too restrictive: for example for daily / monthly reports. Sure, we could have asked clients to read directly from Snowflake, but this is not strictly necessary — we can hide all that complexity behind a unified SQL interface (and also Snowflake doesn't handle well the query concurrency of user-facing reports). These models were reused to enrich internal data already in StarRocks with all time statistics and occupancy metrics.
To inspect and reason about the plans below, we used our own query visualisation tool, developed in-house: NorthStar. It can be accessed here.
In short, clients could just run:
mysql> SELECT *
-> FROM perf_drawer_occupancy_employee_tab_month
-> WHERE provider_id = 604262;
300 rows in set (0.858 sec)Underneath it is just a view that joins the metrics we gathered from Snowflake with the dimensional data from internal tables.
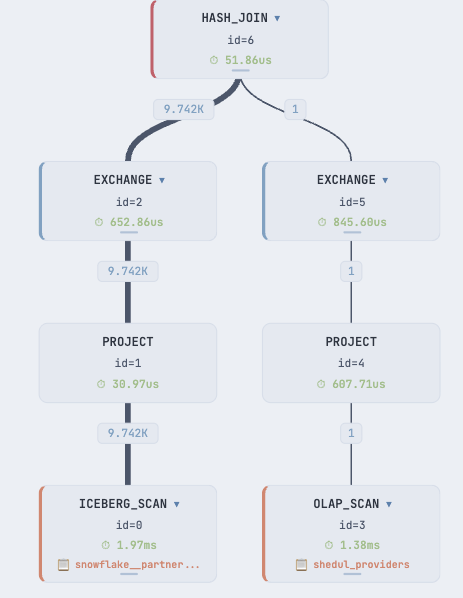
Inspecting the query (explain verbose) and focusing on the Iceberg fragment, we get the following plan:
| 0:IcebergScanNode
| TABLE: remote_iceberg_data.snowflake__partners_reporting__occupancy_employee_recent
| PREDICATES: 145: provider_id = 604262
| MIN/MAX PREDICATES: 145: provider_id <= 604262, 145: provider_id >= 604262
| cardinality=81
| avgRowSize=89.0
| dataCacheOptions={populate: true}
| partitions=1/1
| Iceberg Scan Metrics:
| {
| "table-name":"lakekeeper.remote_iceberg_data.snowflake__partners_reporting__occupancy_employee_recent",
| "snapshot-id":2418576845940344305,
| "filter":{"type":"eq","term":"provider_id","value":"(hash-0f307c8d)"},
| "schema-id":0,
| "projected-field-ids":[1,2,3,4,5,6,7,8],
| "projected-field-names":["occupancy_employee_pk","calendar_date","provider_id","location_id",...],
| "metrics":{
| "total-planning-duration":{
| "count":1,
| "time-unit":"nanoseconds",
| "total-duration":163733626},
| "result-data-files":{"unit":"count","value":17},
| "result-delete-files":{"unit":"count","value":0},
| "total-data-manifests":{"unit":"count","value":2},
| "total-delete-manifests":{"unit":"count","value":0},
| "scanned-data-manifests":{"unit":"count","value":2},
| "skipped-data-manifests":{"unit":"count","value":0},
| "total-file-size-in-bytes":{"unit":"bytes","value":1207339764},
| "total-delete-file-size-in-bytes":{"unit":"bytes","value":0},
| "skipped-data-files":{"unit":"count","value":15},
| "skipped-delete-files":{"unit":"count","value":0},
| "scanned-delete-manifests":{"unit":"count","value":0},
| "skipped-delete-manifests":{"unit":"count","value":0},
| "indexed-delete-files":{"unit":"count","value":0},
| "equality-delete-files":{"unit":"count","value":0},
| "positional-delete-files":{"unit":"count","value":0},
| "dvs":{"unit":"count","value":0}},
| "metadata":{"iceberg-version":"Apache Iceberg 1.10.0 (commit 2114bf631e49af532d66e2ce148ee49dd1dd1f1f)"}}
| cardinality: 81
| probe runtime filters:
| - filter_id = 0, probe_expr = (145: provider_id)What we can see from the plan above:
- StarRocks relies heavily on Iceberg table statistics
- It skips manifest files that are not needed for the query
- Predicates are pushed down to Iceberg to limit data transfers
- Projections are applied early
- Datacache is populated while the query runs
All these optimisations make StarRocks blazingly fast when querying Iceberg tables (provided it has the necessary parquet page indexes 😅).
Other External Catalogs
StarRocks supports a varied list of external systems and open table formats that can be brought into the same OLAP engine and queried as if they were internal tables.
We already explored our Elasticsearch integration in the past and are planning to continue on this path with more experiments on Apache Paimon in the future — so stay tuned.
As we have seen, StarRocks offers the full advantages of a data lakehouse architecture backed by open table formats:
- separation of storage and compute with elastic scalability
- standardisation across disparate data sources (though the list is not as rich as it is for Trino). Being able to federate to Snowflake directly would be nice. 😁
- realtime ingestion into internal tables, while colder data stays in cheaper cloud storage
- cost effectiveness by limiting repeated scanning of remote files via flexible caching mechanisms
All of this enables teams to build a unified and performant analytical architecture.
Wrapping it up
In this article we explored query federation in general, before diving into how StarRocks implements unified SQL access in a fundamentally pragmatic way. By pulling federation into the heart of its compute engine — making remote data local, caching metadata aggressively, and relying on a high-performance OLAP runtime — StarRocks solves many of the hardest federation challenges with an elegant, cost-efficient real-time analytics architecture.
While orchestrating distributed SQL queries is certainly nice to have in your toolbox for interactive exploration and ad-hoc exploration, actually putting analytical workflows in production for thousands of concurrent users requires the kinds of optimisations that StarRocks provides out of the box.
This article is only the starting point of our journey with Iceberg. Its goal was to introduce the core concepts and tradeoffs behind federated query engines and data lake architectures. In the next articles, we will focus on more concrete implementation details: how we split data into hot and cold tiers, how we chose our partitioning strategy, how data is tiered into Iceberg. We will also cover how we handle hard deletes, how we redesigned our models to deduplicate data across layers, and how we preserve data contracts while evolving schemas over time. Stay tuned!
Credits
Huge thanks to Anton Borisov, Emiliano Mancuso and Samuel Valente for reviewing drafts of this article. 😊