
Anthropic dropped Opus 4.6 on February 5, 2026. Your feed is already drowning in benchmark screenshots and hot takes. Terminal-Bench record. ARC AGI doubled. Context window tripled.
Here's the thing: none of that tells you what to actually do on Monday morning.
Should you migrate your production agents? Rewrite your thinking configuration? Rethink your RAG pipeline now that 1M tokens of context actually works? Or is this another incremental bump you can safely ignore for three months?
The answer depends on one change that most coverage is burying under benchmark tables: Opus 4.6 fundamentally changed how it reasons. And that changes how you build with it.
Let's cut through the noise.
Before we start!🦸🏻♀️
If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!) — Medium's algorithm favors this, increasing visibility to others who then discover the article. 🔔 Follow me on Medium , LinkedIn and subscribe to get my latest article.
TL;DR
If you're short on time, here's what matters:
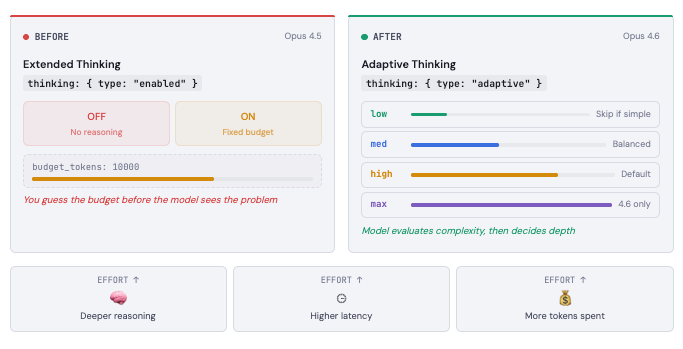
- Adaptive thinking replaces extended thinking. The model now decides when and how deeply to reason. You stop guessing
budget_tokens. This is the biggest architectural shift. - Four effort levels give you real cost controls. Low, medium, high (default), and max. Same model, different price-performance points. Route by complexity, not by model.
- 1M context window actually works. 76% accuracy on needle-in-haystack at 1M tokens, compared to 18.5% for Sonnet 4.5. Context rot is effectively dead.
- Context compaction enables infinite agent sessions. Server-side summarization means your long-running agents stop crashing into context limits.
- Breaking changes will bite you. Assistant message prefilling returns a 400 error.
budget_tokensis deprecated. Your migration checklist is in the final sections. - Honest caveat: Opus 4.6 overthinks simple tasks, GPT-5.2 still edges it on graduate-level reasoning, and Gemini 3 Pro has double the context window at 2M tokens. Know when to use something else.
The Paradigm Shift: Adaptive Thinking
Every model release comes with bigger numbers. Opus 4.6 has those too, and we'll get to them. But the change that will actually reshape how you architect Claude-powered applications isn't a benchmark score. It's a fundamental shift in how the model handles reasoning.
The old world was binary. Since extended thinking launched, you had two options: thinking on, or thinking off. When you turned it on, you had to set budget_tokens - a hard ceiling on how many tokens the model could spend reasoning before answering. Set it too low, and the model truncated its reasoning on hard problems. Set it too high, and you burned tokens on questions that didn't need deep thought. You were essentially guessing how hard each problem was before the model saw it.
That's gone.

Adaptive thinking lets the model evaluate complexity first, then decide how much reasoning the problem deserves. A simple classification? It skips thinking entirely and responds fast. A multi-step debugging task across a large codebase? It thinks deeply, interleaving reasoning between tool calls without you configuring anything.
Here's what the migration looks like in practice:
# Before (Opus 4.5) - you guess the thinking budget
response = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # Hope this is enough?
},
messages=[{"role": "user", "content": prompt}]
)
# After (Opus 4.6) - the model decides
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16000,
thinking={
"type": "adaptive" # Claude handles the rest
},
messages=[{"role": "user", "content": prompt}]
)Clean. But the real power is in the effort parameter, which gives you a dial instead of a switch.
The Effort Dial
Opus 4.6 introduces four effort levels that control how eagerly the model spends tokens on reasoning. Think of it as setting an organizational culture for your AI: "move fast and ship" versus "think carefully and get it right."

Low effort skips thinking on simple tasks entirely. Your routing agent that classifies incoming requests? It doesn't need deep reasoning. Low effort keeps it fast and cheap.
Medium effort is your balanced workhorse. Standard queries, moderate complexity. The model thinks when it helps, skips when it doesn't.
High effort is the default, and for good reason. Claude almost always engages thinking here. This is where you want most production workloads that require reliability.
Max effort is new and exclusive to Opus 4.6. No constraints on reasoning depth. This is your "spare no expense" setting for the hardest problems: complex debugging across massive codebases, novel research questions, multi-step financial analyses where accuracy is everything. It will be slower. It will cost more. But it reaches reasoning depths that no other setting can.
# Route effort by task complexity - same model, different price-performance
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={
"effort": "low" # or "medium", "high", "max"
},
messages=[{"role": "user", "content": prompt}]
)Here's the architectural insight most coverage misses: effort levels let you replace multi-model routing with single-model routing. Instead of maintaining separate pipelines for Haiku (simple tasks), Sonnet (medium tasks), and Opus (hard tasks), you can route everything through Opus 4.6 at different effort levels. Your routing logic gets simpler. Your prompt engineering stays consistent. Your evaluation surface shrinks.
Is that always the right call? No. Haiku and Sonnet are still cheaper per token, and for truly simple tasks, you're paying Opus pricing for Opus-class tokens even at low effort. But for teams that have been drowning in model-routing complexity, effort levels offer a meaningful simplification.
One more thing that matters for production: adaptive thinking is promptable. If the model is thinking more or less than you want, you can guide it through your system prompt. Something like "Extended thinking adds latency and should only be used when it will meaningfully improve your response" will nudge the model toward less thinking. This gives you a soft control layer on top of the hard effort parameter.
And interleaved thinking — where the model reasons between tool calls in agentic workflows — is now automatic. No beta header required. No special configuration. If you're using adaptive thinking, interleaved thinking just works. For anyone who has wrestled with the interleaved-thinking-2025-05-14 beta flag, that's one less thing to maintain.
The Numbers That Matter
Every model launch comes with a wall of benchmarks. Most of them won't change your architecture decisions. Here are the ones that will.
Agentic coding: Opus 4.6 takes the lead, barely. Terminal-Bench 2.0 measures real agentic coding work — planning, executing shell commands, debugging across files. Opus 4.6 scores 65.4%, up from Opus 4.5's 59.8%. That's a meaningful jump within the Claude family. But GPT-5.2 with Codex CLI sits at 64.7%, just 0.7 points behind. If you're choosing between Claude and OpenAI purely on coding benchmarks, the gap is too small to be decisive. Choose based on tooling, pricing, and workflow fit.
Novel problem-solving: the real surprise. ARC AGI 2 tests reasoning on problems the model has never seen before — no pattern matching against training data, no memorized solutions. Opus 4.6 scores 68.8%, nearly doubling Opus 4.5's 37.6% and pulling well ahead of GPT-5.2 Pro's 54.2%. This is the benchmark that best signals whether the model can handle genuinely new challenges in your codebase or domain. The jump here is not incremental. It's generational.
Knowledge work: the enterprise signal. GDPval-AA evaluates economically valuable work across finance, legal, and professional domains — think presentations, spreadsheets, financial analyses, legal documents. Opus 4.6 hits 1,606 Elo, beating GPT-5.2 by 144 points and Opus 4.5 by 190. In head-to-head comparisons, that translates to Opus 4.6 producing higher-quality outputs roughly 70% of the time. If your team uses Claude for anything beyond code — research, analysis, document generation — this number matters.
Long-context retrieval: the context rot killer. MRCR v2 buries 8 facts inside 1M tokens of text and asks the model to find them. Opus 4.6 retrieves 76% correctly. Sonnet 4.5 manages 18.5%. Gemini 3 Pro — which has a 2M context window — scores 26.3%. The window is only useful if the model can actually attend to what's inside it. Opus 4.6 can.
Where it regressed or stalled. SWE-bench Verified actually ticked down from Opus 4.5's 80.9% to 80.8%. Tiny, likely within noise, but worth noting: Anthropic optimized elsewhere. GPT-5.2 still leads on GPQA Diamond for graduate-level scientific reasoning. Gemini 3 Pro wins on MMMU Pro for visual reasoning and offers a 2M token context window — double what Opus 4.6 provides. No model wins everywhere. The question is which wins matter for your workload.
Software diagnostics: the sleeper hit. OpenRCA measures a model's ability to diagnose real software failures. Opus 4.6 scores 34.9%, up from Opus 4.5's 26.9% and Sonnet 4.5's 12.9%. If you're building AI-assisted incident response or debugging pipelines, this 30% improvement over the previous generation is more relevant than any coding benchmark.
1M Context and Compaction: The Long-Running Agent Story
Large context windows have been a marketing fixture for over a year. The problem was never the window size — it was what happened inside it. Models would accept 200K tokens but quietly lose track of information buried past the 50K mark. Engineers called it "context rot," and it made large context windows a liability as much as a feature. You'd stuff documents in, get confident-sounding answers back, and miss that the model had silently dropped a critical constraint from page 47.
Opus 4.6 changes this in a way that actually shows up in benchmarks. On MRCR v2, which hides 8 specific facts across 1M tokens of text and asks the model to retrieve them, Opus 4.6 scores 76%. Sonnet 4.5 scores 18.5%. Gemini 3 Pro — which has a 2M context window — scores 26.3%. The window is only useful if the model can actually attend to what's inside it. Opus 4.6 can.
The practical implications matter more than the benchmark. If you're working with large codebases, multi-document research, or regulatory filings that span hundreds of pages, you no longer need to aggressively chunk and retrieve. You can feed the full source material and trust that the model tracks details across the entire span. That said, 1M context is in beta, and there's a pricing premium: above 200K tokens, input costs double to $10/MTok and output rises to $37.50/MTok.
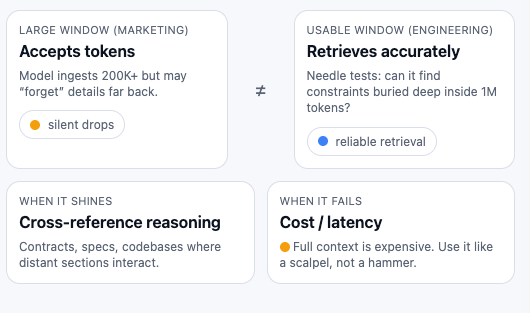
The cost question: 1M context vs RAG. If you're already running a RAG pipeline, should you rip it out and dump everything into context? Probably not. RAG still wins on cost for large, relatively static corpora — you pay embedding costs once and retrieval costs per query. Full context wins when you need the model to reason across the entire document set, not just retrieve from it. A 500-page legal contract where clauses reference each other across sections? Full context. A knowledge base with 10,000 support articles where any single query touches 3–5 of them? RAG is still cheaper and more practical.
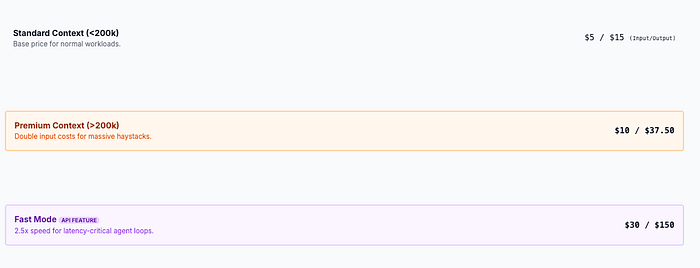
The back-of-envelope math: a 1M token prompt at premium pricing costs roughly $10 per request for input alone. If your agent makes 50 calls per day against that context, you're looking at $500/day just on input tokens. Compare that to a RAG setup where you retrieve 5K-10K tokens per query at standard pricing — roughly $0.05-$0.10 per call, or $2.50-$5.00/day for the same 50 queries. The gap is 100x. Full context is a precision tool for high-value tasks, not a replacement for retrieval infrastructure.
Context Compaction: The Infinite Agent
The more transformative feature might be compaction, which solves a different problem entirely. Long-running agents — the ones that debug across a codebase for an hour, or manage a multi-step research workflow — inevitably hit the context ceiling. Until now, you had to build custom truncation logic, decide what to keep and what to drop, and hope you didn't lose something important.
Compaction handles this server-side. When the conversation approaches a configurable threshold, the API automatically summarizes older parts of the conversation and replaces them with a compressed version. Your agent keeps running. No crash. No custom code. No lost context (well, summarized context — which is a trade-off you should understand).
# Enable compaction for long-running agents
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16000,
thinking={"type": "adaptive"},
context={
"compaction": {
"enabled": True,
"trigger_tokens": 150000
}
},
messages=conversation_history
)The trade-off is real: summarized context loses granularity. If your agent needs to reference a specific variable name from 200 messages ago, compaction might have abstracted that away. For most agentic workflows — where recent context matters most and older context provides background — this trade-off is excellent. For workflows that require precise recall of distant details, you'll want to supplement with external memory.
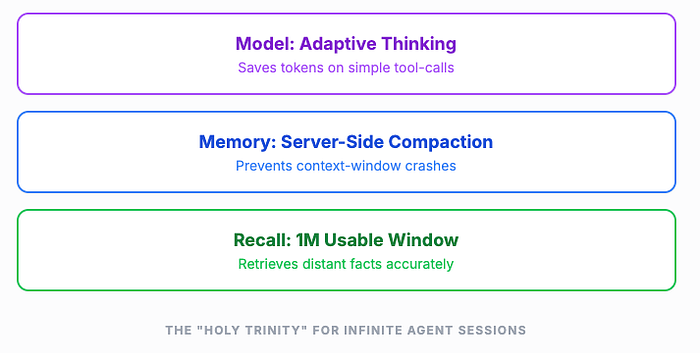
Combined with the 128K max output tokens (doubled from 64K), Opus 4.6 is the first model that can realistically sustain multi-hour agentic sessions without architectural gymnastics. Adaptive thinking keeps costs reasonable by not over-reasoning on simple tool calls within those sessions. Compaction keeps the conversation alive. The 1M window gives you room to breathe.

What Opus 4.6 Means for Agentic Systems
It's tempting to conflate the model's capabilities with the products built on top of it. Let's separate the two, because the distinction matters for how you architect.
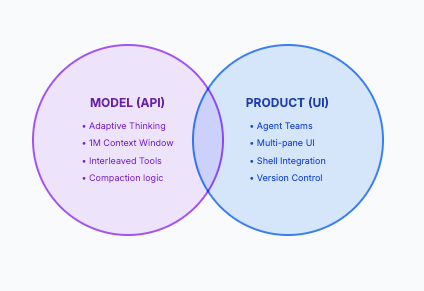
Model-Level Improvements (Available Everywhere)
Regardless of whether you use Claude Code, Cursor, Windsurf, your own API integration, or any other tool, Opus 4.6 the model brings several agentic improvements that show up anywhere you deploy it:
Better planning and decomposition. Opus 4.6 breaks complex tasks into subtasks more reliably than its predecessor. It focuses on the hardest parts first, moves quickly through straightforward pieces, and handles ambiguous requirements with better judgment. Anthropic's internal testing shows the model "thinks more deeply and more carefully revisits its reasoning before settling on an answer." In practice, this means fewer wasted cycles on misunderstood instructions.
Sustained focus over longer sessions. On Vending-Bench 2, which measures long-term coherence across extended interactions, Opus 4.6 earns $3,050 more than Opus 4.5. The model maintains productive output over longer sessions without the quality degradation that plagued earlier versions. Combined with compaction, you can build agents that stay on-task for hours.
Self-correction during code review. One of the most practical improvements: the model catches its own mistakes more often. Earlier Claude models would generate code, review it, and miss obvious issues. Opus 4.6 is notably better at identifying bugs, race conditions, and edge cases in code it just wrote. This reduces the human review burden in AI-assisted development workflows.
Adaptive effort fits agent loops naturally. In a typical agent loop, most tool calls are simple — reading a file, running a command, making an API request. Occasionally, the agent hits a genuinely hard reasoning step. Adaptive thinking means Opus 4.6 doesn't burn max reasoning tokens on every tool call. It saves deep thinking for the moments that need it. This makes long agent loops significantly cheaper without sacrificing quality on hard steps.
Product-Level: Agent Teams in Claude Code
Anthropic's own product implementation of multi-agent work is "agent teams" in Claude Code, currently in research preview. It's worth understanding, but it's important to recognize this is a product feature, not a model capability. Cursor, Windsurf, GitHub Copilot Agent HQ, and Codex CLI all have their own multi-agent patterns.
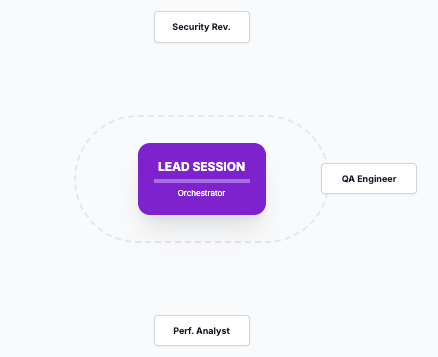
In Claude Code, agent teams work through natural language orchestration. You describe the team structure, and the tool handles spawning and coordination:
> Create an agent team to review this codebase.
Spawn 3 teammates:
1. "security-reviewer" - focus on auth flows in src/auth/
2. "perf-reviewer" - analyze hot paths and database queries
3. "test-reviewer" - assess coverage gaps in tests/
Have them share findings and challenge each other.The lead session coordinates, spawns independent teammate sessions (each with its own context window), and manages a shared task list. Teammates communicate with each other directly — unlike subagents, which only report back to a caller. You can interact with any teammate via Shift+Up/Down or tmux split panes.
The practical constraints are worth knowing: teammates don't inherit the lead's conversation history, file conflicts between teammates are the primary failure mode, and token costs spike roughly 5x compared to a single session. The sweet spot today is read-heavy parallel work — code reviews, research, analysis — not write-heavy parallel implementation where multiple agents edit the same files.
Fast Mode for Agent Loops
One more API-level feature worth highlighting: fast mode delivers up to 2.5x faster output token generation at premium pricing ($30/$150 per MTok). Same model, same intelligence, just faster inference. For agent loops where latency compounds across hundreds of sequential tool calls, this can be the difference between a 10-minute task and a 25-minute task. Whether the 6x output token premium justifies that depends on your throughput requirements.
The Migration Checklist: Breaking Changes
If you're currently running Opus 4.5 in production, here's what will break when you switch to claude-opus-4-6:

Prefilling is dead. Assistant message prefilling — where you start Claude's response with specific text — returns a 400 error on Opus 4.6. No deprecation warning, no graceful fallback. If your prompts rely on prefilling to steer output format, you need to migrate to structured outputs or system prompt instructions before switching models.
# Before (Opus 4.5) - prefilling worked
messages=[
{"role": "user", "content": "Classify this ticket"},
{"role": "assistant", "content": '{"category": '} # Prefill
]
# After (Opus 4.6) - use structured outputs instead
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1000,
output_config={
"format": {
"type": "json_schema",
"schema": {
"type": "object",
"properties": {
"category": {"type": "string"}
}
}
}
},
messages=[{"role": "user", "content": "Classify this ticket"}]
)Thinking configuration is deprecated. thinking: {type: "enabled", budget_tokens: N} still works but is deprecated and will be removed. Migrate to thinking: {type: "adaptive"} with the effort parameter.
Output format moved. output_format is now output_config.format. The old parameter still works but is deprecated.
# Before
output_format={"type": "json_schema", "schema": {...}}
# After
output_config={"format": {"type": "json_schema", "schema": {...}}}Beta headers cleaned up. The interleaved-thinking-2025-05-14 beta header is ignored on Opus 4.6. Adaptive thinking enables interleaved thinking automatically. Remove the header to keep your requests clean.
Model ID simplified. The identifier is claude-opus-4-6 - no date suffix. This is a break from the previous naming convention (claude-opus-4-5-20251101).
JSON escaping differences. Opus 4.6 may produce slightly different JSON string escaping in tool call arguments (Unicode escapes, forward slash handling). Standard parsers handle this fine. If you're parsing tool call input as raw strings instead of using json.loads() or JSON.parse(), test your parsing logic.
US-only inference available. If data residency matters, you can now request US-only inference with the inference_geo parameter at 1.1x token pricing.
When NOT to Use Opus 4.6
Building trust means being honest about when a tool isn't the right choice. Here's where Opus 4.6 is overkill or outperformed:
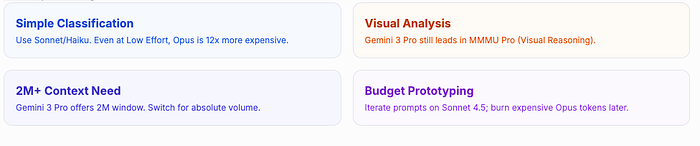
Simple classification and routing tasks. Opus 4.6 will overthink them. Even at low effort, you're paying Opus-tier pricing per token. If your task is "classify this support ticket into 5 categories," Haiku or Sonnet will do it faster, cheaper, and just as accurately. Save Opus for problems that actually benefit from deep reasoning.
High-volume, low-complexity workloads. At $25/MTok output, costs accumulate fast when you're processing thousands of simple requests. A pipeline that handles 100K requests/day at 500 output tokens each would cost roughly $1,250/day on Opus versus around $100/day on Sonnet 4.5. That's a 12x premium for work that doesn't need frontier reasoning.
Visual reasoning tasks. Gemini 3 Pro still leads on MMMU Pro for visual understanding. If your application involves heavy image analysis, document layout understanding, or visual reasoning, benchmark against Gemini before committing to Opus.
When you need 2M+ context. Gemini 3 Pro offers double the context window. If your workload genuinely needs more than 1M tokens of context and you can't use RAG to reduce the window, Gemini is the practical choice.
Cost-sensitive prototyping. When you're iterating on prompts and architecture, burning Opus tokens on every test run is expensive. Prototype on Sonnet 4.5, then validate on Opus once your approach stabilizes. This is especially true during early development when you're making frequent changes.
If your code heavily relies on prefilling. The migration from prefilling to structured outputs is non-trivial for some architectures. If prefilling is deeply embedded in your system, evaluate the migration effort before switching. It might not be worth it for a 0.1% improvement on SWE-bench.
Credits & Further Reading
- Introducing Claude Opus 4.6 — Anthropic's official announcement with full benchmark data and partner testimonials.
- What's New in Claude 4.6 — Official API documentation covering adaptive thinking, compaction, fast mode, and breaking changes.
- Adaptive Thinking Documentation — Deep dive into adaptive thinking configuration and promptability.
- Effort Parameter Documentation — Complete guide to effort levels and their interaction with extended thinking.
- Building a C Compiler with Claude Agent Teams — Case study of 16 agents writing 100K lines of Rust, with practical lessons on multi-agent coordination.
- Claude Opus 4.6 System Card — Detailed safety evaluations, capability assessments, and methodology notes.