


Go and Postgres may be an uncommon stack for data pipelines, but here's why I chose them and how I made them work. Here is the secret ingredient: TimescaleDB
In the previous part, I explained why I chose Go over Python for building an ETL pipeline at a startup where I was the founding engineer. This part continues with the other half of the stack: why PostgreSQL became the central storage layer.
To recap the context, I was the sole engineer at an energy-tech startup that collected data from energy IoT devices to calculate electricity bills. That meant the data had to be exact: decimal precision mattered, and missing or duplicate records were intolerable.
As the one setting the foundation for the entire data infrastructure, I deliberately favoured systems that enforce structure, constraints, and correctness over maximum flexibility. That naturally led me to relational databases as the central storage and source of truth.
Below are the main reasons why PostgreSQL stood out among the other options to me:
1. Billing data needs enforcement, and Postgres provides it
Given the constraints of money-related data, I preferred relational enforcement such as primary key, unique constraints, foreign keys, and precise NUMERIC types for accounting. Moreover, relational databases are built around ACID transactions, which means ingested data must pass all integrity checks before being committed. Writes are applied atomically, meaning either everything is committed or nothing at all, protecting the system from partial or inconsistent writes in case of failures (power outages, for example).
This proved especially useful in our case, since we collected data from many different devices, which were not always reliable. Duplicates, missing fields, and data gaps were common. With ACID guarantees in place, I, along with non-technical stakeholders, could be rest assured that invalid or partial writes would be rejected outright. For data to be billing and accounting-grade, integrity mattered far more than raw ingestion throughput.
In contrast, many data storage systems that optimize throughput don't provide as much guarantee. Under the hood, they store data in columnar files and defer many integrity checks to later. Relational databases, on the other hand, typically rely on B-tree indexes and enforce constraints eagerly, maintaining strict referential integrity at write time.
2. Postgres actually does support time-series data
Now we have Postgres for storage, but how about compute? IoT data is time-series, and time-series data feels awkward in vanilla relational databases. A common Postgres approach is using date_trunc to group timestamps into buckets. For example, to get hourly energy usage for the last day:
SELECT date_trunc('hour', ts) AS hour,
SUM(energy_kwh) AS hourly_kwh
FROM readings
WHERE ts >= now() - INTERVAL '1 day'
GROUP BY hour
ORDER BY hour;If you add an index on ts, Postgres will use it to limit the rows scanned to the last day rather than scanning the whole table. For each row matching the WHERE clause, Postgres computes the truncated timestamp from the original (for example, '2025-01-01 12:34:56' -> '2025-01-01 12:00:00') and updates a global aggregation state. That means the aggregation work is essentially linear in the number of rows processed, so monthly or yearly aggregation can become time-consuming with more per-row handling and expensive due to global aggregation overhead.
Fortunately, Postgres has an extension for time-series data: TimescaleDB. TimescaleDB gives you hypertables, which behave just like regular Postgres tables, but under the hood, Timescale splits the data into many smaller chunks by time.
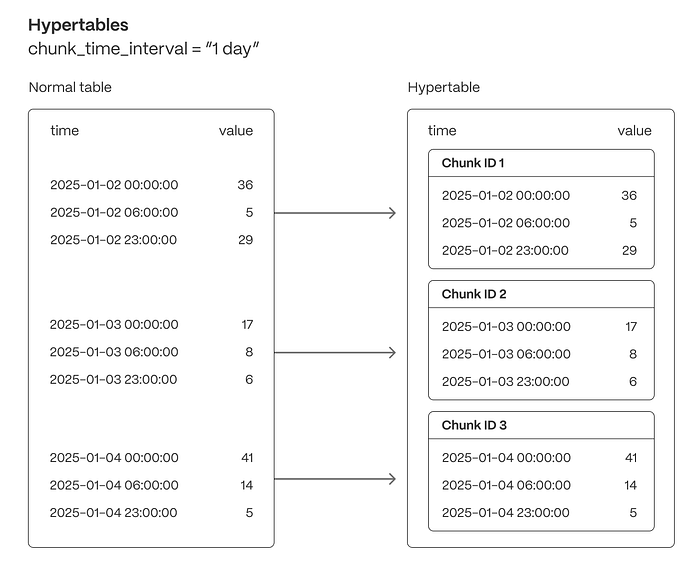
With this chunked design, we can query aggregations much more efficiently in terms of time and cost. Instead of relying on date_trunc, TimescaleDB provides a function called time_bucket. This is how we define a hypertable and aggregate energy usage by each month for the last year
CREATE EXTENSION IF NOT EXISTS timescaledb;
-- create a hypertable with chunks by day
CREATE TABLE readings (
device_id TEXT NOT NULL,
ts TIMESTAMP WITH TIME ZONE NOT NULL,
energy_kwh NUMERIC(18,6),
PRIMARY KEY (device_id)
)
WITH(
timescaledb.hypertable,
timescaledb.chunk_interval='1 day'
);
-- time-bucketed monthly aggregation
SELECT device_id,
time_bucket('1 month', ts) AS month,
SUM(energy_kwh) AS monthly_kwh
FROM readings
WHERE ts >= now() - INTERVAL '1 year'
GROUP BY device_id, month
ORDER BY device_id, month;The SQL does not look much different from the date_trunc version. However, behind the scenes, TimescaleDB first identifies relevant time chunks and ignores all others, so we do not need an index on timestamp here. Then, aggregation work is done locally within each chunk and can even be parallelised across chunks. That means the final results are combined incrementally, with lower coordination overhead and shorter execution time.
TimescaleDB is powerful; however, there is an important caveat if you opt for managed databases instead of self-hosted Postgres: the TimescaleDB extension is not universally supported across providers, such as Google Cloud. Among all options, I found that DigitalOcean's managed Postgres offers support for TimescaleDB, but only with the Apache-licensed version and a limited set of features.
3. Postgres can still handle the startup scale pretty well
I think this is often overlooked due to the hype around modern storage systems and warehouses, as they can comfortably serve huge workloads up to terabytes, or even petabytes of data, at once. However, in fact, the startup was not there yet. Our data streams were driven by installed devices in commercial and residential buildings, meaning data growth depends on physical developments, not on viral traffic or sudden spikes due to social media.
I'm not sure of how much Postgres can handle, but its long history and widespread use across the industry gave me more confidence. At the time of writing, we had seen a x15 growth in data streams and volume, and Postgres combined with TimescaleDB still stored and computed our analytics reliably.
4. Postgres' concepts are easy to explain
As the only engineer at the startup, I had to communicate many infrastructure decisions to non-technical stakeholders. In our case, the data infrastructure was tightly coupled to the core business model. Thus, the first to notice that devices were behaving incorrectly were often business people, such as the CEO or CFO, not engineers. As such, my job as an engineer was also to build the data pipeline and storage that are visible and inspectable to non-engineers.
Postgres' concepts, such as rows and tables, are intuitive and easy to understand. Even if they asked me why we needed IDs and why we split into small tables instead of merging, the concepts of primary and foreign keys were relatively straightforward to explain. To make the data accessible, I connected PostgreSQL directly to an open-source analytics tool called Metabase. This allowed stakeholders to view the data in a familiar, spreadsheet-like interface, explore it visually, and even run simple computations on their own.
PostgreSQL with TimescaleDB turned out to be an excellent yet simple choice for my use case. It allowed me to move fast without sacrificing correctness, while building a stable system that non-engineers could understand and use.
"Old-school" tools don't necessarily mean outdated or irrelevant. In fact, in the modern data landscape, I believe it's even more important to evaluate real needs, current scale, trade-offs, and risks before opting for a complex system design to get things "right" early on.