


Introduction
At Agoda, financial metrics, including sales, cost, revenue, and margin, are among our most critical data points, enabling analysts to deliver essential insights across the business. Every day, we generate and process millions of these financial data points. These metrics are fundamental to our daily operations, reconciliation, general ledger activities, financial planning, and strategic evaluation. They not only enable us to predict and assess financial outcomes but also provide a comprehensive view of the company's overall financial health, ultimately feeding into our financial accounts.
Given the sheer volume of data, the diverse requirements of different teams, and the varied needs of end users, our Data Engineering, Business Intelligence, and Data Analysis teams each developed their own data pipelines to meet their specific demands. The appeal of separate data pipeline architectures lies in their simplicity, clear ownership boundaries, and ease of development, an approach we initially adopted within FinTech as well. However, we soon discovered that maintaining separate financial data pipelines, each with its own logic and definitions, could introduce discrepancies and inconsistencies, which could potentially impact Agoda's financial statements.
Beyond data consistency, ensuring data quality presented an equally significant challenge. Because financial metrics are among our most crucial data assets, they require the highest standards of accuracy and reliability. To support this, we needed to uphold stringent data quality controls and maximize system uptime, ensuring our data remains trustworthy and accessible at all times.
In this blog post, we share our journey to consolidate Agoda's financial data pipelines, highlighting how we achieved greater data quality and system reliability.
The Challenges of Multiple Financial Data Pipelines
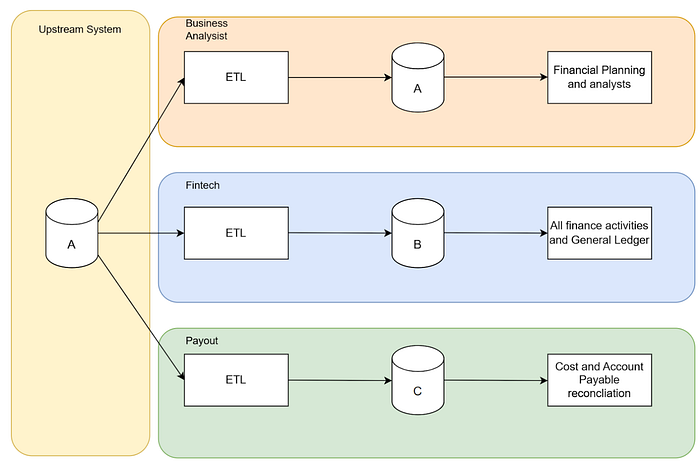
The high-level architecture of multiple data pipelines, each owned by different teams, introduced several problems:
- Duplicate Sources: Many pipelines pulled data from the same upstream systems. This led to redundant processing, synchronization issues, data mismatches, and increased maintenance overhead.
- Inconsistent Definitions and Transformations: Each team applied its own logic and assumptions to the same data sources. As a result, financial metrics may differ depending on which pipeline produced them, creating confusion and undermining data reliability.
- Lack of Centralized Monitoring and Quality Control: The absence of a unified system for tracking pipeline health and enforcing data standards resulted in inconsistent quality checks across teams. This resulted in duplicated effort, inconsistent practices, and delays in identifying and resolving issues.
What Happens When Pipeline Inconsistencies Go Unchecked
During a recent review, we observed that differences in data handling and transformation across these pipelines can lead to inconsistencies in reporting, as well as operational delays, including investigations, data fixes, and the regeneration of reports. This experience reinforced the value of unifying our data processing into a single, streamlined pipeline, helping us ensure greater accuracy, reliability, and trust in our financial reporting going forward.
The Solution: Centralized Financial Data Pipeline (FINUDP)
To overcome these challenges, we developed a centralized financial data pipeline, known as Financial Unified Data Pipeline (FINUDP), that delivers both high data availability and robust data quality. Built on Apache Spark, FINUDP processes all financial data from millions of bookings each day and makes this data reliably available to downstream teams for reconciliation, ledger, and financial activities.
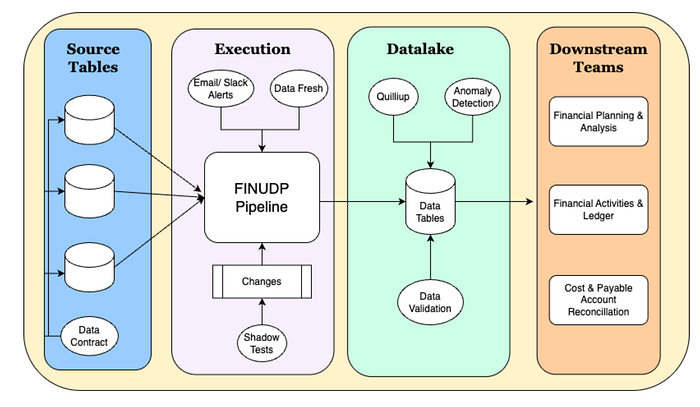
Non-Functional Requirements
For our centralized pipeline, three non-functional requirements stood out: freshness, reliability, and maintainability.
- Data Freshness: Our pipeline is designed to update data every hour, aligned with strict SLAs for our downstream consumers. To ensure we never miss these targets, we use an internally developed tool called "GoFresh", which monitors table update timestamps. If an update is delayed, the system flags it, prompting immediate action to prevent any SLA breaches.
- Reliability: Data quality is paramount. As soon as new data lands in a table, a suite of automated data quality checks runs, validating each column against predefined rules. Any violation triggers an alert, stopping the pipeline and allowing us to address data issues before they cascade downstream.
- Maintainability: High code quality is non-negotiable. Each change begins with a strong, peer-reviewed design. Code reviews are mandatory, and all changes undergo shadow testing, which runs on real data in a non-production environment for comparison. Strict unit testing and coverage requirements (with 90% targets) ensure that every release is robust before being deployed to production.
- By focusing on non-functional pillars, we maintain clean, dependable, and scalable pipelines, delivering trust alongside data.
Key challenges encountered while building FINUDP
Throughout the journey of building FINUDP and migrating multiple data pipelines into one, we encountered several key challenges.
- Stakeholder management: Centralizing multiple data pipelines into a single platform meant that each output still served its own set of downstream consumers. This created a broad and diverse stakeholder landscape across product, finance, and engineering teams. One of the key challenges was aligning everyone on shared goals, consistent data definitions, and clear expectations of the new FINUDP platform. We spent significant time driving conversations, clarifying use cases, and ensuring that all teams understood how FINUDP would support their specific reporting and analytical needs.
- Performance issue: Bringing together several large pipelines and consolidating high-volume datasets into FINUDP initially incurred a performance cost; our end-to-end runtime was approximately five hours. This was far from ideal for daily financial reporting. Through a series of optimization cycles that covered query tuning, partitioning strategy, pipeline orchestration, and infrastructure adjustments, we were able to reduce the runtime from five hours to approximately 30 minutes, making the pipeline suitable for near–real–time and daily production use.
- Data inconsistency: Each legacy pipeline has evolved with its own set of assumptions, business rules, and data definitions. When we merged them into FINUDP, those differences surfaced as data inconsistencies and mismatches between them. To address this, we went back to first principles: we documented the intended meaning of each key metric and field, conducted detailed gap analyses, and facilitated workshops with stakeholders to agree on a single definition for each dataset. This alignment not only resolved the immediate discrepancies but also laid the foundation for more reliable and auditable financial data going forward.
How can we ensure data quality and uptime with a centralized data pipeline?
Identifying the solution is just the beginning; successful implementation and ongoing accuracy are equally critical. As a team, it is our responsibility to ensure that the data pipeline operates reliably and produces accurate data on an hourly basis. Last year, our data pipeline achieved 95.6% uptime, but our goal is to maintain 99.5% data availability at all times. To reach this higher level of reliability, we must carefully consider various aspects of the data pipeline.
Monitoring Execution Failures:
Since many downstream teams rely heavily on the data we provide, it's essential to ensure that every execution of the pipeline, including all its components is successful. If any part fails, the development team must be promptly alerted. To achieve this, we have implemented a three-level alerting system:
- Email Alerts: Any pipeline failure triggers an email alert to the developers via the coordinator, enabling quick awareness and response.
- Slack Alerts: A dedicated backend service monitors all running jobs and sends notifications about job successes or failures directly to the development team's Slack channels. These alerts are categorized by hourly and daily frequency.
- Data Freshness Monitoring: The "GoFresh" tool continuously checks the freshness of specific columns in target tables. If data is not updated within a predetermined time frame, Go Fresh notifies the development team through the NOC (Network Operations Center), a 24/7 support team that monitors all critical Agoda alerts, notifies the correct team, and coordinates a "war room."
Shadow Tests
In addition to having every change reviewed in a merge request (MR), we also run shadow tests on all changes submitted in MRs. During shadow testing, we execute predefined Spark SQL queries on both the MR containing the proposed change and the previous version. The results are then compared, and a summary is shared directly within the MR. This process provides reviewers with clear visibility into the impact of the proposed changes on the data, enabling both the developer and reviewer to access the data changes in their MR.
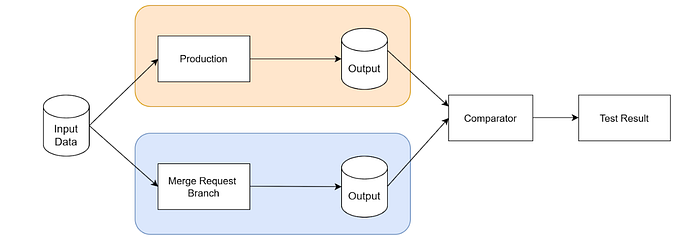
Staging Environment
A staging environment serves as a safety net between development and production. It closely mirrors the production setup, allowing us to test new features, pipeline logic, schema changes, and data transformations in a controlled setting before they are released to all users. By running the full pipeline with realistic data in staging, we can identify and resolve issues such as data quality problems, integration errors, or performance bottlenecks without risking the integrity of production data. This approach not only reduces the likelihood of unexpected failures but also builds confidence that every change has been thoroughly validated before going live.
Proactive Monitoring for Data Reliability
To further enhance data reliability, we introduced daily snapshots, partition count checks, and automated alerts to detect spikes in corrupted data. These mechanisms ensure that all data partitions are present and that row counts align with expectations.
Data Quality Checks
Ensuring both data accuracy and consistency is paramount when handling financial data. Validating generated data and diagnosing issues are critical steps in our workflow. To uphold data quality, we rely on Quilliup, anomaly detection, and robust data validation mechanisms.
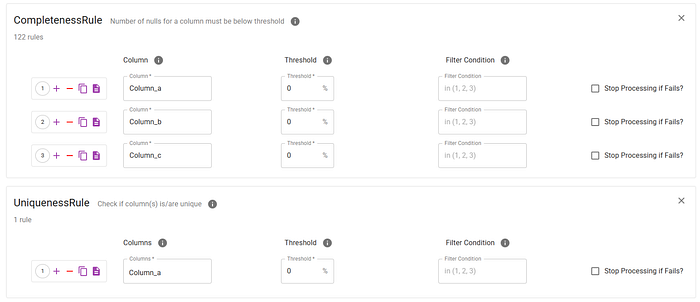
i) Data Validations We run a suite of validations on our main data tables, including checks for null values, value ranges, uniqueness, enum values, and binary value correctness. These validations help maintain data integrity and prevent errors from propagating downstream. If any business-critical rules fail, we not only capture and alert on the issue, but also pause the pipeline. This is a deliberate design decision to ensure that we investigate and fix the problem, rather than risk processing partial or incorrect data.
ii) Data Integrity Using a third-party data quality tool called "Quilliup", we execute predefined test cases that utilize SQL queries to compare data in target tables with their respective source tables. Quilliup measures the variation between source and target data and alerts the team if the difference exceeds a set threshold. This ensures consistency between the original data and its downstream representation.
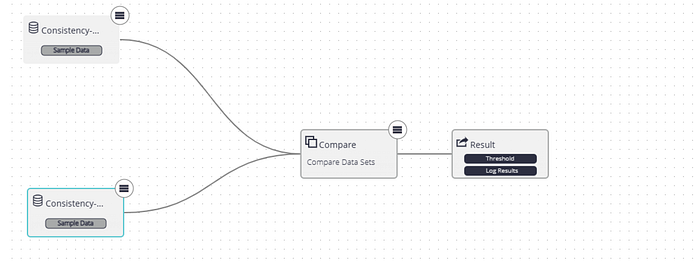
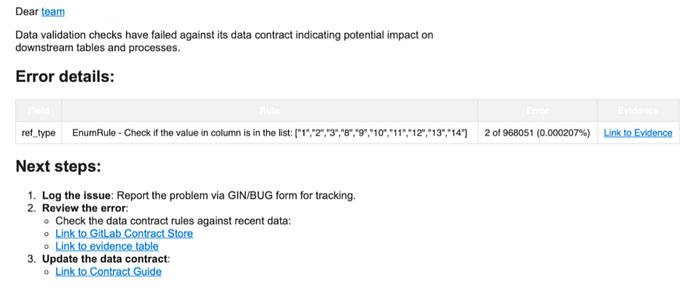
iii) Data Contracts We establish formal data contracts with upstream teams that provide our source data. These contracts define required data rules. If the incoming source data violates the contract, the source team is immediately alerted and asked to resolve the issue. There are two types of data contracts: (1) detection on real production data, and (2) preventative checks integrated into the CI pipelines of upstream data producers. This approach helps maintain data accuracy at the ingestion stage and prevents the introduction of unexpected data not defined in the contract.
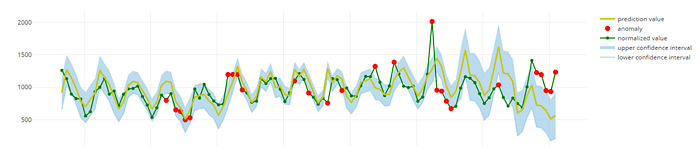
iv) Anomaly Detection We also utilize machine learning models to monitor data patterns and identify any unusual fluctuations or spikes in the data. When anomalies are detected, the team investigates the root cause and provides feedback to improve model accuracy, distinguishing between valid and false alerts.
Architectural Trade-offs in Centralizing Financial Data Pipelines
Centralizing our data pipelines came with clear benefits, but also required navigating key trade-offs:
Velocity
- Data Dependency: A key challenge has been the reduction in velocity due to data dependency. In the previous decentralized approach, independent small datasets could move through their separate pipelines without waiting on each other. With the centralized setup, we establish data dependencies to ensure that all upstream data sets are ready before proceeding with the entire data pipeline, which helps prevent partial data writes.
- Data Quality: Since this pipeline included multiple data sources and components, the changes in any of the components require testing and a data quality check of the whole pipeline, which causes a slowness in velocity, but it's a tradeoff with all the numerous benefits we get from having a unified pipeline.
- Data Governance: Migrating to a single pipeline required that every transformation be meticulously documented and reviewed. Because financial data is at stake, we needed full alignment and approval from all stakeholders before changing upstream processes. The need for thorough vetting and consensus slowed implementation, but ultimately built a foundation for trust and integrity in our new, unified system. In short, centralization increases reliability and transparency, but it demands tighter coordination and careful change management at every step.
Conclusion
Consolidating our financial data pipelines at Agoda has made a real difference in how we handle and trust our financial metrics. Through FINUDP, we have established a single source of truth for all financial metrics in Agoda. By introducing centralized monitoring, automated testing, and robust data quality checks, we've significantly improved both the reliability and availability of our data. This setup means downstream teams always have access to accurate and consistent information. Maintaining high data standards is always a work in progress, but with these systems in place, we're better equipped to catch issues early, collaborate across teams, and keep moving forward with confidence.
