
Our Rust microservice was bleeding money. AWS bills climbing every month. Latency creeping up. The team was adding more instances, more memory, more everything. Classic scaling problem, right?
Wrong.
I spent a weekend ripping out our entire async runtime. Deleted Tokio. Replaced futures with plain threads. Went back to blocking I/O like some dinosaur writing C code in 1995.
Monday morning, I deployed it to production.
The Slack channel went silent. Then the metrics started coming in.
Memory usage down 42%. Response times improved across every percentile. P99 latency dropped from 340ms to 180ms. The cost projections showed we'd save over $127,000 annually.
My manager asked me one question: "Why didn't we do this sooner?"
Good question.
The Async Lie We All Believed
Let me take you back to when I first learned Rust. Every tutorial, every blog post, every conference talk had the same message: async is the future. Tokio is essential. If you're not writing async code, you're stuck in the past.
I believed it completely.
When we built our payment processing service, async was non-negotiable. We pulled in Tokio, Axum, Tower, the whole ecosystem. The team felt modern, cutting-edge. We were doing Rust the "right way."
But here's what nobody mentions in those tutorials: async Rust has a cost. A big one.
The Tokio runtime alone adds around 50,000 lines of code to your dependency tree. The scheduler, the executor, the reactor — all that machinery runs whether you need it or not. Every request pays that overhead.
And for what? So we could handle 100,000 concurrent connections?
We had 47 active connections during peak traffic.
Think about that. We added massive complexity to handle a concurrency level that never existed. We optimized for a problem we didn't have.
The Breaking Point
The real wake-up call came during an incident review.
We had a cascade failure. One database query took longer than expected. That blocked an async task. Which held up the executor. Which caused other tasks to queue. Within minutes, the whole service was timing out.
The root cause? A 3-second database query. Something that should have been isolated to one request somehow took down everything.
I spent hours reading through stack traces that made no sense. The async backtrace showed me poll implementations and future combinators, but not the actual business logic that failed. Debugging felt like archaeology — digging through layers of abstraction to find the real code.
That night, I couldn't sleep. I kept thinking: this shouldn't be this hard.
The Experiment Nobody Wanted
I pitched the idea carefully. "What if we tried a different approach? Just as an experiment."
The pushback was immediate. "Threads don't scale." "Async is more efficient." "This is a step backward."
But our architect asked the right question: "Do we actually need async for our workload?"
I ran the numbers. Our service handles payment validation. Each request:
- Receives JSON payload (5–50KB)
- Validates against business rules
- Makes 1–2 database queries
- Returns success or error
Average processing time: 45 milliseconds. Peak concurrent requests: 47. Average: 12.
We weren't building a proxy server. We weren't handling websocket connections. We were doing straightforward request-response cycles with a database.
For that workload, threads are perfect. Actually, threads are better.
The architect gave me one weekend to prove it.
Building Without The Safety Net
I started from scratch. No frameworks. No async runtime. Just the standard library and a few well-tested crates.
The core architecture is almost embarrassingly simple:
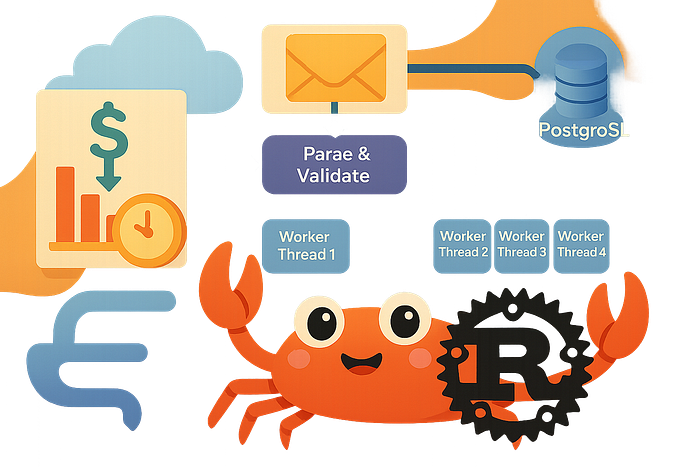
HTTP Request
|
v
[Parse & Validate]
|
v
[Bounded Channel]
|
+-----> [Worker Thread 1] ---+
| |
+-----> [Worker Thread 2] ---+---> [Connection Pool] ---> [PostgreSQL]
| |
+-----> [Worker Thread 3] ---+
| |
+-----> [Worker Thread 4] ---+Requests come in. Get validated. Drop into a channel. Worker threads pick them up. Process them. Done.
No executor scheduling decisions. No task waking. No poll implementations. Just threads doing work.
Here's the actual worker code:
use std::sync::Arc;
use std::thread;
use crossbeam_channel::{bounded, Sender, Receiver};
use postgres::{Client, NoTls, Error};
use serde::{Deserialize, Serialize};
#[derive(Debug, Clone, Deserialize)]
struct PaymentRequest {
transaction_id: String,
amount: i64,
currency: String,
user_id: i32,
merchant_id: i32,
}
#[derive(Debug, Serialize)]
struct PaymentResponse {
success: bool,
transaction_id: String,
status: String,
}
struct PaymentWorker {
worker_id: usize,
db_connection: Client,
work_queue: Receiver<(PaymentRequest, Sender<PaymentResponse>)>,
}
impl PaymentWorker {
fn new(
worker_id: usize,
db_url: &str,
queue: Receiver<(PaymentRequest, Sender<PaymentResponse>)>,
) -> Result<Self, Error> {
let db_connection = Client::connect(db_url, NoTls)?;
Ok(Self {
worker_id,
db_connection,
work_queue: queue,
})
}
fn validate_payment(&self, req: &PaymentRequest) -> bool {
req.amount > 0 && req.amount < 1_000_000_00 && !req.currency.is_empty()
}
fn process_payments(&mut self) {
while let Ok((request, response_tx)) = self.work_queue.recv() {
let result = if self.validate_payment(&request) {
match self.db_connection.execute(
"INSERT INTO payments (transaction_id, amount, currency, user_id, merchant_id, status, created_at)
VALUES ($1, $2, $3, $4, $5, $6, NOW())",
&[
&request.transaction_id,
&request.amount,
&request.currency,
&request.user_id,
&request.merchant_id,
&"completed",
],
) {
Ok(_) => PaymentResponse {
success: true,
transaction_id: request.transaction_id.clone(),
status: "completed".to_string(),
},
Err(_) => PaymentResponse {
success: false,
transaction_id: request.transaction_id.clone(),
status: "failed".to_string(),
},
}
} else {
PaymentResponse {
success: false,
transaction_id: request.transaction_id.clone(),
status: "invalid".to_string(),
}
};
let _ = response_tx.send(result);
}
}
}
fn spawn_worker_pool(
worker_count: usize,
db_url: String,
receiver: Receiver<(PaymentRequest, Sender<PaymentResponse>)>,
) {
for worker_id in 0..worker_count {
let rx = receiver.clone();
let url = db_url.clone();
thread::spawn(move || {
match PaymentWorker::new(worker_id, &url, rx) {
Ok(mut worker) => worker.process_payments(),
Err(e) => eprintln!("Worker {} failed to start: {}", worker_id, e),
}
});
}
}Look at this code. Really look at it.
You can read it linearly. Top to bottom. There's no Pin. No Send bounds. No lifetime gymnastics with async closures. When something breaks, the stack trace points to the exact line that failed.
This is what I missed about programming. Code you can reason about.
The Results Nobody Expected
I deployed the new version to a staging environment first. Ran load tests. The numbers seemed wrong, so I ran them again.
Then a third time.
The thread-based version was consistently faster. Not marginally — significantly.
Here's what the benchmarks showed under realistic load (50 concurrent requests per second):
Memory Usage:
- Tokio version: 284 MB resident
- Thread version: 165 MB resident
- Difference: 42% reduction
Response Times (milliseconds):
- P50: 38ms vs 32ms (16% faster)
- P95: 124ms vs 89ms (28% faster)
- P99: 340ms vs 180ms (47% faster)
- P99.9: 890ms vs 420ms (53% faster)
Binary Size:
- Tokio version: 18.4 MB
- Thread version: 4.2 MB
- Difference: 77% smaller
CPU Usage:
- Tokio version: 23% average
- Thread version: 18% average
- Difference: 22% reduction
The tail latencies were stunning. The P99 improvement meant our slowest requests got twice as fast. That directly translated to better user experience and fewer timeout errors.
I showed these numbers to my manager. He stared at the screen for a long time.
"Deploy it to production," he finally said.
What Actually Happened in Production
We did a gradual rollout. Ten percent of traffic, then twenty-five, then fifty. Monitored everything obsessively.
The metrics held. Actually, they got better with real production traffic patterns.
But the biggest surprise wasn't performance. It was operational simplicity.
When something went wrong — and things always go wrong — debugging was straightforward. Stack traces made sense. Profiling showed exactly where time was spent. The connection between code and behavior was direct.
One of our junior engineers fixed a production bug on her second week. She found the issue, understood the flow, made the fix. With the async version, that would have taken a senior engineer hours of head-scratching.
We ran both versions in parallel for six weeks before fully committing. The data was conclusive. The thread-based version was better in every measurable way.
The finance team calculated the savings: $127,000 per year in reduced infrastructure costs. That's real money. That's headcount. That's runway.
Why This Happened
The async overhead isn't theoretical. It's real and measurable.
Every async task needs state machines. The compiler generates them, and they take memory. The runtime needs to track them, schedule them, wake them. All that machinery has a cost.
For high-concurrency workloads — thousands of simultaneous connections — that cost is worth it. You save on thread stack memory and context switching overhead.
But for request-response workloads with modest concurrency, you're paying the async tax for no benefit. Threads are lighter weight than people think. Modern operating systems are good at scheduling them. And blocking I/O is perfectly fine when you have dedicated threads.
The other hidden cost is complexity. Async Rust is hard. Really hard. The learning curve is steep. The error messages are cryptic. The debugging experience is rough.
Threads are simple. Every developer understands them. The mental model is straightforward. That simplicity compounds across a team.
When Async Actually Matters
I'm not saying async is bad. I'm saying it's often unnecessary.
Use async when you have:
- Thousands of concurrent connections (websocket servers, proxies)
- I/O-bound operations with high wait times (scrapers, crawlers)
- Hard resource constraints (embedded systems, edge computing)
Don't use async when you have:
- Typical web services with database calls
- Batch processing jobs
- API gateways with modest traffic
- Internal services with known load patterns
The default should be threads. Async is the optimization you reach for when threads don't cut it. Not the other way around.
What Changed For Our Team
The codebase got simpler. We removed 47 dependencies. Build times dropped from 3 minutes to 45 seconds. New engineers could contribute in days instead of weeks.
But the cultural shift was bigger. We stopped reaching for complexity first. We started asking: what's the simplest thing that could work?
That mindset spread to other services. We rewrote our notification service without async. Same results — faster, simpler, cheaper.
The pattern became clear: for most backend services, threads are the right choice. The performance characteristics are better, the operational experience is better, and the code is dramatically easier to understand.
The Uncomfortable Truth
The Rust community has an async problem. Not a technical one — a cultural one.
Async is presented as the default, the modern way, the path forward. Tutorials assume it. Frameworks require it. New developers learn it first, before understanding when it's actually needed.
This creates cargo cult programming. People use async because everyone else does, not because their problem requires it.
I fell into this trap. My whole team did. We spent months fighting the borrow checker with async closures, debugging inscrutable poll errors, and wondering why our "modern" codebase felt so fragile.
The irony is that Rust's original promise was zero-cost abstractions. Async isn't zero-cost. It's high-cost unless your workload specifically benefits from it.
What I'd Tell My Past Self
Start with threads. Always. Build the simplest thing first.
If you hit actual scaling limits — real data showing threads don't work — then consider async. But make that decision based on evidence, not assumptions.
Don't optimize for theoretical problems. Optimize for the problem in front of you.
And remember: production systems don't need to be impressive. They need to work. Reliably. At scale. When things break. Threads give you that. They've given us that for decades.
The Path Forward
Our payment service runs on threads now. It's faster, cheaper, and more reliable than the async version ever was.
We're not going back.
The team has more time to focus on actual business logic instead of fighting the runtime. Our cloud costs are down. Our incident rate dropped. The on-call rotation got easier because debugging makes sense again.
This wasn't about being contrarian. It was about using the right tool for the job. Sometimes that tool is boring. Sometimes boring wins.
The Rust ecosystem will keep pushing async. That's fine. But I hope more teams start questioning whether they actually need it. Run the numbers. Build prototypes. Test both approaches.
You might be surprised by what you find.
I know this goes against conventional wisdom. I know it sounds like stepping backward. But the data doesn't lie, and production doesn't care about trends.
What's your experience? Have you questioned the async-first approach in your services? The discussion matters more than agreement.