

RAG is DEAD!
Retrieval-Augmented Generation ruled 2025. But in 2026, million-token context windows and agentic AI are rewriting the playbook — and most engineers are building for yesterday's problem.
⚠️ CRITICAL DISCLAIMERS:
This article presents a controversial perspective based on current industry trends, technical research, and expert analysis as of January 2026. The views expressed here are intentionally provocative to stimulate discussion and critical thinking.
Important clarifications:
- RAG is not literally "dead" — it's evolving rapidly into more sophisticated forms
- The effectiveness of different approaches depends heavily on your specific use case, budget, and technical requirements
- This article synthesizes real research and industry data, but technology changes fast — verify claims against your own testing
- Cost, latency, and accuracy trade-offs vary significantly by implementation
- Always pilot solutions with your actual data before making architectural decisions
This is not financial or technical advice. I'm an AI practitioner sharing observations, not an oracle predicting absolute truth.
Now, let's get controversial.
The Death Certificate
Here's what nobody wants to admit out loud: The RAG pipeline you spent six months building in 2024 is already obsolete.
While you were agonizing over chunk sizes, tweaking embeddings, and debugging retrieval precision, the ground shifted beneath your feet. Gemini 1.5 Pro now processes 2 million tokens. GPT-4 handles 1 million. Claude Opus 4 operates at 200,000 tokens with near-perfect recall.
Do the math: 1 million tokens equals roughly 1,500 pages of text. That's 3–4 entire technical books. Your entire company wiki. Every customer support ticket from the past year.
Why build a complex retrieval pipeline when you can just… paste everything into the prompt?
This is the question keeping RAG engineers up at night. And according to recent industry analysis, it's not just anxiety — it's reality:
"Organizations will still find use cases in 2026 where data retrieval is needed and some enhanced version of RAG will likely still fit the bill… [but] one approach that will likely surpass it in terms of usage for agentic AI is contextual memory, also known as agentic or long-context memory." — VentureBeat, "6 data predictions for 2026"
Translation: Traditional RAG is becoming a niche solution, not the default architecture.
How We Got Here (A Brief Autopsy)
Let me take you back to 2023.
Context windows were tiny — 8,000 tokens for GPT-3.5, maybe 32,000 if you were lucky. LLMs hallucinated constantly. The solution? RAG. Break documents into chunks, embed them in vector databases, retrieve relevant pieces, and augment the prompt.
It was elegant. It was necessary. It worked.
But then 2024–2025 happened.
Google announced Gemini 1.5 Pro with its 1 million token window in February 2024. The AI community collectively gasped. "Lost in the Middle" was supposed to be unsolvable — the phenomenon where models forgot information buried deep in long contexts. Google claimed they'd solved it.
And you know what? They actually did.
According to Google's own documentation:
"Even though the models can take in more and more context, much of the conventional wisdom about using large language models assumes this inherent limitation on the model, which as of 2024, is no longer the case. Some common strategies to handle the limitation of small context windows included: arbitrarily dropping old messages, summarizing content, using RAG with semantic search."
Those "strategies" they're referring to? That's your entire RAG architecture. Past tense.
By late 2025, Llama 4 Scout pushed context to 10 million tokens. The arms race was over before most engineers realized it had started.
The Five Nails in RAG's Coffin
Let's be brutally honest about why traditional RAG is dying:
1. Long Context Windows Made Retrieval Optional
According to a recent Medium article analyzing the RAG vs. long-context debate:
"The argument goes like this: Why bother building complex pipelines to search for data (RAG) when you can just paste an entire library into the prompt of Gemini 3 or GPT-5.2?"
It's a fair question. Traditional RAG requires:
- Vector database setup and maintenance
- Chunking strategy optimization
- Embedding model selection and fine-tuning
- Retrieval precision tuning
- Reranking pipelines
- Monitoring for retrieval failures
Long context? Copy. Paste. Done.
The simplicity is seductive. And for many use cases, it actually works better.
2. Citation Accuracy is RAG's Only Real Advantage (And It's Shrinking)
Research comparing RAG and long-context approaches found something striking:
"The RAG approach significantly improves citation accuracy. With the exception of Gemini 1.5-pro that stands out with comparable citation scores in RAG versus long-context set-up, RAG consistently was the winning approach when it came to identifying the precise reference insights."
Translation: RAG is better at saying "this answer came from page 47, paragraph 3."
But here's the uncomfortable truth: Most applications don't need citation-level precision. Customer support chatbots? Executive summaries? Code generation? Users care about correct answers, not footnotes.
And Gemini 1.5 Pro already closing that gap suggests citation accuracy won't be RAG's moat for long.
3. Position Bias Destroyed Long Context's Promise (Sort Of)
One of the most damaging findings for long-context models:
"All three of the models evaluated demonstrated position bias: GPT-4o and Claude3 Opus performed better when insights were at the end of the document, while Gemini-1.5 Pro performed better when insights were at the beginning."
This sounds bad for long context. And it is — kind of.
But here's what nobody talks about: RAG has position bias too. Your retrieval algorithm decides what to surface and in what order. That's also a form of position bias, just hidden behind semantic similarity scores.
The difference? With long context, you know where the bias is. With RAG, it's buried in your embedding model and retrieval logic.
4. The Cost Argument is Crumbling
Yes, long context is expensive. Processing 1 million tokens costs real money — roughly $15 per million input tokens on GPT-4 Turbo as of late 2025.
But RAG isn't free either:
- Vector database hosting ($50–500/month minimum)
- Embedding API calls (every document update, every query)
- Infrastructure to maintain the pipeline
- Engineering time to debug failures
- Reprocessing costs when documents change
According to Google's analysis, with context caching:
"The input / output cost per request with Gemini Flash for example is ~4x less than the standard input / output cost, so if the user chats with their data enough, it becomes a huge cost saving."
For high-traffic applications, long context with caching can actually be cheaper than RAG.
Mind. Blown.
5. Agentic AI Doesn't Need Your RAG Pipeline
This is the real killer. The future isn't static retrieval — it's agentic workflows.
According to Gartner's 2025 prediction:
"By 2028, 33% of enterprise software applications will include agentic AI, up from less than 1% in 2024, enabling 15% of day-to-day work decisions to be made autonomously."
Agentic AI systems don't follow your carefully crafted RAG pipeline. They:
- Decide dynamically what information they need
- Search multiple sources (web, databases, APIs)
- Reason over relationships, not just semantic similarity
- Maintain state across multi-step interactions
Your traditional RAG pipeline? It's a single-purpose tool in a world that needs Swiss Army knives.
Plot Twist: RAG Isn't Dead, It's Evolving
Okay, deep breath. Time for the uncomfortable truth I've been holding back:
RAG isn't dead. But naive, vanilla, 2023-style RAG? That's a corpse.
Here's what's actually happening: RAG is fragmenting into specialized, sophisticated variants that bear little resemblance to the simple "retrieve-augment-generate" pipeline of yesterday.
Let me introduce you to RAG 2.0.
The New RAG Taxonomy
1. Agentic RAG: RAG With a Brain
Traditional RAG is dumb. It retrieves based on your query and hopes for the best. If the retrieval fails? Too bad.
Agentic RAG is different. According to recent technical analysis:
"Agentic RAG is not a pipeline; it is a loop. It is a system where an LLM acts as a reasoning engine, not just a text generator. It has the autonomy to self-correct, iterate, and decide when it has enough information."
What does this look like in practice?
1. User asks a question
2. Agent retrieves documents
3. Agent EVALUATES: "Are these documents relevant?"
- If NO: Rewrite query, try again (with retry limit)
- If YES: Continue to generation
4. Agent generates answer
5. Agent CHECKS: "Is this answer supported by the documents?"
- If NO: Loop back to step 2
- If YES: Return answer to userThis isn't your grandfather's RAG. It's a self-correcting, reasoning system that won't confidently hallucinate nonsense.
Reality check from a practitioner:
"The era of 'Fire and Forget' RAG is over. By 2026, Agentic RAG is the baseline for any serious AI application. It trades a small amount of latency and token cost for a massive increase in reliability."
2. GraphRAG: When Relationships Matter More Than Similarity
Vector similarity is great for "find me documents about machine learning." It's terrible for "show me all the suppliers connected to this vendor who also have contracts with competitors."
Enter GraphRAG. Instead of chunking documents into vectors, it builds knowledge graphs where entities (companies, people, products) are nodes and relationships are edges.
According to analysis from enterprise AI vendors:
"GraphRAG enables reasoning over entity relationships… However, knowledge graph extraction costs 3–5× more than baseline RAG and requires domain-specific tuning."
Is it worth the cost? For complex, multi-hop reasoning tasks — absolutely. For simple question-answering? Probably not.
Use GraphRAG when:
- You need to traverse relationships (supply chains, organizational hierarchies)
- Multi-hop reasoning is critical ("What are compliance risks across all vendor contracts?")
- Audit trails and explainability matter (regulated industries)
Skip GraphRAG when:
- Simple document search suffices
- You can't justify 3–5x higher costs
- Your documents don't have rich entity relationships
3. Self-RAG: The System That Grades Its Own Homework
One of the most promising developments is Self-RAG, which introduces self-critique:
"Self-RAG introduced models that decide when to retrieve information, evaluate the relevance of retrieved content, and critique their own outputs before responding."
The system uses special "reflection tokens" (like ISREL for relevance) to continuously assess its own performance.
The results are stunning: 52% reduction in hallucinations on open-domain QA tasks.
Think about that. More than half of RAG's hallucinations eliminated by teaching the system to doubt itself.
4. CRAG (Corrective RAG): Web Search as Fallback
What happens when your knowledge base doesn't have the answer? Traditional RAG shrugs and hallucinates.
CRAG is smarter:
"Systems like CRAG trigger web searches to correct outdated retrievals… keeps financial or medical advice updated to the minute."
It's RAG with a safety net. Local retrieval fails? Hit the web. Knowledge base outdated? Augment with real-time search.
This is particularly powerful for domains where freshness matters — news, financial data, regulatory compliance.
The Real Story: It's Not RAG vs. Long Context. It's BOTH.
Here's the insight everyone's missing while arguing about RAG's death:
The future isn't choosing between RAG and long context. It's using both intelligently.
Consider this architecture pattern emerging in 2026:
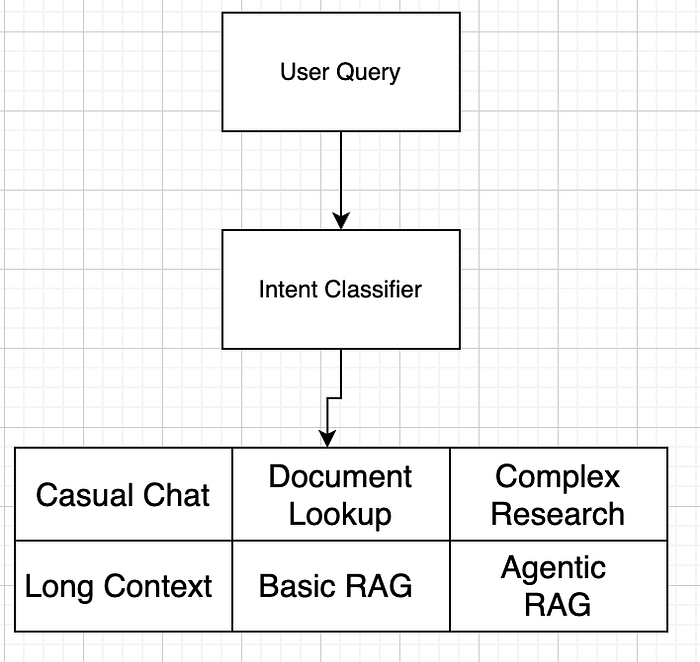
Different queries need different solutions:
- "What did we discuss last meeting?" → Long context (with context caching, entire conversation history)
- "Cite the exact clause about termination" → RAG (for precision and citations)
- "Analyze supply chain risks across vendors" → GraphRAG + Agentic workflows
- "What's the latest regulatory guidance?" → CRAG (RAG + real-time web search)
According to Microsoft's architectural guidance:
"While these techniques [RAG, summarization, filtering] remain valuable in specific scenarios, Gemini's extensive context window invites a more direct approach: providing all relevant information upfront."
Translation: Use the right tool for the right job.
The Hard Truths About Long Context (That Advocates Won't Tell You)
Before you tear down your RAG infrastructure and go all-in on long context, let's talk about the elephants in the room.
1. "Near-Perfect Recall" Isn't Perfect
Google's marketing says Gemini has "near-perfect recall" across 1 million tokens. Microsoft and research from Google themselves reveals a more nuanced reality:
"A main challenge with RAG systems is that they may mislead the user with hallucinated information. Another challenge is that most prior work only considers how relevant the context is to the user query… we really want to know whether it provides enough information for the LLM to answer the question."
Even with long context, LLMs still need sufficient context — not just more context. Dumping 1 million tokens doesn't guarantee the model will synthesize them correctly.
Research from ICLR 2025 found:
"Several standard benchmark datasets contain many instances with insufficient context… Datasets with a higher percentage of sufficient context instances, such as FreshQA, tend to be those where the context is derived from human-curated supporting documents."
Bottom line: Long context is not a magic bullet for hallucinations.
2. Cost Scales Linearly (And Brutally)
Yes, context caching helps. But only if your users reuse the same cached content.
New document every query? You're paying full price:
- 1M tokens input on GPT-4 Turbo: ~$10–15
- 100 queries per day: $1,000–1,500/day = $30,000–45,000/month
Compare to RAG:
- Vector DB: $100–500/month
- Embeddings: $0.13 per 1M tokens (OpenAI ada-002)
- Typical retrieval: 5–10 chunks × 500 tokens = 2,500–5,000 tokens/query
- 100 queries/day: ~$12–25/month for embeddings + $10–30 for LLM generation
For high-volume, diverse queries, RAG can be 100–1000x cheaper.
3. Latency Can Kill User Experience
According to comparative analysis:
"Latency may also be a limitation of the long-context approach if your application requires very fast responses. For instance, Google Gemini 1.5 Flash has a context window of one million tokens and a median first-chunk response time of 0.39 seconds; compare this to Google Gemini 1.5 Pro, which can accept up to two million tokens but the median response time is more than double."
RAG with optimized retrieval? 50–150ms for retrieval + generation.
Long context with 1M tokens? 800ms-2+ seconds for first response.
For interactive applications, that difference is the boundary between "feels instant" and "why is this so slow?"
4. Model Providers Can Change Pricing Overnight
Your entire cost analysis based on current token pricing? It's fantasy.
In 2024–2025, we saw:
- Massive price drops (OpenAI cut GPT-4 pricing by 50%)
- Introduction of tiered pricing
- Caching mechanisms with different economics
If you build your architecture around current long-context pricing, you're one pricing change away from a budget crisis.
RAG's costs are more predictable: vector databases have stable pricing, and embeddings are a commodity.
The Sufficient Context Problem (Or: Why RAG Still Matters)
Here's something fascinating that nobody talks about: having all the information doesn't mean the LLM will use it correctly.
Research published at ICLR 2025 introduced the concept of "sufficient context":
"It's possible to know when an LLM has enough information to provide a correct answer to a question… hallucinations in RAG systems may be due to insufficient context."
They found that even when all relevant information is in the context window:
- Models still hallucinate if the information isn't clearly structured
- Distant information gets "forgotten" (position bias)
- Contradictory information confuses the model
RAG's superpower? It surfaces the most relevant information first.
With RAG, you're not hoping the model finds the needle in a 1-million-token haystack. You're handing it the needle.
Real-World Battle: When RAG Wins, When Long Context Wins
Let's get practical. Here are actual use cases with clear winners:
Long Context WINS:
Conversational memory in chatbots
- Store entire conversation history (thousands of messages)
- No retrieval lag, perfect context continuity
- Example: Claude remembering your coding style across 50 messages
Document summarization
- Feed entire 300-page report directly
- No chunk boundaries, holistic understanding
- Example: "Summarize this annual report highlighting risks"
Code repository analysis
- Entire codebase (up to 50,000 lines) in context
- Cross-file reasoning, refactoring suggestions
- Example: GitHub Copilot analyzing your full project structure
Legal document review (small-medium docs)
- Feed contract once, ask multiple questions
- Context caching makes subsequent queries cheap
- Example: "Review this 100-page contract for liability clauses"
RAG WINS:
Large, dynamic knowledge bases
- Corporate wikis, documentation sites, support tickets
- Content updates frequently, can't re-cache constantly
- Example: Customer support bot across 10,000 help articles
Precise citation requirements
- Legal, compliance, scientific research applications
- "This claim is supported by [Source X, Page Y]"
- Example: Regulatory compliance chatbot citing specific rules
Cost-sensitive, high-volume queries
- Thousands of users, millions of queries
- Can't afford full context for each query
- Example: Public-facing chatbot on SaaS product
Multi-source federation
- Data across databases, APIs, file systems
- Can't dump everything into one prompt
- Example: Enterprise search across Confluence, Jira, Slack, Google Drive
Hybrid (RAG + Long Context) WINS:
Complex research workflows
- Initial broad retrieval (RAG), then deep analysis (long context)
- Example: "Research AI safety papers, then analyze trends"
Agentic workflows with tool use
- Agent decides when to retrieve, when to use full context
- Example: AI coding assistant that searches docs, then generates code
Adaptive context management
- Start with RAG, fall back to long context for complex queries
- Example: Chatbot that escalates to full document review if initial retrieval fails
The 2026 Playbook: What To Actually Build
Stop debating. Start building. Here's your decision framework:
Choose Long Context (No RAG) When:
- Your entire knowledge base fits in 500K-1M tokens
- Content rarely changes (context caching is economical)
- Users have long, stateful conversations
- You need holistic document understanding (summaries, analysis)
- You have budget for higher token costs
- Latency requirements are flexible (2–5 seconds acceptable)
Cost estimate: $5,000–20,000/month for moderate usage
Choose Traditional RAG When:
- Knowledge base exceeds 2M tokens significantly
- Content updates frequently (can't rely on caching)
- Queries are short, independent requests
- You need precise citations and provenance
- Budget is tight (<$1,000/month)
- Latency must be under 500ms
Cost estimate: $500–3,000/month for moderate usage
Choose Agentic RAG When:
- Accuracy is critical (healthcare, legal, finance)
- Queries require multi-step reasoning
- Retrieval quality varies (need self-correction loops)
- You can tolerate 2–10 seconds latency
- Budget allows for 3–5x traditional RAG costs
Cost estimate: $2,000–10,000/month for moderate usage
Choose GraphRAG When:
- Your domain has rich entity relationships
- Multi-hop reasoning is essential
- You need explainable, auditable reasoning
- You can afford 3–5x RAG costs for higher quality
- Your team can maintain knowledge graphs
Cost estimate: $5,000–25,000/month (includes graph maintenance)
Choose Hybrid (RAG + Long Context) When:
- Different query types need different approaches
- You want to optimize cost and quality simultaneously
- Your application has tiered user experiences
- You're building agentic workflows
- Requirements are complex and evolving
Cost estimate: Varies widely; budget $3,000–15,000/month
The Uncomfortable Truth About Context Windows
Let me share something controversial that will upset both camps:
Neither RAG nor long context solves the fundamental problem: LLMs don't truly understand your data.
They pattern-match. They correlate. They generate plausible-sounding text based on statistical relationships.
Whether you:
- Feed 1 million tokens of context (long context approach), or
- Retrieve the 5 most similar chunks (RAG approach)
…you're still trusting a probabilistic model to synthesize information correctly.
The real innovations in 2026 aren't about retrieval vs. context — they're about:
- Verification layers: Systems that check answers against sources
- Reasoning traces: Showing how the answer was derived
- Confidence scoring: Admitting "I don't know" when uncertain
- Human-in-the-loop: Escalating to people for critical decisions
According to industry predictions for 2026–2030:
"Between 2026–2030, RAG will undergo a fundamental architectural shift — from a retrieval pipeline bolted onto LLMs to an autonomous knowledge runtime that orchestrates retrieval, reasoning, verification, and governance as unified operations."
Translation: The future isn't RAG vs. long context. It's knowledge systems with AI, not AI with knowledge.
What Actually Matters in 2026
While everyone argues about retrieval methods, here's what will actually determine success:
1. Data Quality > Retrieval Method
Garbage in, garbage out. Doesn't matter if you have GraphRAG with agentic workflows if your knowledge base is:
- Outdated
- Contradictory
- Poorly structured
- Missing key information
Fix your data before you fix your architecture.
2. Evaluation > Innovation
You know what separates successful AI teams from failing ones? Rigorous evaluation.
Not vibes. Not demos. Real metrics:
- Answer accuracy (measured against ground truth)
- Citation precision (do sources actually support claims?)
- Latency (p50, p95, p99 percentiles)
- Cost per query (fully loaded, not just LLM tokens)
- User satisfaction (NPS, retention, task completion)
Build a proper evaluation harness, or you're flying blind.
3. Iteration Speed > Perfect Architecture
The worst decision is no decision.
Start with the simplest thing that could work:
- For most teams: Basic RAG (vector DB + embedding + generation)
- Measure everything
- Iterate based on failures
Don't build GraphRAG with agentic workflows on day one. You'll spend 6 months building something nobody needs.
Build fast, measure accurately, improve incrementally.
The Real Future: Contextual Memory and Knowledge Runtimes
Want to know what's actually going to replace traditional RAG? It's not long context windows.
It's contextual memory (also called agentic memory or long-context memory).
According to recent industry predictions:
"While RAG won't entirely disappear in 2026, one approach that will likely surpass it in terms of usage for agentic AI is contextual memory… RAG will remain useful for static data, but agentic memory is critical for adaptive assistants and agentic AI workflows that must learn from feedback, maintain state, and adapt over time."
What's contextual memory?
Traditional RAG: "Here's what I found in the documents."
Contextual Memory: "Based on our 50 previous interactions, your typical work patterns, and documents you frequently reference, here's what you probably need."
It's personalization meets retrieval. It's stateful, adaptive, and learns from interaction history.
By 2026, contextual memory will be table stakes for operational AI deployments.
The Provocative Conclusion
So, is RAG dead?
Yes and no.
Vanilla, naive, 2023-style RAG — where you chunk documents, throw them in Pinecone, and call it a day — is absolutely dead. If that's your architecture, you're already behind.
But RAG as a concept — augmenting generation with retrieved information — is more alive than ever. It's just evolved beyond recognition:
- Agentic RAG with self-correction loops
- GraphRAG for relationship-aware reasoning
- Hybrid systems that blend retrieval and long context
- Contextual memory that learns from interactions
The real insight? Stop thinking in terms of "RAG vs. long context" and start thinking in terms of knowledge systems.
Your job in 2026 isn't to choose between retrieval architectures. It's to build systems that:
- Provide accurate, verifiable answers
- Admit ignorance when uncertain
- Learn from feedback and improve
- Cost-effectively scale to your use case
- Maintain governance and auditability
Whether that uses RAG, long context, or some hybrid is implementation detail.
The Hard Truths:
- Long context is expensive (but getting cheaper)
- RAG is complex (but necessary for many use cases)
- Agentic systems are slow (but dramatically more accurate)
- GraphRAG costs 3–5x traditional RAG (but worth it for complex reasoning)
What To Do Tomorrow:
- Audit your current system
- What's the actual retrieval precision?
- How often do users get wrong answers?
- What's the real cost per query?
- Run experiments
- Test long context on a subset of queries
- Implement basic agentic self-correction
- Measure everything
- Stop optimizing the wrong thing
- Perfect retrieval precision doesn't matter if answers are wrong
- Low latency doesn't matter if users don't trust results
- Cheap doesn't matter if accuracy is terrible
- Build for your actual use case
- Don't cargo-cult architectures from blog posts
- Test with real data, real queries, real users
- Iterate based on actual failures, not theoretical concerns
The Meta-Lesson
The debate about "RAG is dead" is a distraction.
The real story of 2026 isn't that one approach won. It's that we're finally moving beyond simplistic architectures toward sophisticated knowledge systems that use whatever techniques work.
The best teams aren't arguing about RAG vs. long context. They're building, measuring, and iterating.
So stop reading blog posts (yes, including this one) and start experimenting.
The technology is here. The tools are available. The question is: What are you going to build?
Further Reading
If you want to go deeper (with actual implementations, not just theory), explore:
- LangGraph: Framework for building agentic RAG systems
- Neo4j + NeoConverse: Hands-on GraphRAG experimentation
- Microsoft's Azure AI Foundry: Enterprise-grade hybrid search
- Google's Gemini API documentation: Long context best practices
- Pinecone/Weaviate: RAG-specific vector database optimizations
And remember: The best architecture is the one that solves your actual problem at acceptable cost and latency.
Everything else is noise.
This article was intentionally controversial to provoke thought and discussion. The field is moving fast — what's cutting-edge today may be obsolete in 6 months. Stay curious, stay skeptical, and always test your assumptions.
Have thoughts? Disagree violently? Built something that proves me wrong? Good. That's the point. The comment section is below.