

A deep dive into architecture, design decisions, and lessons learned from building a configuration-driven streaming platform that currently powers 300+ production pipelines for a wide variety of use cases across teams.
Every product team eventually needs real-time pipelines — for our Marvel Platform's Journey based customer communications, Feed Personalisation, Event Forwarding on 3rd party platforms, Analytics, cohort based A/B experimentation Platform. And every time, the same pattern repeats: an engineer writes a custom Flink or Spark job, handles state management and failure recovery, sets up Kubernetes deployments and monitoring, and carries the on-call burden. Weeks of work. Repeated endlessly. We decided to break this cycle.
We built Pulse — a no-code, configuration-driven streaming platform on top of Apache Flink. Instead of writing code for each pipeline, teams define their pipeline as a JSON DAG (Directed Acyclic Graph) with nodes and edges. Pulse parses that config, dynamically loads operators via reflection, wires them into a Flink job graph, and deploys it to Kubernetes via ArgoCD — all automatically.
Today, Pulse runs 300+ production pipelines across six products — Eloelo, StoryTV, MasterEdu, Connecto, Voxy & StoryMax. This article walks through the architecture, the design decisions, and what we learned along the way.
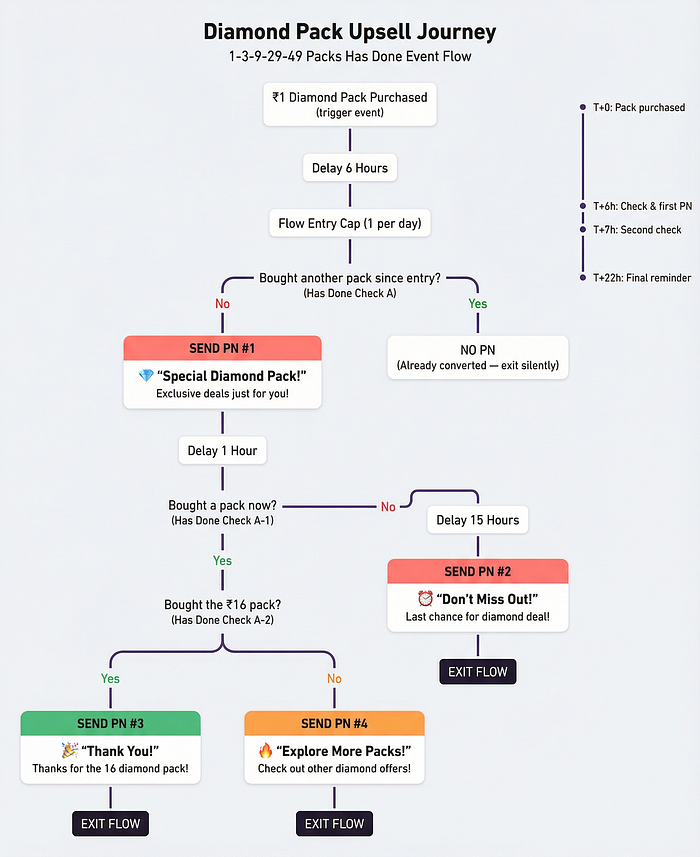
A few Journey based Use Cases on Pulse
- Welcome Message Journey: When a new user opens the app for the first time today, wait 5 minutes. If they haven't watched anything yet, send a push notification recommending a trending show
- Cart Abandonment: User adds items to cart but doesn't checkout in 30 minutes. If they're a high-intent user (visited the store 10+ times this week), send a 10% off coupon via WhatsApp
- Churn Win-Back: If a paying user hasn't opened the app in 7 days but was active the week before, send a comeback offer. Different offers for free users vs paid users vs VIP users
Feature Store Use Cases (Personalisation & ML)
- Personalised Feed Ranking: For every user, maintain a running count of how many episodes they've started in the last 60 days, how many live rooms they've entered in the last 7 days, and how many diamonds they've purchased in the last 30 days. The recommendation engine reads these numbers to decide what to show on their home screen
- Real-Time User Profile: Every time a user does anything — watches, chats, purchases, follows — update their profile in Redis within seconds. Fields like last_active, favourite_category, total_watch_time_7d, is_paid_user. The app reads this profile to personalize everything
- New User Detection: Track whether a user has ever logged in before, looking back 90 days. If this is truly their first login, tag them as a 'new user' so downstream journeys and campaigns can treat them differently
- Engagement Scoring: Count chat messages sent in the last 7 days, calls made in the last 14 days, and app opens today. Feed these numbers into the ML model that predicts churn risk
All of the above are being powered by Pulse.
Architecture Overview
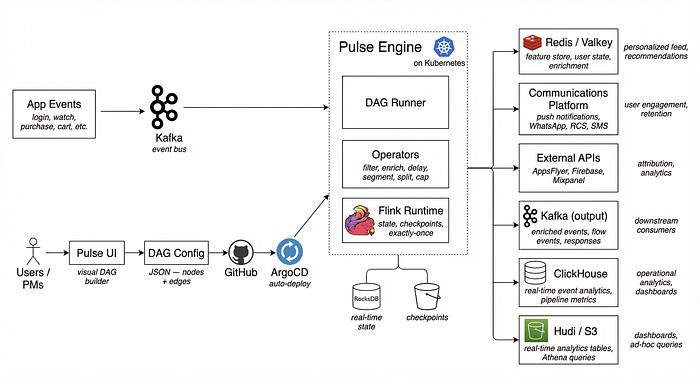
Components:
- Pulse Engine (on Kubernetes) — The core platform that parses DAG configs and executes them as Flink streaming jobs
- DAG Runner — Parses the JSON config, sorts nodes, loads operators via reflection, and wires the Flink job graph
- Pulse UI — Visual DAG builder where PMs and engineers design pipelines using drag-and-drop (planned)
- RocksDB — Embedded key-value store on each TaskManager for blazing-fast per-user state (rolling windows, counters, timers) checkpointed periodically on S3 for crash recovery
- Communications — Delivery channel for push notifications, WhatsApp, RCS, and SMS via internal notification services and 3rd party vendors
- ClickHouse — Real-time event analytics database for Journey Analytics
Let's have a look at a sample DAG on Pulse
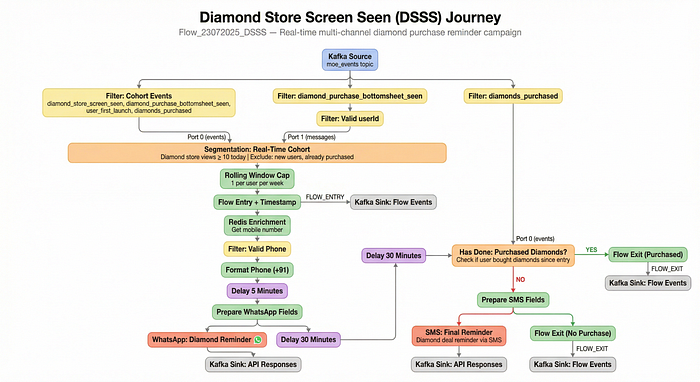
As you can see the data flows down the graph from one node to the other where edges show the direction of the data flow
The Core Insight: Every Pipeline is a DAG
Before writing a single line of code, we studied the use cases our Business teams had come up with over time. Every one followed the same pattern:
- Read from Kafka
- Transform the data — filter, enrich, delay, split, aggregate
- Write to Kafka, Redis, or an external API
This is naturally a Directed Acyclic Graph. The nodes are operators (source, transform, sink), and the edges define how data flows between them. Once we realized this, the design became clear: if we could express any pipeline as a DAG configuration, we could build a generic execution engine that turns that config into a production-grade Streaming job.
The key question was: could we make this generic enough to handle real-world complexity — branching, multi-input operators, stateful time-windowed computations, exactly-once delivery — while keeping the configuration simple?
Operator Library
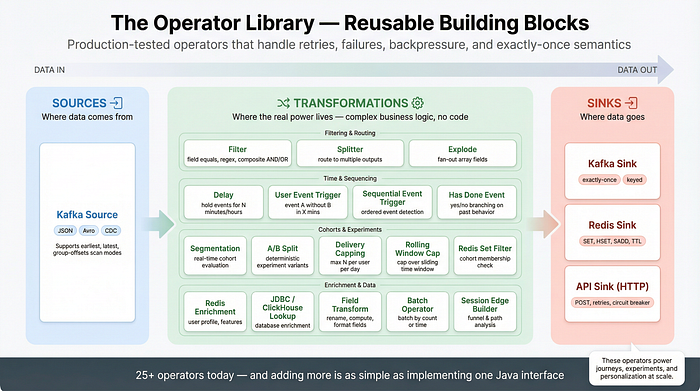
Filtering & Routing
- Filter — Keeps or drops events based on field-level conditions (equals, regex, null checks, composite AND/OR).
- Splitter — Routes events to different downstream branches based on conditional rules, enabling multi-path pipelines.
Time & Behavioural Logic
- Delay — Holds events for a configurable duration (seconds to hours) before releasing them downstream — powers time-based journey logic.
- User Event Trigger — Detects "event A happened but event B didn't within X minutes" patterns — the backbone of cart abandonment and drop-off flows.
- Has Done Event — Evaluates "did this user do X since entering the flow?" with yes/no branching — powers conditional journey paths.
Real-Time Cohorting & Experiments
- Segmentation — Maintains rolling-window event counts per user and evaluates cohort membership in real time on every incoming event.
- Rolling Window Capping — Caps over sliding time windows using Flink state (e.g., max 5 in the last 7 days) — powers per-flow frequency control.
Delivery
- Kafka Sink — Writes processed events to Kafka topics with exactly-once semantics, configurable keys, and compression
- Redis Sink — Writes to Redis using SET, HSET, SADD, ZADD, or list operations with TTL — powers the online feature store
- API Sink — Sends events as HTTP POST requests with retries, circuit breaking, auth headers, and response forwarding to Kafka
A simple DAG Config JSON looks like this:
{
"name": "welcome-message-d0",
"description": "Send welcome push to first-time users 5 min after home_seen",
"version": "1.0",
"runtime": {
"checkpointInterval": 120000,
"stateBackend": "rocksdb",
"restartStrategy": "exponential",
"readSetting": "group-offsets"
},
"nodes": [
{
"id": "source",
"type": "kafka-source",
"config": {
"topic": "events",
"brokers": "broker1:9092,broker2:9092,broker3:9092"
"groupId": "welcome-d0-prod"
}
},
{
"id": "login_filter",
"type": "filter",
"config": {
"where": {
"and": [
{ "field": "event_name", "equals": "login_success" },
{ "field": "userId", "isNotNull": true }
]
}
}
},
{
"id": "wait_5min",
"type": "delay",
"config": {
"duration": "5m",
"keyBy": "userId"
}
},
{
"id": "send_push",
"type": "api-sink",
"config": {
"url": "https://notify.service/send",
"method": "POST",
"body": {
"userId": "{{ userId }}",
"title": "Welcome [[firstName]]!",
"message": "Start exploring these new shows [[top_show_1]], [[top_show_2]]"
}
}
}
],
"edges": [
"source -> login_filter",
"login_filter -> wait_5min",
"wait_5min -> send_push"
]
}Why We Built Pulse on Apache Flink
- Exactly-once semantics (end-to-end): Flink's checkpointing combined with Kafka s transactional producer gives us true end-to-end exactly-once guarantees. No application-level deduplication required. For a notification platform, duplicate sends are simply unacceptable.
- First-class stateful processing: State is a core Flink primitive. Native abstractions like ValueState, MapState, and ListState come with TTL, serialization, and checkpointing built in. Our segmentation logic relies on fine-grained, long-lived per-user counters this is a natural fit for Flink.
- RocksDB-backed local state: Flink integrates directly with RocksDB, enabling low-latency local state access without an external database. State can exceed memory, and incremental checkpoints ensure only changed data is uploaded to S3, keeping checkpoint overhead low at scale.
- Event-time correctness: Flink's event-time model with watermarks and allowed lateness lets us reason about when events actually happened, not when they arrived. This ensures deterministic cohort evaluation even with out-of-order or delayed events.
- True streaming, low latency: Flink processes records one at a time, not in micro-batches. This gives us consistent sub-second latency, which is critical for real-time use cases like in-app nudges and user-triggered notifications.
- Timers and async I/O: Event-time and processing-time timers power delayed actions and sequential triggers. Async I/O enables high-throughput external calls (Redis, APIs) without blocking the main pipeline all deeply integrated into Flink's runtime.
- Safe, stateful upgrades via savepoints: Flink savepoints let us upgrade jobs without data loss or reprocessing. We stop the old job, start the new one from the same state snapshot, and continue seamlessly essential for GitOps-based deployments.
- Kubernetes-native operations: The Flink Kubernetes Operator lets us define jobs declaratively as CRDs. With ArgoCD, deployments are fully GitOps-driven no manual intervention, no ad-hoc scripts, just convergent infrastructure.
We chose the DataStream API instead of Flink SQL
We chose the DataStream API because our operators need fine-grained control over per-user state (custom MapState with hourly bucketing and TTL), timer-based processing (delays, event triggers firing at precise future timestamps), multi-channel I/O routing (dual-input/dual-output operators), and async external calls — none of which Flink SQL can express. SQL is great for relational transformations, but building a generic DAG execution engine with dynamically-loaded, stateful, timer-driven operators requires the imperative control that only DataStream provides.

Why RocksDB as Our State Backend
RocksDB was a natural fit for Pulse's state management needs. Here's why:
- Zero infrastructure overhead. RocksDB is an embedded database — it runs inside the Flink TaskManager JVM process. No external database cluster to provision, manage, or scale. No network hops for state access.
- Sub-millisecond local reads/writes. State lives on the local disk of the TaskManager, making every MapState lookup and update extremely fast — critical when operators evaluate cohort rules or check delivery caps on every event.
- State can exceed memory. Unlike Flink's HashMapStateBackend (which is purely in-memory), RocksDB spills to local SSD via its LSM-tree architecture. Our segmentation operators can maintain 90-day rolling windows per user without worrying about heap pressure.
- Incremental checkpoints. RocksDB's SST file structure enables incremental checkpoints — only changed files are uploaded to S3. For jobs with large state, this reduces checkpoint duration from minutes to seconds.
- Built-in TTL support. StateTtlConfig with cleanupInRocksdbCompactFilter piggybacks state expiry on RocksDB's compaction cycle — expired entries are cleaned up without adding latency to the hot path.
- Managed memory integration. Flink's managed memory controls RocksDB's block cache, write buffer, and index/filter blocks — preventing OOM issues without manual tuning per job.
Configuration is three lines. In our job.yaml, enabling RocksDB state is:
state.backend.incremental: "true"
state.backend.rocksdb.memory.managed: "true"
state.backend.rocksdb.block.cache-size: "256m"No connection strings. No credentials. No cluster management. It just works.
Where RocksDB Falls Short
RocksDB's embedded nature is both its strength and its limitation. State is tied to the local TaskManager — meaning:
- Rescaling is expensive — changing parallelism requires redistributing state across TaskManagers via checkpoint restore.
- Local disk is the ceiling — while disk-spilling helps, a single TaskManager's SSD is still the upper bound. For operators maintaining months of state across millions of users, this becomes a constraint.
- Checkpoint size grows linearly — as state grows, even incremental checkpoints will start taking longer, increasing recovery time on failures.
Future: Disaggregated & Distributed State
We're exploring two directions to address these limits as our scale grows:
- ForSt (Flink on Object Storage) — Ververica's ForSt project is an LSM-tree key-value store built on top of RocksDB, designed for disaggregated state management. The key innovation: SST files live on remote storage (S3, HDFS) instead of local disk. This decouples state size from local disk capacity and makes checkpointing significantly lighter — since the data is already on remote storage, checkpoints become metadata operations rather than full data uploads. ForSt is a drop-in replacement for RocksDB in Flink and is the direction the Flink community is heading for cloud-native state management.
- External state backends (ScyllaDB / Cassandra) — For operators with very large state (e.g., 90-day rolling windows across hundreds of millions of users), we want to experiment with externalizing state to a distributed database like ScyllaDB or Cassandra. The trade-off is higher per-access latency (network vs. local SSD) in exchange for virtually unlimited state size, independent scaling of compute and storage, and the ability to query state externally for debugging and analytics. This would require implementing a custom Flink StateBackend that translates Flink's MapState/ValueState operations into distributed database reads and writes — non-trivial, but the payoff at scale is significant.
Challenges we faced
The Cold Start Problem
When a new pipeline with stateful operators (like Segmentation) is deployed for the first time, its RocksDB state is empty — it has no historical context. A cohort rule like "users who logged in 10+ times in the last 7 days" would match nobody on day one, because the pipeline has only been running for minutes.
Our solution: State Bootstrap via K8s Init Containers. We built a SegmentationStateBootstrap job that:
- Runs as a Kubernetes batch job (init container) before the streaming job starts
- Queries ClickHouse for historical event data
- Aggregates events into the same userId → actionName → hourlyBucket → count structure that the streaming operator uses
- Writes this pre-computed state into a Flink Savepoint using Flink's State Processor API (KeyedStateBootstrapFunction)
- Saves the Savepoint to S3
The streaming job then starts from this savepoint with fully backfilled state — as if it had been running for 90 days. Users qualify for cohorts from minute one.
Operator UID Instability
Early on, we hit a painful issue: every time someone added, removed, or reordered a node in a DAG config, the job would fail on restart.
The reason: Flink assigns internal operator IDs based on the position of operators in the job graph. When the graph changes — even if you just add a new filter node upstream — the auto-generated IDs shift, and Flink can't map the existing checkpoint state to the new graph. The job throws a StateMigrationException and refuses to start.
Our solution: Fixed Operator UIDs. We modified the DAG engine to assign a deterministic, stable uid() to every operator based on the node's name field from the config:
dataStream
.keyBy(...)
.process(new SegmentationFunction(config))
.uid("node_" + nodeConfig.getName())
.name(nodeConfig.getNodeName());Since name is a user-defined stable identifier (like "segmentation_node" or "delay_5min"), it never changes when other nodes are added or removed. Flink can now map checkpoint state correctly across DAG edits. This was a subtle but critical fix — without it, any config change would require discarding all accumulated state and starting from scratch.
Conclusion
Building a no-code streaming platform on Flink was one of the highest-leverage engineering investments we've made. What started as a way to stop rewriting the same Flink jobs turned into something much bigger — a shared infrastructure layer that fundamentally changed how fast our teams can move.
The numbers speak for themselves: 300+ production pipelines, sub-second latency, and new pipelines shipping in hours instead of days. But the real impact isn't in the metrics — it's in what became possible once the barrier to real-time data dropped to zero.
We're still early. The visual DAG builder UI, Hudi sink for real-time analytics tables, ForSt for disaggregated state, and in-app nudges via Pusher are all on the roadmap. But the foundation is solid, the pattern is proven, and the platform pays for itself many times over with every new pipeline that ships as a JSON config instead of a custom engineering project.