
Last month I wanted to understand how REST Catalog worked with Spark and Trino. That learning exercise turned into Floe.
the problem
Iceberg solved the metadata problem. Snapshots, atomic commits, schema evolution. That part works.
Maintenance is different. Every table needs compaction, snapshot expiration, orphan cleanup. The APIs exist. SparkActions, Trino's ALTER TABLE EXECUTE. Running maintenance on one table is easy.
Running it across hundreds of tables with different ingestion patterns? That's where it gets messy.
how teams would handle this
They start with scripts (I know I did). Then Airflow DAGs. Then more DAGs. Eventually someone asks why the streaming tables compact hourly while batch tables run weekly. Someone else asks which DAG owns which table. Then the person who wrote the original scripts leaves.
The execution layer is fine. Orchestration based on table characteristics is what is missing.
the missing piece
You have a catalog, you have an engine that reads and writes data. What you need is a service that sits outside of those that allows you to declare something like this:
- Tables matching
warehouse.hourly.*compact every X hours - Tables matching
warehouse.daily.*compact daily - All tables expire snapshots older than 7 days
warehouse.production.orderscould have its own custom retention policy.
This would allow the Iceberg table owner to declare this once and then their maintenance is handled. In my experience in large organizations, the more self serving things can be made, the easier it is for Platform teams to exist and thrive. So, giving them this API to declare how their table should be maintained, can go a long way.
so, what does Floe do
At a super high level, Floe looks like this.
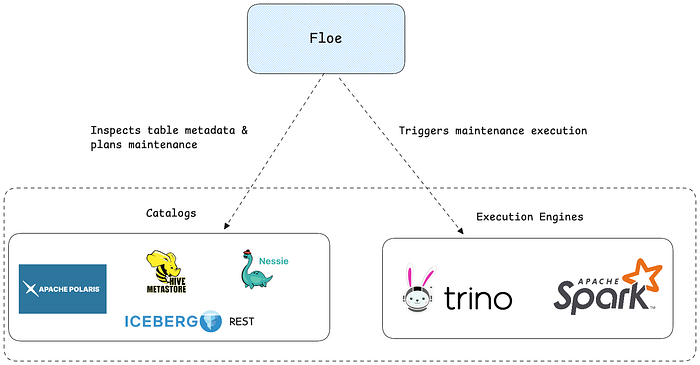
It's policy-based maintenance system. You define policies with glob patterns. Floe matches tables from your catalog and runs maintenance via Spark or Trino. I began this with just the REST Catalog, but then I remembered that the Hive Metastore is still alive and well in most places. Then added Polaris, and then Nessie too.
A policy looks like this:
curl -s -X POST "http://localhost:9091/api/v1/policies" \
-H "Content-Type: application/json" \
-d '{
"name": "orders-compaction-policy",
"description": "Compact small files in orders table",
"enabled": true,
"tablePattern": "demo.test.*",
"priority": 100,
"rewriteDataFiles": {
"strategy": "BINPACK",
"targetFileSizeBytes": 536870912
},
"rewriteDataFilesSchedule": {
"cronExpression": "0 0 */4 * * ?",
"enabled": true
}
}'Tables matching demo.test.* compact every 4 hours. If a table matches multiple patterns, higher priority wins.
Most teams will already have an orchestrator. Great. Skip the schedules and trigger via API:
curl -X POST http://localhost:9091/api/v1/maintenance/trigger \
-H "Content-Type: application/json" \
-d '{
"catalog": "demo",
"namespace": "test",
"table": "orders",
"policyName": "orders-compaction-policy"
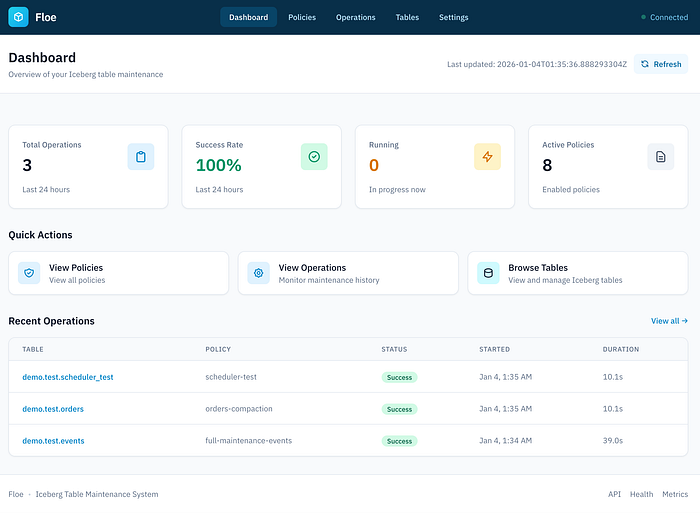
}'There's also a minimal UI that shows you a Dashboard of everything, the Operations you've executed, the Policies you created, the Tables that it can read from the catalog, and a Settings page to inform you of the current configuration.
try it out
Floe supports all of these catalogs: Iceberg REST, Hive Metastore, Nessie, Polaris. And Spark and Trino for execution. Get started with:
git clone https://github.com/nssalian/floe.git
cd floe
make startYou can run additional examples as well. These are full setups with the respective catalogs. Don't forget to run a make clean before you start any of these so you don't have port collisions.
make example-rest # Iceberg REST Catalog
make example-nessie # Project Nessie
make example-polaris # Apache Polaris
make example-hms # Hive Metastore
# Swap execution engine by running make example-<catalog>-trino default is SparkThey will bring up the containers, run a Spark job to create a few Iceberg tables with data, and then add some sample policies. Execute the maintenance operations that are prompted. There's a scheduler-test policy that will run every minute too. You can delete the namesake policy if you want it to stop.
Open http://localhost:9091 and explore the tables, the policies, and the operations.
If you'd like to learn more, head over to:
GitHub: https://github.com/nssalian/floe Docs: https://nssalian.github.io/floe
Let me know what you think. Thanks for reading.