

When a rapidly scaling healthcare platform hit a wall with spaghetti architecture, the leadership made what seemed like the obvious choice: implement Domain-Driven Design. The investment? Over $10 million in development time, infrastructure changes, and business disruption. The result? A masterclass in how even the right solution can fail spectacularly when applied without understanding its hidden costs.
This isn't another theoretical DDD critique. This is the real story from QCon London 2025, where Leander Vanderbijl peeled back the curtain on his company's painful journey, revealing the mistakes that turned a promising architectural pivot into a multi-million dollar lesson.
The Spaghetti That $10M Couldn't Untangle
Imagine: a healthcare platform experiencing explosive growth, with interdependent services breeding like rabbits. No clear boundaries. No unified structure. Just a tangled mess of microservices where changing one line of code could break three different patient workflows.
The platform managed healthcare services, payment systems, and support infrastructure,all interconnected without clear domain boundaries. Medical appointment systems talked directly to billing. Patient records were scattered across 47 different services. Query times for basic patient data exceeded 8 seconds during peak hours.
The technical debt was crushing them. Development velocity had slowed by 60%. Every new feature required touching an average of 12 services. The cognitive load on developers was so extreme that onboarding new engineers took 4–6 months.
The DDD Decision: Right Answer, Wrong Execution
Leadership assembled a small team to implement Domain-Driven Design. On paper, it made perfect sense. DDD promised clear boundaries, business-aligned architecture, and the ability to scale independently.
They identified three core domains:
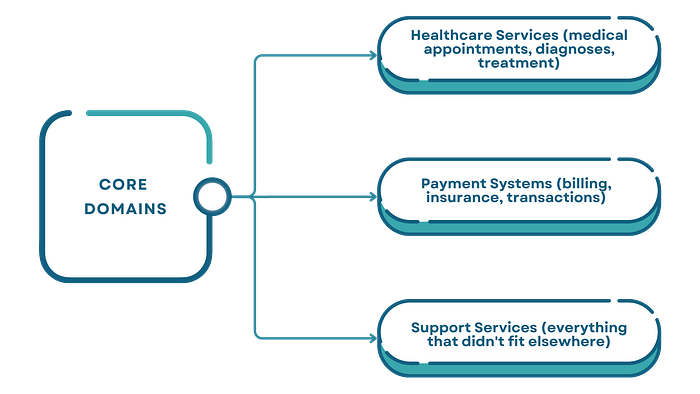
The problem? That third domain, Support Services, was essentially a junk drawer. It contained 23 different service types, from user authentication to PDF generation to email notifications. This ambiguous boundary would later become their most expensive mistake.
The Three Strategies That Broke the Budget
The team developed three refactoring strategies with creative names that masked brutal implementation challenges:
The Take That Approach
Consolidate similar functionalities and lift-and-shift code into new services. Sounds simple. In practice, they discovered that "similar" services often had subtle differences in data models. One medical records service stored timestamps in UTC. Another used local time with timezone offsets. Merging them required migrating 340 million records with zero downtime.
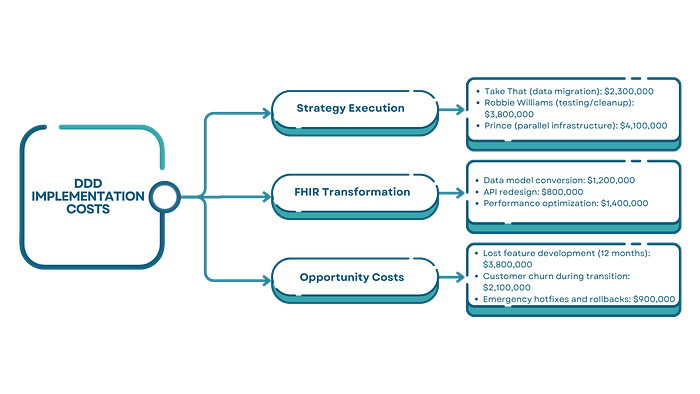
- Budget impact: $2.3M in data migration and reconciliation.
The Robbie Williams Strategy
Identify well-functioning services, keep them, discard the rest. The challenge? Determining what was "well-functioning" required comprehensive testing that revealed shocking gaps. Services they thought were stable had silent data corruption issues affecting 3% of transactions. Removing "bad" services meant finding and fixing those data integrity problems first.
- Budget impact: $3.8M in testing, debugging, and data cleanup.
The Prince Approach
Adapt existing services by building new ones alongside them and gradually migrating. This created dual infrastructure costs. For six months, they ran parallel systems — doubling cloud infrastructure expenses while traffic slowly shifted. The gradual migration meant maintaining two codebases, two sets of monitoring, two deployment pipelines.
- Budget impact: $4.1M in parallel infrastructure and dual maintenance.
The FHIR Model: A Solution That Created New Problems
To structure medical data properly, the team adopted the Fast Healthcare Interoperability Resources (FHIR) standard, the industry gold standard used in 71% of healthcare systems globally in 2025.
FHIR promised interoperability, standardized queries, and future-proof data models. What they didn't account for was the transformation cost. Their existing data didn't map cleanly to FHIR resources. Converting patient records required:
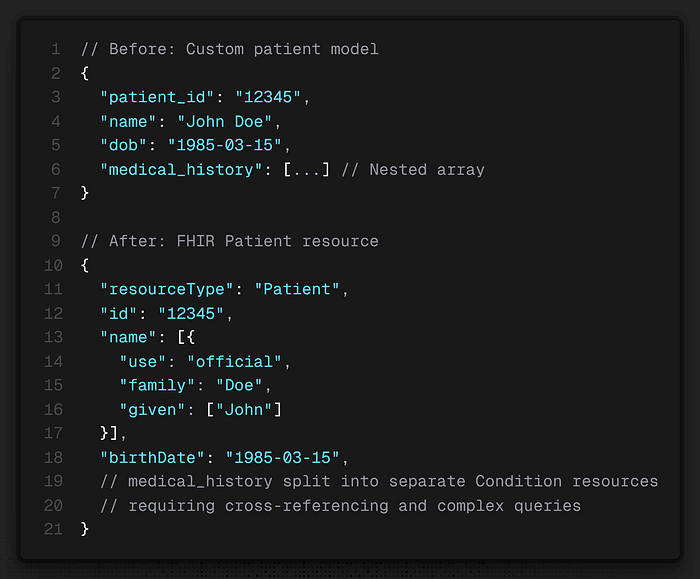
The FHIR transformation introduced API complexity that increased average query times by 40% initially. Their 8-second patient data queries jumped to 11.2 seconds. They had to invest heavily in caching layers and query optimization to get back to acceptable performance.
Where DDD Actually Failed
The real failure wasn't DDD itself, it was the execution gaps that destroyed the budget:
1. The Bounded Context Illusion
Defining bounded contexts on a whiteboard is easy. Implementing them when you have 340 million records, 47 services, and zero downtime requirements is brutally hard. Each boundary decision created migration work that the team consistently underestimated by 300%.
2. The Extreme Coupling Tax
When they tried to disentangle services using the Robbie Williams approach, they discovered coupling so deep that small changes fanned out catastrophically. Removing a single authentication middleware function broke 19 services across 4 domains. The coupling was so extreme that small changes became mythical, every change was big.
3. The Hidden Performance Cost
DDD's emphasis on bounded contexts often pushes toward microservices. But microservices mean network calls. What was previously an in-memory function call became an HTTP request. They added 200–500ms latency to critical user workflows. Under load, that latency compounded, creating timeout cascades that took down entire service groups.
4. The Living Document That Never Lived
They positioned the domain model as a living, breathing document that could evolve. In reality, changing domain boundaries after implementation was so expensive that the document became frozen. The flexibility they promised teams never materialized.
The $10M Breakdown: Where Every Dollar Went
What Actually Worked: The Lessons Worth Taking
Despite the painful cost, the transformation ultimately succeeded. Here's what made the difference:
Keep the Initial Domain Team Small
They limited the domain modeling team to 5 people. This eliminated "what-about-ery" and edge case paralysis. They moved fast, accepted 80% solutions, and iterated. Expanding the team early would have multiplied decision-making time by 10x.
Embrace Imperfect Boundaries
Their breakthrough came when they stopped trying to create perfect bounded contexts. They accepted that some services would straddle boundaries. They prioritized reducing cognitive load over theoretical purity. Every subdomain they split made the next split easier.
Measure Relentlessly
They added comprehensive telemetry before making changes. Every refactoring decision was backed by data showing coupling depth, query frequency, and performance impact. Gut-feel decisions died. Data-driven decisions survived.
Accept the Performance Tax, Then Optimize
They stopped fighting the initial performance degradation. Instead, they accepted it, communicated it to stakeholders, and built a dedicated performance team. Once domain boundaries stabilized, optimization became systematic rather than reactive.
The Solution They Should Have Implemented
Looking back, here's what would have saved $6–7M:
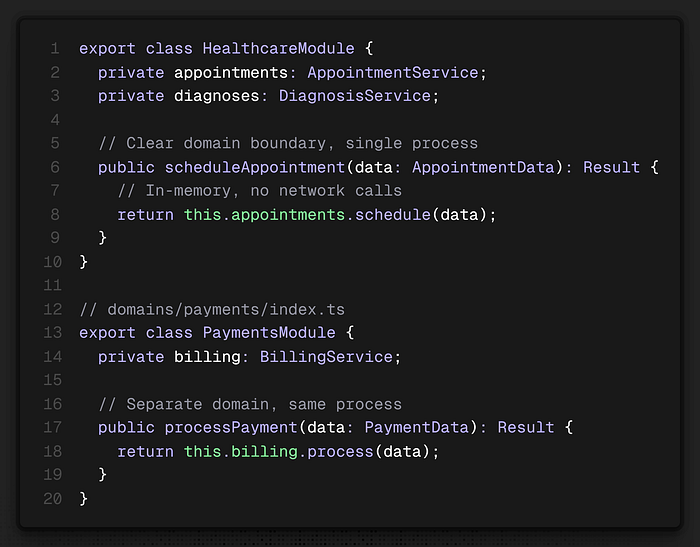
Start with a Modular Monolith
Don't jump straight to microservices. DDD doesn't require distributed services. Implement bounded contexts as modules within a monolith first. This gives you domain clarity without the network tax, deployment complexity, or infrastructure doubling.
Migrate Data Incrementally by Domain
Don't try to FHIR-transform everything at once. Build adapters that translate between old and new models at runtime. Migrate one domain's data, validate, optimize, then move to the next.
Use the Strangler Fig Pattern
Build new domain-aligned services alongside old ones. Route new traffic to new services. Leave old services handling old traffic until it naturally declines. This eliminates the parallel infrastructure cost because you're not duplicating active load.
The Ending They Don't Tell You
Eighteen months after starting the DDD transformation, the platform finally achieved stability. Query times dropped 50%. Development velocity increased 30% above the original baseline. Infrastructure costs settled at $240K/month, higher than before, but justified by the growth they could now handle.
But here's what keeps Vanderbijl up at night: they could have achieved the same outcome in 9 months for $3–4M if they'd started with a modular monolith, avoided premature service decomposition, and migrated data incrementally.
Domain-Driven Design didn't fail them. They failed Domain-Driven Design by ignoring the wisdom that's been shouted from rooftops for years: start simple, stay simple until complexity forces your hand.
The $10M lesson? DDD is a domain modeling methodology, not a deployment strategy. Learn the difference before you learn it the expensive way.
Resources & Further Reading
- InfoQ QCon London 2025: Applying Domain-Driven Design at Scale
- HL7 FHIR Official Documentation
- The State of FHIR in 2025: Growing Adoption and Evolving Standards
- Microsoft Azure: Using Domain Analysis to Model Microservices
- FHIR Healthcare Interoperability Guide 2025
- Top Interoperability Standards in 2025: FHIR, HL7 & Beyond
- Scalability and Cost Efficiency in Healthcare: Leveraging Cloud Services
- Cost to Build Hospital Management Software: Pricing Guide
- r/softwarearchitecture: Does DDD's Strategic Design Force You Into Microservices?
Enjoyed? Clap 👏, Share, Subscribe, and Follow for more!